This blog explores how we can use AI capabilities to automate our test case generation tasks for web applications and APIs, focusing on AI-assisted Test Case Generation for Web & API. Before diving into this topic, let’s first understand why automating test case generation is important. But before that, let’s clarify what a test case is: a test case is a set of steps or conditions used by a tester or developer to verify and validate whether a software application meets customer and business requirements. Now that we understand what a test case is, let’s explore why we create them.
What is the need for test case creation?
To ensure quality: Test cases help identify defects and ensure the software meets requirements.
To improve efficiency: Well-structured test cases streamline the testing process.
To facilitate regression testing: You can reuse test cases to verify that new changes haven’t introduced defects.
To improve communication: Test cases serve as a common language between developers and testers.
To measure test coverage: Test cases help assess the extent to which the software has been tested.
When it comes to manual test case creation some limitations, disadvantages, or challenges impact the efficiency and effectiveness of the testing process such as:
What are the limitations of manual test case generation?
Time-Consuming: Manual test case writing is a time-consuming process as each test case requires detailed planning and documentation to ensure the coverage of requirements and expected output.
Resource Intensive: Creating manual test cases requires significant resources and skilled personnel. Testers must thoroughly understand the application and its related requirements to write effective test cases. This process demands a substantial allocation of human resources, which could be better utilized in other critical areas.
Human Error: Any task that needs human interactions is prone to error because that is a human tendency and manual test case creation is no exception. Mistakes can occur in documenting the steps, and expected results, or even in understanding the requirements. Which could result in inaccurate test cases that lead to undetected bugs and defects.
Expertise Dependency: Creating high-quality test cases that cover all the requirements and results into high test coverage requires a certain level of expertise and domain knowledge. This creates a limitation especially if those individuals are unavailable or if there is a high turnover rate.
These are just some of the challenges that I have mentioned but there could be more. Comment down your thoughts on this one. If you have any other challenges then you can share them in the comment section. Now that we have understood why we create a test case and what value it adds in testing along with the limitations for manual test case generation let’s see what are the benefits of automating this test case generation process.
Benefits of automated test case generation:
Efficiency and Speed: Automated test case generation significantly improves the efficiency and speed of test case writing. As tools and algorithms drive the process instead of manual efforts, it creates test cases faster and quickly updates them whenever there are changes in the application, ensuring that testing keeps pace with development.
Increased Test Coverage: Automated test case generation eliminates or reduces the chances of compromising the test coverage. This process generates a wide range of test cases, including those that manual testing might overlook. By covering various scenarios, such as edge cases, it ensures thorough testing.
Accuracy and Consistency: Automating test case generation ensures accurate and consistent creation of test cases every time. This consistency is crucial for maintaining the integrity of the testing process and applying the same standards across all test cases.
Improved Collaboration: By standardizing the test case generation process, automated test case generation promotes improved collaboration among cross-functional teams. It ensures that all team members, including developers, testers, and business analysts, are on the same page.
Again, these are just a few advantages that I have listed down. You can share more in the comment section and let me know what the limitations of automated test case generation are as well.
Before we move ahead it is essential to understand what is AI and how it works. This understanding of AI will help us to design and build our algorithms and tools to get the desired output.
What is AI?
AI (Artificial Intelligence) simulates human intelligence in machines, programming them to think, learn, and make decisions. AI systems mimic cognitive functions such as learning, reasoning, problem-solving, perception, and language understanding.
How does AI work?
AI applications work based on a combination of algorithms, computational models, and large datasets. We divide this process into several steps as follows.
1. Data Collection and Preparation:
Data Collection: AI system requires vast amounts of data to learn from. You can collect this data from various sources such as sensors, databases, and user interactions.
Data Preparation: We clean, organize, and format the collected data to make it suitable for training AI models. This step often involves removing errors, handling missing values, and normalizing the data.
2. Algorithm Selection:
Machine Learning (ML): Algorithms learn from data and improve over time without explicit programming. Examples include decision trees, support vector machines, and neural networks.
Deep Learning: A subset of machine learning that uses neural networks with many layers (deep neural networks) to analyze complex patterns in data. It is particularly effective for tasks such as image and speech recognition.
3. Model Training:
Training: During training, the AI model learns to make predictions or decisions by analyzing the training data. The model adjusts its parameters to minimize errors and improve accuracy.
Validation: We test the model on a separate validation dataset to evaluate its performance and fine-tune its parameters.
4. Model Deployment:
Once the team trains and validates the AI model, they deploy it to perform its intended tasks in a real-world environment. This could involve making predictions, classifying data, or automating processes.
5. Inference and Decision-Making:
Inference is the process of using the trained AI model to make decisions or predictions based on new, unseen data. The AI system applies the learned patterns and knowledge to provide outputs or take actions.
6. Feedback and Iteration:
AI systems continuously improve through feedback loops. By analyzing the outcomes of their decisions and learning from new data, AI models can refine their performance over time. This iterative process helps in adapting to changing environments and evolving requirements.
Note: We are using Open AI to automate the test case generation process. For this, you need to create an API key for your Open AI account. Check this Open AI API page for more details.
Automated Test Case Generation for Web:
Prerequisite:
Open AI account and API key
Node.js installed on the system
Approach:
For web test case generation using AI the approach I have followed is to scan the DOM structure of the web page analyze the tag and attribute present and then use this as input data to generate the test case.
Step 1: Web Scrapping
Web scrapping will provide us the DOM structure information of the web page. We will store this and then pass this to the next process which is analyzing this stored DOM structure.
Install Puppeteer npm package using npm i puppeteer We are using Puppeteer to launch the browser and visit the web page.
Next, we have an async function scrapeWebPage This function requires the web URL. Once you pass the web URL then it stores the tags and attributes from the DOM content.
This function will return the structure and at last will return the web elements.
Step 2: Analyze elements
In this step, we are analyzing the elements that we got from our first step and based on that we will define what action to take on those elements.
function analyzePageStructure(pageStructure) {
const actions = [];
pageStructure.forEach(element => {
const { tagName, attributes } = element;
if (tagName === 'input' && (attributes.includes('type="text"') || attributes.includes('type="password"'))) {
actions.push(`Fill in the ${tagName} field`);
} else if (tagName === 'button' && attributes.includes('type="submit"')) {
actions.push('Click the submit button');
}
});
console.log("Actions are: ", actions);
return actions;
}
module.exports = analyzePageStructure;
Code Explanation:
Here the function analyzePageStructure takes pageStrucure as a parameter, which is nothing but the elements that we got using web scraping.
We are declaring the action array here to store all the actions that we will define to perform.
In this particular code, I am only considering two types i.e. text and submit and tagNames i.e. input and button.
For type text and tag name input, I am adding an action to enter the data.
For type submit and tag name submit I am adding an action to click.
At last, this function will return the actions array.
Step 3: Generate Test Cases
This is the last step of this approach. Till here we have our actions and the elements as well. Now, we are ready to generate the test cases for the entered web page.
const axios = require('axios');
async function generateBddTestCases(actions, apiKey) {
const prompt = `
Generate BDD test cases using Gherkin syntax for the following login page actions: ${actions.join(', ')}. Include test cases for:
1. Functional Testing: Verify each function of the software application.
2. Boundary Testing: Test boundaries between partitions.
3. Equivalence Partitioning: Divide input data into valid and invalid partitions.
4. Error Guessing: Anticipate errors based on experience.
5. Performance Testing: Ensure the software performs well under expected workloads.
6. Security Testing: Identify vulnerabilities in the system.
`;
const headers = {
'Content-Type': 'application/json',
'Authorization': `Bearer ${apiKey}`
};
const data = {
model: 'gpt-3.5-turbo',
prompt,
max_tokens: 1000,
n: 1,
stop: ['\n'],
};
try {
const response = await axios.post('https://api.openai.com/v1/completions', data, { headers });
return response.data.choices[0].text.trim();
} catch (error) {
console.error('Error generating test cases:', error.response ? error.response.data : error.message);
return null;
}
}
module.exports = generateBddTestCases;
Code Explanation:
The function generateBddTestCases takes two parameters actions and apikey (Open AI API key)
We have added a prompt along with the actions and API key to generate the test cases.
The API used in the above code is provided by Open AI.
Output:
Feature: Login functionality
# Functional Testing
Scenario: Successful login with valid credentials Given the user is on the login page When the user fills in the username field with “user123” And the user fills in the password field with “password123” And the user clicks the submit button Then the user should be redirected to the dashboard
Scenario: Unsuccessful login with invalid credentials Given the user is on the login page When the user fills in the username field with “invalidUser” And the user fills in the password field with “invalidPass” And the user clicks the submit button Then an error message “Invalid username or password” should be displayed
# Boundary Testing
Scenario: Login with username at boundary length Given the user is on the login page When the user fills in the username field with “user12345678901234567890” # Assume max length is 20 And the user fills in the password field with “password123” And the user clicks the submit button Then the user should be redirected to the dashboard
Scenario: Login with password at boundary length Given the user is on the login page When the user fills in the username field with “user123” And the user fills in the password field with “password12345678901234567890” # Assume max length is 20 And the user clicks the submit button Then the user should be redirected to the dashboard
# Equivalence Partitioning
Scenario: Login with invalid username partition Given the user is on the login page When the user fills in the username field with “invalidUser!” And the user fills in the password field with “password123” And the user clicks the submit button Then an error message “Invalid username format” should be displayed
Scenario: Login with invalid password partition Given the user is on the login page When the user fills in the username field with “user123” And the user fills in the password field with “short” And the user clicks the submit button Then an error message “Password is too short” should be displayed
# Error Guessing
Scenario: Login with SQL injection attempt Given the user is on the login page When the user fills in the username field with “admin’–“ And the user fills in the password field with “password123” And the user clicks the submit button Then an error message “Invalid username or password” should be displayed And no unauthorized access should be granted
# Performance Testing
Scenario: Login under load Given the system is under heavy load When the user fills in the username field with “user123” And the user fills in the password field with “password123” And the user clicks the submit button Then the login should succeed within acceptable response time
# Security Testing
Scenario: Login with XSS attack Given the user is on the login page When the user fills in the username field with “<script>alert(‘XSS’)</script>” And the user fills in the password field with “password123” And the user clicks the submit button Then an error message “Invalid username format” should be displayed And no script should be executed
Automated Test Case Generation for API:
Approach:
To effectively achieve AI Test Case Generation for APIs, we start by passing the endpoint and the URI. Subsequently, we attach files containing the payload and the expected response. With these parameters in place, we can then leverage AI, specifically OpenAI, to generate the necessary test cases for the API.
Step 1: Storing the payload and expected response json files in the resources folder
We are going to use the POST API for this and for POST APIs we need payload.
The payload is passed through json file stored in the resources folder.
We also need to pass the expected response of this POST API so that we can create effective test cases.
The expected response json file will help us to create multiple test case to ensure maximum test coverage.
Step 2: Generate Test Cases
In this step, we will use the stored payload, and expected response json files along with the API endpoint.
const fs = require('fs');
const axios = require('axios');
// Step 1: Read JSON files
const readJsonFile = (filePath) => {
try {
return JSON.parse(fs.readFileSync(filePath, 'utf8'));
} catch (error) {
console.error(`Error reading JSON file at ${filePath}:`, error);
throw error;
}
};
const payloadPath = 'path_of_payload.json';
const expectedResultPath = 'path_of_expected_result.json';
const payload = readJsonFile(payloadPath);
const expectedResult = readJsonFile(expectedResultPath);
console.log("Payload:", payload);
console.log("Expected Result:", expectedResult);
// Step 2: Generate BDD Test Cases
const apiKey = 'your_api_key';
const apiUrl = 'https://reqres.in';
const endpoint = '/api/login';
const callType = 'POST';
const generateApiTestCases = async (apiUrl, endpoint, callType, payload, expectedResult, retries = 3) => {
const prompt = `
Generate BDD test cases using Gherkin syntax for the following API:
URL: ${apiUrl}${endpoint}
Call Type: ${callType}
Payload: ${JSON.stringify(payload)}
Expected Result: ${JSON.stringify(expectedResult)}
Include test cases for:
1. Functional Testing: Verify each function of the API.
2. Boundary Testing: Test boundaries for input values.
3. Equivalence Partitioning: Divide input data into valid and invalid partitions.
4. Error Guessing: Anticipate errors based on experience.
5. Performance Testing: Ensure the API performs well under expected workloads.
6. Security Testing: Identify vulnerabilities in the API.
`;
try {
const response = await axios.post('https://api.openai.com/v1/completions', {
model: 'gpt-3.5-turbo',
prompt: prompt,
max_tokens: 1000,
n: 1,
stop: ['\n'],
}, {
headers: {
'Authorization': `Bearer ${apiKey}`,
'Content-Type': 'application/json'
}
});
const bddTestCases = response.data.choices[0].text.trim();
// Check if bddTestCases is a valid string before writing to file
if (typeof bddTestCases === 'string') {
fs.writeFileSync('apiTestCases.txt', bddTestCases);
console.log("BDD test cases written to apiTestCases.txt");
} else {
throw new Error('Invalid data received for BDD test cases');
}
} catch (error) {
if (error.response && error.response.status === 429 && retries > 0) {
console.log('Rate limit exceeded, retrying...');
await new Promise(resolve => setTimeout(resolve, 2000)); // Wait for 2 seconds before retrying
return generateApiTestCases(apiUrl, endpoint, callType, payload, expectedResult, retries - 1);
} else {
console.error('Error generating test cases:', error.response ? error.response.data : error.message);
throw error;
}
}
};
generateApiTestCases(apiUrl, endpoint, callType, payload, expectedResult)
.catch(error => console.error('Error generating test cases:', error));
Code Explanation:
Firstly we are reading the two json files from the resources folder i.e. payload.json and expected_result.json
Next, use your API key, specify the API URL and endpoint along with callType
Write a prompt for generating the test cases.
Use the same Open AI API to generate the test cases.
Output:
Feature: Login API functionality
# Functional Testing
Scenario: Successful login with valid credentials Given the API endpoint is “https://reqres.in/api/login” When a POST request is made with payload:
“”” { “email”: “eve.holt@reqres.in”, “password”: “cityslicka” } “”” Then the response status should be 200 And the response should be: “”” { “token”: “QpwL5tke4Pnpja7X4” } “””
Scenario: Unsuccessful login with missing password Given the API endpoint is “https://reqres.in/api/login” When a POST request is made with payload:
“”” { “email”: “eve.holt@reqres.in” } “”” Then the response status should be 400 And the response should be: “”” { “error”: “Missing password” } “””
Scenario: Unsuccessful login with missing email Given the API endpoint is “https://reqres.in/api/login” When a POST request is made with payload:
“”” { “password”: “cityslicka” } “”” Then the response status should be 400 And the response should be: “”” { “error”: “Missing email” } “””
# Boundary Testing
Scenario: Login with email at boundary length Given the API endpoint is “https://reqres.in/api/login” When a POST request is made with payload:
“”” { “email”: “eve.holt@reqres.in.this.is.a.very.long.email.address”, “password”: “cityslicka” } “”” Then the response status should be 200 And the response should be: “”” { “token”: “QpwL5tke4Pnpja7X4” } “””
Scenario: Login with password at boundary length Given the API endpoint is “https://reqres.in/api/login” When a POST request is made with payload:
“”” { “email”: “eve.holt@reqres.in”, “password”: “thisisaverylongpasswordthatexceedstypicallength” } “”” Then the response status should be 200 And the response should be: “”” { “token”: “QpwL5tke4Pnpja7X4” } “””
# Equivalence Partitioning
Scenario: Login with invalid email format Given the API endpoint is “https://reqres.in/api/login” When a POST request is made with payload:
“”” { “email”: “eve.holt@reqres”, “password”: “cityslicka” } “”” Then the response status should be 400 And the response should be: “”” { “error”: “Invalid email format” } “””
Scenario: Login with invalid password partition Given the API endpoint is “https://reqres.in/api/login” When a POST request is made with payload:
“”” { “email”: “eve.holt@reqres.in”, “password”: “short” } “”” Then the response status should be 400 And the response should be: “”” { “error”: “Password is too short” } “””
# Error Guessing
Scenario: Login with SQL injection attempt Given the API endpoint is “https://reqres.in/api/login” When a POST request is made with payload:
“”” { “email”: “admin’–“, “password”: “cityslicka” } “”” Then the response status should be 401 And the response should be: “”” { “error”: “Invalid email or password” } “”” And no unauthorized access should be granted
# Performance Testing
Scenario: Login under load Given the API endpoint is “https://reqres.in/api/login” When the system is under heavy load And a POST request is made with payload:
“”” { “email”: “eve.holt@reqres.in”, “password”: “cityslicka” } “”” Then the response status should be 200 And the login should succeed within acceptable response time
# Security Testing
Scenario: Login with XSS attack in email Given the API endpoint is “https://reqres.in/api/login” When a POST request is made with payload:
“”” { “email”: “<script>alert(‘XSS’)</script>”, “password”: “cityslicka” } “”” Then the response status should be 400 And the response should be: “”” { “error”: “Invalid email format” } “”” And no script should be executed
Conclusion:
Automating test case generation using AI capabilities will help to ensure total test coverage. It will also enhance the process by addressing the limitations mentioned above of manual test case creation. The use of AI tools like Open AI significantly improves efficiency, increases test coverage, ensures accuracy, and promotes consistency.
The code implementation shared in this blog demonstrates a practical way to leverage OpenAI for automating AI Test Case Generation. I hope you find this information useful and encourage you to explore the benefits of AI in your testing processes. Feel free to share your thoughts and any additional challenges in the comments. Happy testing!
Click here for more blogs on software testing and test automation.
The software development field is in a consistent state of innovation and change. AI in Software Testing in 2024 these Modern highlights, complex functionalities, and ever-evolving user requests require a vigorous testing procedure to guarantee quality and unwavering quality. Conventional testing strategies frequently struggle to keep pace and require a lot of maintenance. However, nowadays, AI-powered test automation and AI in software testing is shaping up as a game-changer that’s transforming the way we test software in 2024.
This progressive approach gives a path and the control of artificial intelligence to automate repeatable and time-consuming tasks, produce intelligent test cases, and analyze endless sums of information. The result? Unparalleled test scope progressed productivity and a noteworthy boost in software quality using AI in software testing in 2024.
In this blog post, we’ll dig into the energizing world of AI-powered test automation and how to use AI in Software Testing. We’ll investigate how AI is reshaping the testing process, the key points of interest it offers, and a glimpse into the future of this transformative innovation. So, buckle up and get prepared to find out how AI is revolutionizing software testing in 2024!
The Evolution of Test Automation (AI in Software Testing)
Back in the day, testing utilized to be a manual affair. Think spreadsheets, sticky notes, and parcels of coffee-fueled late nights. Then came the era of scripts and automation tools. In the early days (think the 1970s!), automation was pretty fundamental. We’re talking basic scripts that mirror user activities. Kind of like a clickbot on autopilot.
Then came the 2000s, with geniuses like Selenium rising. These frameworks permitted more complex testing, letting us automate web applications over distinctive browsers. All of a sudden, repetitive tests seem to be run at the tap of a button. It was a game-changer!
Fast forward to nowadays, and we’re in the age of AI and machine learning. Test automation has become more intelligent, more prescient, and fantastically productive. AI-powered testing tools can analyze tremendous sums of information, recognize patterns, and pinpoint potential issues sometime recently they have gotten to be full-blown bugs With help of AI-powered Test Automation and using AI in Software Testing in 2024.
But it doesn’t stop there. The future of test automation looks indeed more energizing. We’re talking approximately autonomous testing, where AI does not only identify issues but also fixes them independently. Envision a world where your testing suite is like a self-driving car, cruising through test scenarios with accuracy and agility.
So, whether you’re a seasoned QA professional or fair plunging your toes into the testing waters, one thing is clear: the journey of test automation is an exciting ride, and we’re as it is beginning!
Understanding AI in Software Testing and Test Automation in 2024
First off, what’s the buzz about AI? Simply put, AI brings a touch of intelligence to automation. It’s like having a smart assistant that learns and adapts to improve tasks over time. In the realm of software testing, AI is a game-changer.
Imagine this: you have a mountain of test cases to run. It’s tedious, time-consuming, and prone to human error. Enter AI-powered test automation! AI algorithms can analyze massive data sets, identify patterns, and make predictions, streamlining your testing process.
One of the coolest AI features is predictive analytics. It can foresee potential issues based on past data, helping you catch bugs before they cause chaos in production. Talk about being proactive!
Natural language processing (NLP) is another star player as it allows testers to interact with systems using human language, making test creation and execution more intuitive. Gone are the days of cryptic commands or complex scripts!
Let’s not forget about Machine Learning (ML). ML algorithms can autonomously improve test coverage by learning from test results and refining test cases. It’s like having a self-improving testing system on autopilot.
But wait, there’s more! Additionally, AI can optimize test execution by prioritizing critical tests, reducing redundant ones, and dynamically adjusting test suites based on code changes. Indeed, it’s like having a super-smart QA team working tirelessly in the background using AI in software testing in 2024.
Benefits of AI-Powered Test Automation
Integrating AI into test automation offers various points of interest to software improvement teams:
Improved Test Scope and Precision: AI algorithms pinpoint critical test scenarios and make test cases covering a wide extent of functionalities, guaranteeing comprehensive scope and exact results.
Faster Test Execution: AI-assisted testing speeds up test execution by automating repetitive tasks, liberating groups to focus on impactful testing and accelerating time-to-market.
Cost Savings and Asset Optimization: Automation diminishes manual effort, leading to noteworthy cost savings and way better asset allocation.
Enhanced Scalability and Adaptability: AI-powered automation scales with project needs, handles complex scenarios and adjusts to application changes consistently.
Challenges and Considerations of AI in Software Testing
Despite the compelling benefits, organizations must explore a few challenges into AI in software testing:
Initial Learning Curve: Implementing AI tools in test automation requires learning and setup, which can be a hurdle for some teams.
Data Quality: AI’s effectiveness pivots on clean, significant training data, emphasizing the significance of data quality.
Maintenance Overhead: Regular upgrades and maintenance of AI models are fundamental to align with advancing software and commerce needs.
Ethical Considerations: AI automation raises moral questions around data security, inclination, and straightforwardness, requiring proactive addressing of these concerns.
Best Practices for Implementing AI in Software Testing and Test Automation
To harness the full potential of AI-powered test automation, organizations should follow best practices such as:
Define Clear Objectives: Before diving into AI-powered test automation, outline your goals. What do you want to achieve? Improved test coverage, faster time to market, or better defect detection rates? Clear objectives will guide your AI implementation strategy.
Select the Right Tools: Choose AI tools that align with your testing needs. Look for features like intelligent test case generation, self-healing capabilities, and predictive analytics. Tools like Testim, Applitools, or Eggplant AI offer robust AI-assisted testing solutions.
Start Small, Scale Gradually: Begin with a pilot project or a small set of test cases to evaluate the effectiveness of AI in your automation framework. Once you gain confidence and see tangible benefits, gradually scale up your AI initiatives.
Data Quality Matters: AI thrives on data, so ensure you have high-quality, diverse datasets for training and testing AI models. Clean, relevant data will enhance the accuracy and reliability of your AI-assisted test automation.
Collaborate Across Teams: Foster collaboration between QA, development, and data science teams. Work together to define testing scenarios, validate AI models, and integrate AI-powered testing seamlessly into your CI/CD pipelines.
Continuous Learning and Optimization: AI evolves, so prioritize continuous learning and optimization. Monitor test results, gather feedback, and refine your AI models to adapt to changing requirements and improve overall testing efficiency.
Ethical Considerations: Finally, remember the ethical implications of AI in testing. Ensure transparency, fairness, and accountability in AI-assisted decision-making processes to build trust and maintain integrity in your testing practices.
The Role of AI in Software Testing
As we investigate the impact of AI in software testing, a few key zones come into focus:
AI Utilities for Test Case Generation, Test Execution, and Defect Prediction.
AI-Powered Test Case Generation: AI algorithms utilize strategies such as natural language processing (NLP) and machine learning (ML) to analyze prerequisite archives, user stories, and historical test data. They can recognize critical ways, edge cases, and potential vulnerabilities inside the software, producing test cases that cover these perspectives comprehensively. Moreover, AI in software testing can prioritize test cases based on risk factors, guaranteeing that high-impact zones are altogether tested.
AI-Assisted Test Execution: AI-assisted test execution optimizes testing processes by powerfully designating assets, prioritizing test cases, and adjusting testing techniques based on real-time input. AI algorithms can identify flaky tests, reroute test streams to maintain a strategic distance from bottlenecks and parallelize test execution to speed up input cycles. This approach minimizes testing costs and accelerates time-to-market for software releases.
AI-Based Defect Prediction: Machine learning models trained on historical defect data can anticipate potential defects and vulnerabilities in software code. By analyzing code complexity, altering history, and code quality measurements, AI can flag regions that are likely to cause issues. This proactive approach empowers developers to focus their efforts on code areas with a higher probability of defects, diminishing post-release bug events.
AI-Powered Test Automation Frameworks and Test Data Management
AI-Powered Test Automation Frameworks: AI-powered test automation frameworks consolidate keen features such as self-healing tests, versatile test execution, and prescient support. They utilize AI algorithms to identify and resolve test failures, optimize test execution based on historical information, and anticipate maintenance tasks for test scripts. This moves forward test steadiness, decreases false positives, and improves in general automation efficiency.
AI-Powered Test Data Management: AI computerizes test data management by analyzing data dependencies, making engineered test data sets, and anonymizing delicate data. It can distinguish information varieties required for testing distinctive scenarios and produce data that mimics real-world utilization patterns. This guarantees that testing environments are practical, different, and compliant with data protection regulations.
AI in Test Environment Provisioning and Test Maintenance.
Dynamic Test Environment Provisioning: AI analyzes asset accessibility, test prerequisites, and historical utilization patterns to dynamically provision test environments. It can distribute assets effectively, turn up virtualized environments, and configure network settings based on testing needs. This dynamic provisioning diminishes holding up times for test environments and progresses testing efficiency.
Intelligent Test Maintenance: AI in software testing automates test maintenance tasks by recognizing excess or obsolete test cases, recommending optimizations, and automatically upgrading test scripts. It analyzes code changes, affect analysis reports, and test coverage information to guarantee that tests stay significant and compelling. This decreases maintenance overhead and keeps testing forms agile and responsive to software changes.
AI enhances Test Efficiency, Effectiveness, and Reporting.
Progressed Test Scope and Accuracy: AI algorithms exceed expectations in recognizing complex test scenarios that conventional testing approaches might neglect. By leveraging strategies like genetic algorithms and support learning, AI can create test cases. These test cases cover a wide range of functionalities and edge cases. This comes about in progressed test scope and higher precision in recognizing software defects and performance issues.
AI-Enhanced Test Reporting and Analytics: AI-powered analytics tools analyze test results and identify patterns. They provide significant insights into test scope, performance trends, and defect clustering. AI-powered analytics tools analyze test results and identify patterns, thereby producing visualizations, trend examination reports, and inconsistency detection cautions. These insights help teams prioritize testing endeavors and make data-driven choices, enhancing overall test visibility and effectiveness.
AI-Powered Test Optimization and Performance Monitoring: AI plays a significant part in optimizing test processes and observing performance measurements. AI algorithms analyze testing information, execution times, asset utilization, and system behavior to distinguish optimization opportunities. Furthermore, this incorporates dynamically altering test arrangements, prioritizing critical tests, and optimizing test execution workflows for proficiency. Moreover, AI-assisted performance monitoring tools persistently screen application performance amid testing, identifying bottlenecks, memory leaks, and performance relapses. They produce performance reports, distinguish performance degradation patterns, and give suggestions for improving application performance.
Enhanced Collaboration between Development and Testing Teams
AI-powered test automation cultivates upgraded collaboration between development and testing teams:
Streamlined Communication: AI-assisted testing tools encourage consistent communication and collaboration between development and testing teams, empowering real-time input and issue resolution.
Shared Bits of Knowledge: AI-powered analytics give important bits of knowledge into testing measurements, performance patterns, and defect patterns, cultivating data-driven decision-making and persistent improvement.
Cross-Functional Collaboration: AI empowers cross-functional collaboration between developers, testers, data researchers, and AI masters, advancing collaboration and collective problem-solving.
Predictions for the Future of AI in Software Testing
Looking ahead, the future of AI in software testing holds promising predictions:
Advancements in AI Algorithms: Proceeded advancements in AI algorithms will lead to more advanced testing techniques, including progressed inconsistency discovery, self-learning testing frameworks, and predictive analytics.
Integration with DevOps and CI/CD: AI-powered testing will consistently coordinate with DevOps and Continuous Integration/Continuous Deployment (CI/CD) pipelines, thereby enabling quicker feedback loops. This includes automated testing in production environments and upgraded release cycles.
AI-Assisted Test Orchestration: AI will play a central part in test orchestration, dynamically managing test environments, assets, and test execution methodologies based on real-time data and project priorities.
Challenges and Opportunities in AI-Powered Testing
While AI-powered testing offers immense opportunities, it also presents challenges:
Complexity of AI Integration: Integrating AI into existing testing frameworks requires expertise in AI technologies, data management, and test automation, posing initial implementation challenges.
Data Quality and Bias: Ensuring data quality, addressing biases in AI models, and maintaining data privacy and security are ongoing challenges that organizations must address.
Skills Gap and Training: Building AI capabilities within testing teams, upskilling testers in AI concepts, and fostering a culture of AI-assisted testing require continuous learning and investment in training programs.
Strategies for Maximizing the Potential of AI-Powered Test Automation
To maximize the potential of AI-powered test automation, organizations can adopt the following strategies:
Strategic Alignment: Align AI initiatives with business objectives, prioritize use cases with high ROI potential, and develop a roadmap for AI integration into testing processes.
Continuous Learning and Collaboration: Invest in training programs, workshops, and knowledge-sharing sessions to build AI expertise within testing teams and foster collaboration with AI specialists and data scientists.
Data Governance and Ethics: Implement robust data governance practices, ensure data quality and integrity, address algorithm biases, and adhere to ethical guidelines for AI-assisted testing.
Pilot Projects and Iterative Approach: Start with pilot projects to validate AI capabilities, gather feedback, iterate on improvements, and gradually scale AI initiatives across testing environments.
Conclusion
In conclusion, AI-powered test automation stands as a significant force in revolutionizing AI in software testing in 2024 and beyond. With its capacity to upgrade effectiveness, precision, and speed in testing processes, AI-Assisted solutions are, therefore, reshaping how software is created and validated. By leveraging machine learning, natural language processing, and other AI technologies, organizations can streamline their testing workflows and identify defects earlier. Consequently, this enables them to bring high-quality software products to market faster than ever before.
As we move forward, the integration of AI into test automation will proceed to advance, offering indeed more progressed capabilities such as predictive analytics, autonomous testing, and versatile test procedures. This development will help optimize testing efforts, reduce costs, and improve overall software quality. Ultimately, it will benefit both businesses and end-users alike. Grasping AI-powered test automation is not just a trend; rather, it is a key imperative for modern software development organizations. Furthermore, it is essential for staying competitive in today’s fast-paced digital environment using AI in software testing in 2024.
Desktop application test automation can be a tedious task as it’s hard to locate the elements and interact with those elements. There are plenty of tools available for automating desktop applications. Winium is one of those tools which is a selenium-based tool. So for those who don’t have an idea about Selenium, Selenium is a web application test automation tool that supports almost all programming languages. (Wish to learn more about selenium? Check out the link here) If you are familiar with the Selenium tool then it’s going to be easy for you to understand the workings of the Winium tool as most of the methods are common and if you are not familiar with Selenium no worries, I have got you covered.
Coming back to our topic, In this blog we will see how we can create a robust test automation framework for automating desktop applications using Winium a desktop application automation tool, Java as a programming language, Maven, as a dependency management tool, Cucumber as a BDD (Behavior Driven Development) tool. We are going to build a test automation framework from scratch. Even if you don’t have any idea on how to create a framework no worries.
Before we start building the framework let’s complete the environment set-up. So for this, we will have to install some tools. Below I am sharing the URLs of the tools we are using just in case if you want to know more about these tools then you can visit these official web pages.
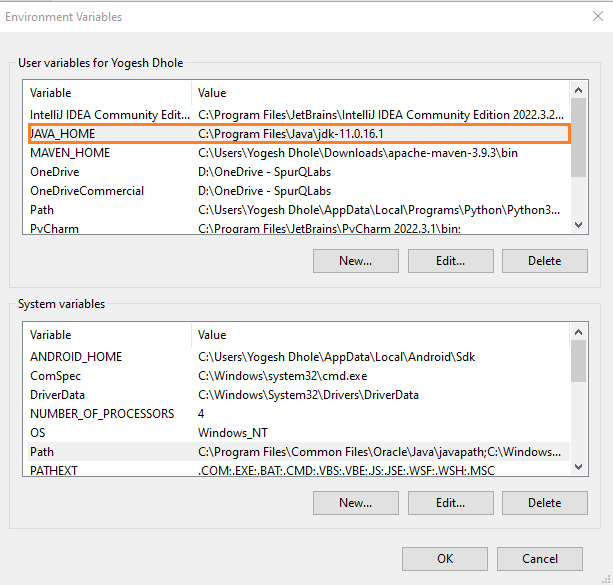
Once the download is completed the next step is setting up the path in the environment variables. Check the below screenshots to set up the path in your system environment variables
Once you are done with the above steps then you should see the below information in the command prompt.
Maven Set-up :
Once you are done with Java Installation and set up the next step is to do the installation and set up the maven.
Not only that there are other desktop application element inspection tools.
Once you are done with the above steps then we can start building the automation framework.
Implementing BDD with Cucumber for Desktop Automation:
The BDD (Behavior-Driven-Development) is a software development approach that focuses on collaboration among stakeholders, including developers, QA engineers, and business analysts. The reason behind this is that in the BDD approach, we use natural language specifications to describe software behaviour from the end user’s perspective. I believe this helps in creating a shared understanding of requirements and promotes effective communication throughout the development lifecycle. Let’s see this in detail,
Feature File Creation :
Feature files are the main component of the BDD cucumber framework we can even say they are the heart of this cucumber framework.
These files are written using gherkin language which describes the high-level functionalities of the application.
Cucumber is a widely used BDD tool as it allows us to write test cases (scenarios) in plain tests using the Gherkin syntax.
This is because Gherkin uses keywords like, Given, When, And, and Then to structure scenarios, making it easy to read and understand by both technical and non-technical stakeholders.
Here is the one scenario that I have created for this framework.
@winiumApp
Feature: To verify the draw functionality of AutoCAD software
As a User I want to launch the application
and validate that I can access the different functionalities of the application.
@smoke
Scenario: Verify user can launch and open the new document using microsoft word application
Given User launches the microsoft word application
When User verifies the landing screen is visible with "Recent" opened document list
And User clicks on "Blank document" option to add blank document
Then User verifies that "Page 1 content" a new page for opened blank page is visible
Step Definition File Creation :
Yes, that’s correct. Step definition files contain code that maps the steps in the feature file to automation code.
These files are written using the programming language used in the automation framework, in this case, Java.
The step definitions are responsible for interacting with the elements of the application and performing actions on them such as clicking, entering text, etc.
They also contain assertions to check if the expected behaviour is observed in the application.
package com.SpurCumber.Steps;
import com.SpurCumber.Pages.DemoWiniumAppPage;
import com.SpurCumber.Utils.ScreenshotHelper;
import com.SpurCumber.Utils.TestContext;
import io.cucumber.java.en.And;
import io.cucumber.java.en.Given;
import io.cucumber.java.en.Then;
import io.cucumber.java.en.When;
import org.testng.Assert;
public class DemoWiniumAppSteps extends TestContext {
private final DemoWiniumAppPage demoWiniumAppPage;
public DemoWiniumAppSteps() {
demoWiniumAppPage = new DemoWiniumAppPage(winiumdriver);
}
@Given("User launches the microsoft word application")
public void userLaunchesTheMicrosoftWordApplication() {
scenario.log("The application is launched successfully!");
ScreenshotHelper.takeWebScreenshotBase64(winiumdriver);
ScreenshotHelper.captureScreenshotAllure(winiumdriver, "User launches the microsoft word application");
}
@When("User verifies the landing screen is visible with {string} opened document list")
public void userVerifiesTheLandingScreenIsVisible(String arg0) throws InterruptedException {
Assert.assertTrue(demoWiniumAppPage.verifyScreen(arg0));
ScreenshotHelper.takeWebScreenshotBase64(winiumdriver);
ScreenshotHelper.captureScreenshotAllure(winiumdriver, "User verifies the landing screen is visible with "+arg0+" opened document list");
}
@And("User clicks on {string} option to add blank document")
public void userClicksOnOptionToAddBlankDocument(String arg0) throws InterruptedException {
demoWiniumAppPage.clickBtnByName(arg0);
ScreenshotHelper.takeWebScreenshotBase64(winiumdriver);
ScreenshotHelper.captureScreenshotAllure(winiumdriver, "User clicks on "+arg0+" option to add blank document");
}
@Then("User verifies that {string} a new page for opened blank page is visible")
public void userVerifiesThatANewPageForOpenedBlankPageIsVisible(String arg0) throws InterruptedException {
Assert.assertTrue(demoWiniumAppPage.verifyScreen(arg0));
ScreenshotHelper.takeWebScreenshotBase64(winiumdriver);
ScreenshotHelper.captureScreenshotAllure(winiumdriver, "User verifies that "+arg0+" a new page for opened blank page is visible");
}
}
Hooks File Creation :
In Cucumber, hooks are methods annotated with @Before and @After that run before and after each scenario.
To ensure consistency between test environments, these hooks are used for setting up and taking down tests.
The application can be initialized before and cleaned up after each scenario using hooks, for example.
Implementing Page Object Model (POM) for Desktop Automation:
The Page Object Model (POM) is a design pattern that assists in building automation frameworks that are scalable and maintainable. In POM, we create individual page classes for each application page or component, which encapsulates the interactions and elements associated with that particular page. This approach improves code readability, reduces code duplication, and enhances test maintenance.
package com.SpurCumber.Pages;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.winium.WiniumDriver;
public class DemoWiniumAppPage {
private final WiniumDriver winiumdriver;
public DemoWiniumAppPage(WiniumDriver _winiumdriver) {
this.winiumdriver = _winiumdriver;
}
public Boolean verifyScreen(String locator) throws InterruptedException {
WebElement Screen = winiumdriver.findElementByName(locator);
return Screen.isDisplayed();
}
public void clickBtnByName(String locator) throws InterruptedException {
WebElement element = winiumdriver.findElementByName(locator);
Thread.sleep(3000);
element.click();
}
}
Creating Utility Files to Support Framework:
In a test automation framework, utility files provide reusable functionalities, configurations, and helper methods to streamline the development, execution, and maintenance of test scripts. As a result, they enhance the efficiency, scalability, and maintainability of the automation framework. Listed below are a few common utility files, along with their functions:
Winium Util File :
This utility file handles the launch and termination processes of the desktop application, as well as the Winium driver
When we use Winium as a desktop application automation tool we have to start the server. (Winium Driver).
Either we can do this manually before starting the execution of the test case or we can do this through automation as well.
In the below utility file there are methods created for launching the desktop application and Winium driver (server).
This common util file reads or retrieves the values and files present in a particular folder (referenced here as the resource folder).
This file can further serve as a basis for developing additional common methods usable throughout the framework.
package com.SpurCumber.Utils;
import java.io.File;
import java.nio.file.Paths;
public class CommonUtil {
public static String getResourceDirPath(String parameter) {
String assemblyLocation = System.getProperty("user.dir");
String path = Paths.get(assemblyLocation+"/src/test/resources/"+parameter).toString();
return new File(path).getAbsolutePath();
}
}
Test Runner File :
The TestRunner class executes Cucumber tests with specified configuration settings, including the location of feature files, step definitions package, inclusion tags, and report generation plugins.
The seamless integration of Cucumber tests into TestNG makes testing and reporting easy.
Once we have defined the test scenarios, we will use Maven commands to execute them. Maven is a robust tool that manages project dependencies and automates the build process. With Maven, we can run automated tests with ease and ensure a smooth and efficient testing process.
Configuring Maven POM File(Pom.xml):
In the project’s Maven Project Object Model (POM) file, we define the necessary configurations for test execution.
This includes specifying the test runner class, defining the location of feature files and step definitions, setting up plugins for generating test reports, and configuring any additional dependencies required for testing.
Once you configure the automated tests in the Maven POM file, you can run them using Maven commands from the terminal or command prompt. Common Maven commands used for test execution include:
mvn test – This command runs all the tests from the project.
mvn clean test – This command first cleans the project (removes the target directory) and then runs the tests.
mvn test “-Dcucumber.filter.tags=@tagName” – This command runs tests with specific Cucumber tags.
Generating Cucumber Reports:
Cucumber provides built-in support for generating comprehensive test reports. By configuring plugins in our automation framework, we can generate detailed reports that showcase the test results, including passed, failed, and pending scenarios. These reports offer valuable insights into the test execution, helping us identify issues, track progress, and make data-driven decisions for test improvements.
Conclusion:
Automating desktop applications with Winium, Java, and Behavior-Driven Development (BDD) using Cucumber is a strategic approach that offers numerous benefits to software development and testing teams. By combining these technologies and methodologies, we create a robust automation framework that enhances software quality, reduces manual efforts, and promotes collaboration across teams.
In conclusion, automating desktop applications with Winium, Java, and BDD using Cucumber empowers teams to deliver high-quality software efficiently. By leveraging the strengths of each technology and following best practices such as the Page Object Model and Maven integration, we create a solid foundation for successful test automation that aligns with business goals and enhances overall product quality.
Source Code:
You can access the complete source code of the created automation framework for desktop applications using Winium, Java, and BDD with Cucumber on GitHub at https://github.com/spurqlabs/Desktop-App-Winium-Java-Cucumber The framework includes feature files, step definitions, page classes following the Page Object Model, Maven dependencies, and configuration files for generating Cucumber reports. Feel free to explore, fork, and contribute to enhance the framework further.
GitHub Actions has revolutionized the way developers and testers automate their workflows. With Actions, developers can easily define and customize their CI/CD processes, enhancing productivity and code quality. One of the powerful features of GitHub Actions is the ability to trigger workflows from another workflow GitHub Actions. In this article, we will delve into the intricacies of mastering GitHub Actions and explore how to trigger workflows from other workflows.
Understanding GitActions and their Benefits:
GitHub Actions is a powerful automation framework integrated into GitHub. It allows developers and testers to define custom workflows composed of one or more jobs, each consisting of various steps. These workflows can be triggered based on events such as push and pull requests, commits, or scheduled actions. The benefits of using GitHub Actions include faster development cycles, improved collaboration, and streamlined release processes.
Defining workflow in GitHub Actions:
Before we delve into triggering workflows, let’s define what a workflow is in GitHub Actions. A workflow is a configurable automated process that runs on GitHub repositories. It consists of one or more jobs, each defining a set of steps. These steps can perform tasks such as building, testing, and deploying code.
Overview of triggering workflows from another workflow using GitHub Action:
It is important to understand workflow dependencies to trigger a workflow from another workflow. Workflow dependencies refer to the relationships between different workflows, where one workflow triggers the execution of another workflow. By leveraging workflow dependencies, developers and testers can create a seamless and interconnected automation pipeline.
In complex development scenarios, there is often a need to trigger workflows based on the completion of other workflows. This can be particularly useful when different parts of the development process depend on each other and when different teams collaborate on a project. By triggering workflows from related workflows, developers and testers can automate the execution of dependent tasks, ensuring a smoother development workflow.
The advantages of workflow interdependency are numerous. Firstly, it allows for a modular and reusable approach to workflow automation. Instead of duplicating steps across different workflows, developers, and testers can encapsulate common operations in one workflow and trigger it from others. This promotes code reusability, reduces maintenance efforts, and enhances overall development efficiency. Moreover, workflow interdependency enables better collaboration between teams working on different aspects of a project, ensuring a seamless integration between their workflows.
GitHub Action Prerequisites:
A GitHub repository having a workflow defined in it (repository_01)
Another GitHub repository (repository_02) has a workflow defined in it that triggers after repository_01 workflow completion.
GitHub personal access token
As we have all the required stuff for our goal then let’s get it done. First will understand about GitHub personal access token.
GitHub Personal Access Token (PAT):
Personal access tokens are an alternative to using passwords to authenticate GitHub when using the GitHub API or the command line. Personal access tokens are intended to access GitHub resources on your behalf.
1: First, Access your GitHub account by logging in.
2: Navigate to your profile, click on “Settings,” and proceed to “Developers.”
3: Click on Personal Access Token and then Select Token Classic.
4: Navigate to and choose “Generate new token,” then select Generate new token Classic.
5: Here,we Include a note for your Access Token (PAT) – it’s optional. Choose the expiration date for your PAT. Select the scope and at last click on generate token. Copy the token and paste it on a notepad.
(Remember the selected scope will decide the permissions and authorization to access another repository and workflow)
So now we need to add the generated PAT to our repository_01 as a secret to do this follow the below steps.
To navigate to your repository, you can click on the settings.
Then go to secrets and variables then select the Action button.
Select the repository secret, add PAT_TOKEN in the name, and paste the copied personal access token in the value. Click on Add Secret.
Workflow Creation (repository_01):
To create a workflow head over to the action tab and click on new workflow. Then select Set up workflow yourself. Now customize your workflow and add the below step to trigger the (repository_02) workflow.
name: Workflow01
on:
push:
branches:
- main
jobs:
build:
runs-on: ubuntu-latest
timeout-minutes: 600
steps:
- name: Checkout to repository
- uses: actions/checkout@v3
# Your existing workflow steps
# At the end of your all steps add the below step
trigger-workflow02:
needs: build
runs-on: ubuntu-latest
steps:
- name: Trigger Workflow02
uses: peter-evans/repository-dispatch@v2
with:
token: ${{ secrets.PAT_TOKEN }}
repository: username/repository_02 name
event-type: trigger-workflow02
Let’s understand the trigger-workflow02 stage. Following is the secret we have added is used here to provide the permissions and the authorization to understand and trigger the workflow_02 of repository_02 also replace the username with your GitHub username and repository_02 name with your other repository name.
Workflow Creation (repository_02):
As our first workflow is ready now let’s create our second workflow for repository_02. Follow the same steps described in the above step for the creation of a workflow.
name: Workflow02
on:
repository_dispatch:
types:
- trigger-workflow02
jobs:
build-and-test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
# your existing steps of workflow
Now let’s understand what to consider here, first the triggering event is set as repository_dispatch means when the other repository is completed this workflow will get triggered and now to specify which repository we arousing types as trigger-workflow02 which is defined as a stage in the workflow01.
We are done this is how we can trigger the workflow02 of repository_02 when the execution of workflow01 of repository_01 is completed and the status is passed. Below are the output screenshots give it a check.
For Organization Account:
Till this point whatever we have seen it’s for our personal GitHub account and if we want to implement this concept for the organization’s GitHub account then we need to introduce a small change in the workflow01 of the repository_01.
name: Workflow01
on:
push:
branches:
- main
jobs:
build:
runs-on: ubuntu-latest
timeout-minutes: 600
steps:
- name: Checkout to repository
- uses: actions/checkout@v3
# Your existing workflow steps
# At the end of your all steps add the below step
trigger-workflow02:
needs: build
runs-on: ubuntu-latest
steps:
- name: Trigger Workflow02
uses: peter-evans/repository-dispatch@v2
with:
token: ${{ secrets.PAT_TOKEN }}
repository: organization/repository_02 name
event-type: trigger-workflow02
Let’s understand the trigger-workflow02 stage. The secret we have added is used here to provide the permissions and authorization to trigger the workflow_02 of repository_02 also replace the organization with your organization’s GitHub name and repository_02 name with your other repository name.
Conclusion:
In this blog, we have explored the powerful feature of trigger workflow from another workflow using GitHub Actions. By understanding workflow dependencies, leveraging workflow events and triggers, implementing remote triggers, and building scalable workflow chains, developers can enhance their CI/CD processes and workflow automation. To summarize, triggering workflows from another workflow allows for increased reusability, collaboration, and customization of automation processes. By embracing these features, developers can optimize their development workflows and empower their teams to achieve greater productivity and efficiency.
Automating API test suite execution through CI/CD pipelines provides a significant advantage over local execution. By leveraging CI/CD, teams can obtain test results for all systems, improving the speed, quality, and reliability of tests. Manual triggering of API suite execution is not required, freeing up valuable time for team members.
In this blog post, we will guide you through the creation of a workflow file using GitHub Actions for your automated API tests. However, before diving into the creation of a CI/CD workflow, it’s essential to understand some crucial points for a better grasp of the concept.
Before we start creating a CI/CD workflow for our API tests I will suggest you first go through the API test automation framework here and also read this blog on creating a web test automation framework as it helps you to understand the different points which we all should consider before selecting the test automation framework. The API test automation framework is in Python language and has Behave library for BDD purposes.
Let’s understand some basic and important points to start with the CI/CD workflow.
What is DevOps?
DevOps is a set of practices and tools that integrate and automate tasks in the software development and IT industry. It establishes communication and collaboration between development and operations teams, enabling faster and more reliable software build, testing, and release processes. DevOps is a methodology that derives its name from the combination of “Development” and “Operations.”
The primary goal of DevOps is to bridge the gap between development and operations teams by fostering a culture of shared responsibility and collaboration. This helps to reduce the time it takes to develop, test, and deploy software while maintaining high quality and reliability standards. By automating manual processes and eliminating silos between teams, DevOps enables organizations to respond more quickly to changing market demands and customer needs.
CI/CD refers to Continuous Integration and Continuous Delivery, which are processes and practices that help to deliver code changes more frequently and reliably. These processes involve automating the building, testing, and deployment of code changes, resulting in faster and higher-quality software releases for end-users.
The CI/CD pipeline follows a workflow that starts with continuous integration (CI), followed by continuous delivery (CD). The CI process involves integrating code changes into a shared repository and automatically building and testing them to identify errors early in the development process. Once the code has been tested and approved, the CD process takes over and automates the delivery of code changes to production environments.
The CI/CD pipeline workflow helps to reduce the risks and delays associated with manual code integration and deployment while ensuring that the changes are tested and delivered quickly and reliably. This approach enables organizations to innovate faster, respond more quickly to market demands, and improve overall software quality.
Process:
What are GitHub Actions?
GitHub Actions is a feature that makes it easy to automate software workflows, including world-class CI/CD capabilities. With GitHub Actions, you can build, test, and deploy your code directly from GitHub, while also customizing code reviews, branch management, and issue-triaging workflows to suit your needs.
The GitHub platform offers integration with GitHub Actions, providing flexibility for customizing workflows to automate tasks such as building, testing, and deploying code. Developers can create custom workflows using GitHub Actions that are automatically triggered when specific events occur, such as code push, pull request merge, or as per a defined schedule.
Workflows are defined using YAML syntax, which is a human-readable data serialization language. YAML is commonly used for configuration files and in applications to store or transmit data. To learn more about YAML syntax and its history, please visit the following link.
Advantages / Benefits of using GitHub Actions for CI/CD Pipeline:
Seamless integration: GitHub Actions seamlessly integrates with GitHub repositories, making it easy to automate workflows and tasks directly from the repository.
Highly customizable: GitHub Actions offers a high degree of customization, allowing developers to create workflows that suit their specific needs.
Time-saving: GitHub Actions automates many tasks in the software development process, saving developers time and reducing the potential for errors.
Flexible: GitHub Actions can be used for a wide range of tasks, including building, testing, and deploying applications.
Workflow visualization: GitHub Actions provides a graphical representation of workflows, making it easy for developers to visualize and understand the process.
Large community: GitHub Actions has a large and active community, providing a wealth of resources, documentation, and support for developers.
Cost Saving: GitHub Actions come bundled with Github free and enterprise licenses reducing the cost of maintaining separate CI/CD tools like Jenkins
Framework Overview:
This is a BDD API automation testing framework. The reason behind choosing the BDD framework is simple it provides you the following benefits over other testing frameworks.
Improved Collaboration
Increased Test coverage
Better Test Readability
Easy Test Maintenance
Faster Feedback
Integration with Other Tools
Focus on Business Requirements
Discover what are the different types of automation testing frameworks available and why to prefer the BDD framework over others here.
Framework Explanation:
The framework is simple because we included a feature file written in the Gherkin language, as you will notice. Basically, Gherkin is a simple plain text language with a simple structure. The feature file is easy to understand for a non-technical person and that is why we prefer the BDD framework for automation. To learn more about the Gherkin language please visit the official site here https://cucumber.io/docs/gherkin/reference/. Also, we have included the POST, GET, PUT & DELETE API methods. A feature file describes all these methods using simple and understandable language.
The next component of our framework is the step file. The feature and step files are the two main and most essential parts of the BDD framework. The step file contains the implementation of the steps mentioned in the feature file. It maps the respective steps from the feature file and executes the code.We use the behave library to achieve this. The behave understands the maps of the steps with the feature file steps as both steps have the same language structure.
Then there is the utility file which contains the methods which we can use more repeatedly. There is one configuration file where we store the commonly used data. Furthermore, to install all the dependencies, we have created a requirement.txt file which contains the packages with specific versions. To install the packages from the requirement.txt file we have the following command.
pip install -r requirement.txt
The above framework is explained in detail here. I suggest you please check out the blog first and understand the framework then we can move further with the workflow detail description. A proper understanding of the framework is essential to understand how to create the CI/CD workflow file.
How to create a Workflow File?
Create a GitHub repository for your framework
Push your framework to that repository
Click on the Action Button
Click on set workflow your self option
Give a proper name to the workflow file
“Additionally, please check out the below video for a detailed step understanding.” The video will show you how to create workflow files and the steps need to follow to do so.
github actions workflow file creation
Components of CI/CD Workflow File:
Events:
Events are responsible to trigger the CI/CD workflow file. They are nothing but the actions that happen in the repository for example pushing to the branch or creating a pull request. Please check the below sample events that trigger the CI/CD workflow file.
push: This event is triggered when someone pushes code to a branch in your repository.
pull_request: This event is triggered when someone opens a new pull request or updates an existing one.
schedule: This event is triggered on a schedule that you define in your workflow configuration file.
workflow_dispatch: This event allows you to manually trigger a workflow by clicking a button in the GitHub UI.
release: This event is triggered when a new release is created in your repository.
repository_dispatch: This event allows you to trigger a workflow using a custom webhook event.
page_build: This event is triggered when GitHub Pages are built or rebuilt.
issue_comment: This event is triggered when someone comments on an issue in your repository.
pull_request_review: This event is triggered when someone reviews a pull request in your repository.
push_tag: This event is triggered when someone pushes a tag to your repository.
To know more about the events that trigger workflows please check out the GitHub official documentation here
Jobs:
After setting up the events to trigger the workflow the next step is to set up the job for the workflow. The job consists of a set of steps that performs specific tasks. For every job, there is a separate runner or we can call it a virtual machine (VM) therefore each job can run parallelly. This allows us to execute multiple tasks concurrently.
A workflow can have more than one job with a unique name and set of steps that define the actions to perform. For example, we can use a job in the workflow file to build the project, test its functionality, and deploy it to a server. The defined jobs in the workflow file can be dependent on each other. Also, they can have different requirements than the others like specific operating systems, software dependencies or packages, or environment variables.
Discover more about using jobs in a workflow from GitHub’s official documentation here
Runners:
To execute the jobs we need runners. The runners in GitHub actions are nothing but virtual machines or physical servers. GitHub categorizes them into two parts named self-hosted or provided by GitHub. Moreover, the runners are responsible for running the steps described in the job.
The self-hosed runners allow us to execute the jobs on our own system or infrastructure for example our own physical servers, virtual machines, or containers. We use self-hosted runners when we need to run jobs on specialized hardware requirements that must be met.
GitHub-hosted runners are provided by GitHub itself and can be used for free by anyone. These runners are available in a variety of configurations. Furthermore, the best thing about GitHub-hosted runners is that they automatically update with the latest software updates and security patches.
Learn more about runners for GitHub actions workflow here from GitHub’s official documentation.
Steps:
Steps in the workflow file are used to carry out particular actions. Subsequently, after adding the runner to the workflow file, we define these steps with the help of the steps property in the workflow file. Additionally, the steps consist of actions and commands to perform on the build. For example, there are steps to download the dependencies, check out the build, run the test, upload the artifacts, etc.
Learn more about the steps used in the workflow file from GitHub’s official documentation here
Actions:
In the GitHub actions workflow file, we use actions that are reusable code modules that can be shared across different workflows and repositories. One or more steps are defined under actions to perform specific tasks such as running tests, building the project, or deploying the code. We can also define the input and output parameters to the actions which help us to receive and return the data from other steps in the workflow. Developers describe the actions, and they are available on GitHub Marketplace. To use an action in the workflow, we need to use the uses property.
Find out more about actions for GitHub actions from GitHub’s official documentation here
Now we have covered all the basic topics that we need to understand before creating our CI/CD workflow file for the API automation framework. Now, let’s start explaining the workflow file.
We use the name property to give the name to the workflow file. It is a good practice to give a proper name to your workflow file. Generally, the name is related to the feature or the repository name.
name: Python API CI/CD Pipeline
Event:
Now we have to set up the event that triggers the workflow file. In this workflow, I have added two events for your reference. The pipeline will trigger the push event for the ‘main‘ branch. Additionally, I added the scheduled event to automatically trigger the workflow as per the set schedule.
The above schedule indicates that the pipeline Runs at 12:00. Action schedules run at most every 5 minutes using UTC time.
We can customize the schedule timing as per our needs. Check out the following chron specification diagram to learn how to set the schedule timing.
Job:
The job we are setting here is to build. We want to build the project and perform the required tasks as we merge new code changes.
jobs:
build:
Runner:
The runner we are using here is a GitHub-hosted runner. In this workflow, we are using a Windows-latest virtual machine. The VM will build the project, and then it will execute the defined steps.
runs-on: windows-latest
Apart from Windows-latest, there are other runners too like ubuntu-latest, macos-latest, and self-hosted. The self-hosted runner is one that we can set up on our own infrastructure, such as our own server, or virtual machine, allowing us to have more control over the environment and resources.
Steps:
The steps are the description of what are the different actions required to perform on the project build. Here, the first action we are performing is to check out the repository so that it can have the latest build code.
steps:
- uses: actions/checkout@v3
Then we are setting up the Python. As this framework is an API automation testing framework using Python and Behave so we need Python to execute the tests.
- name: Set up Python
uses: actions/setup-python@v3
with:
python-version: '3.8.9'
After we install Python, we also need to install the different packages required to run the API tests. Define these packages in the requirement.txt file, and we can install them using the following command.
As of now, we have installed all the packages and we can now run our API tests. We are running these tests with the help of the allure behave command so that once the execution is completed it will generate a Report_Json folder which is required to generate the HTML report.
- name: run test
run: behave Features -f allure_behave.formatter:AllureFormatter -o Report_Json
working-directory: .
continue-on-error: true
Here, we cannot share the generated Report_Json folder as a report. To generate the shareable report we need to convert the JSON folder to that of the HTML report.
Please find the attached GitHub repository link. I have uploaded the same project to this repository and also attached a Readme file that explains the framework and the different commands we have used so far in this project. Also, the workflow explanation is included for better understanding.
Conclusion:
In conclusion, creating a CI/CD pipeline workflow for your project using GitHub Actions streamlines the development and testing process by automating tasks such as building the project for new changes, testing the build, and deploying the code. This results in reduced time and minimized errors, ensuring that your software performance is at its best.
GitHub Actions provides a wide range of pre-built actions and the ability to create custom actions that suit your requirements. By following established practices and continuously iterating on workflows, you can ensure your software delivery is optimized and reliable.
I hope in this blog I have provided the answers to the most commonly asked question and I hope this will help you to start creating your CI/CD pipelines for your projects. Do check out the blogs on how to create a BDD framework for Web Automation and API automation for a better understanding of automation frameworks and how a robust framework can be created.