API’s the term we heard a lot and wanted to know more about it. The questions that come to our mind are what is it? Why is it so important? How to test it? So, let’s just explore these questions one by one. API testing is accessible only if you know what to test and how to test. Again, a proper framework will help you to achieve your goals and deliver a good quality of work. The importance of automation framework and the factors we should consider for choosing the proper framework are described in our previous blog. Please go through the blog here, then you can start reading this blog because you will have a good understanding of automation testing frameworks.
To build the API testing framework we will be using the BDD approach. Again, why I have chosen a BDD framework for API testing the reason is very simple the BDD approach provides you with an easy understanding of the framework, you can easily maintain the framework and they have feature files that are very easy to understand for a non-technical person.
What is API?
API (Application Programming Interface) is like a mechanism that works between the two software components and helps them to communicate with each other. The communication happened using sets of definitions and set protocols. In simple language, API works as an intermediate between two systems and helps them exchange data and communicate. The working mechanism of Rest API is straightforward they work by sending requests and receiving a response in a standardized format. Usually, the standardized format used for Rest API is JSON i.e. (JavaScript Object Notation)
Let’s understand it better with an example. Consider you are using a ticket booking app to book a flight ticket. As the app is connected to the internet so it will set data to the server. When the server receives the data it interprets it and performs the required actions and sends it back to your device. Then the application translates that data and display the information in a readable way. So this is how API works. I hope you have understood the working mechanism of API’s now let’s discuss the next topic i.e.
What is API Testing?
As we have understood what is an API and how they work so let’s see why their testing is important. Basically, API testing is a part of software testing that includes the testing of the functionality, reliability, security, and performance of API. API is used for data transfer and to establish communication between the two systems so testing APIs includes verifying that the APIs are meeting its requirement, performing as per the expectations, and can handle a variety of inputs. This testing provides you the information that the API’s functionality is correct and efficient and the data they return is accurate and consistent.
Why is API Testing Important?
API testing is an important part of a Software testing process as it helps you to understand the functionality of the working APIs and validate any defect present before the application is released to the end users. The other key reasons why API testing is important to include:
Ensuring Functionality
Validating data integrity
Enhancing the Security
Improving the Performance
Detecting Bugs and Issues
Improving readability and stability
Facilitating integration and collaboration
All the above-mentioned points get checked and validate in API testing. Till now we have discussed what is api, what is api testing, and why it is important. Let’s see what different tools are available to conduct the manual as well as automation testing of API.
Tools for Manual API Testing:
Postman
SoapUI
Insomnia
Paw
Advanced REST Client (ARC)
Fiddler
cURL
Tools for API Automation Testing:
Postman
SoapUI
RestAssured
RestSharp
Apache HTTP client
JMeter
Karate
Newman
Pact.js
Cypress.js
These are just a few examples of the tools available for both manuals as well as automation testing of API. Each mentioned tool has its own strength and weakness and the choice of the right tool for your API testing depends upon the requirement and the specific needs of the project. These tools will help us to ensure that the APIs meet the desired functionality and performance requirements.
Now we are more familiar with APIs so let’s start the main topic of our discussion and i.e. Python Behave API Testing BDD Framework.
Framework Overview:
To validate all the above-mentioned points creating a robust API testing framework is very essential. With the help of the below-mentioned steps, you will come to know how to create your own API testing framework. Here, we are going to create a BDD framework. Please go through this blog before starting to read this blog as the previous blog will help you to understand the advantages of BDD and this blog is linked to the previous blog topics. You can read the previous blog here.
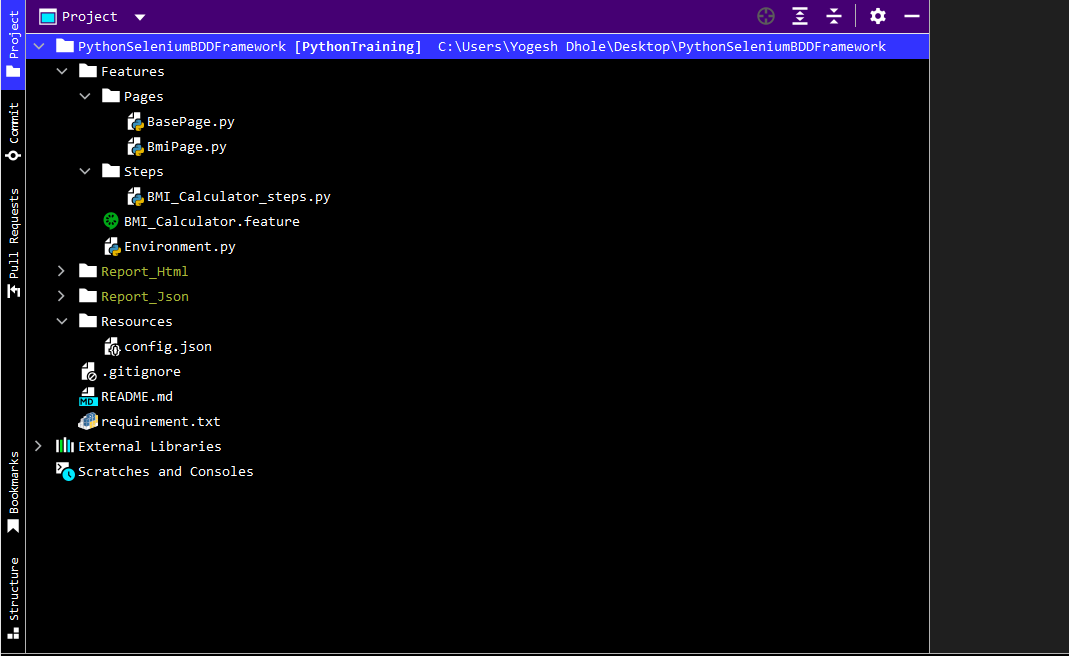
This framework structure contains a feature file, a step file, and a utility file. We will be discussing all these terms shortly. To create such a framework you need to follow certain steps to make your work tedious-free and easy.
Install all the required packages using the below command as long as you have all the packages mentioned in rquirement.txt with the right version number
We can also install the mentioned packages from the settings of Pycharm IDE
Step2: Creating Project
After understanding the prerequisites the next step is to create a project in our IDE. Here I am using a Pycharm Professional IDE. As mentioned in the above step, we will install the packages mentioned in the requirement.txt file. Please note it is not compulsory to use Pycharm Professional IDE to create this framework you can use the community version too.
Step3: Creating a Feature File
In this, we will be creating a feature file. A feature file consists of steps. These steps are mentioned in the gherkin language. The feature is easy to understand and can be written in the English language so that a non-technical person can understand the flow of the test scenario. In this framework we will be automating the four basic API request methods i.e. POST, PUT, GET and DELETE. We are taking https://reqres.in/
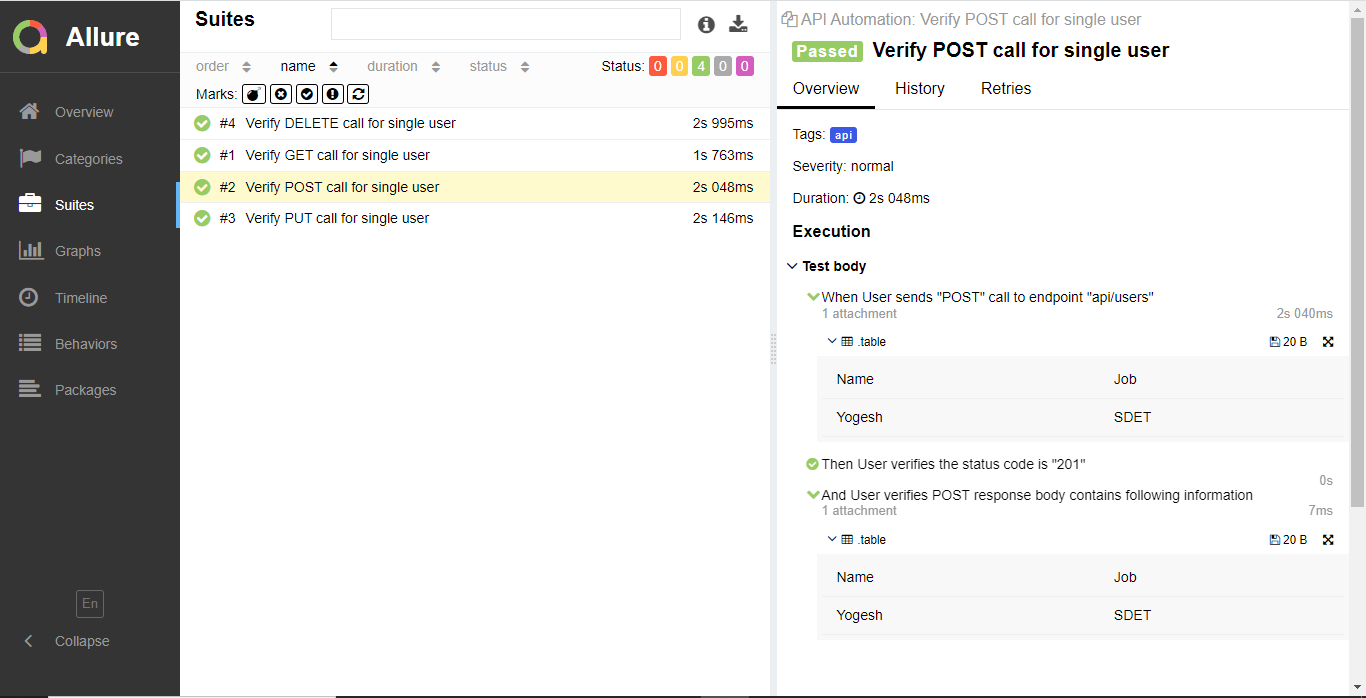
We can assign tags to our scenarios mentioned in the feature file to run particular test scenarios based on the requirement. The key point you must notice here is the feature file should end with .feature extension. We will be creating four different scenarios for the four different API methods.
Feature: User API
Verify the GET PUT POST DELETE methods of User API
@api
Scenario: Verify GET call for single user
When User sends "GET" call to endpoint "api/users/2"
Then User verifies the status code is "200"
And User verifies GET response contains following information
| First_name | Last_name | Mail-id |
| Janet | Weaver | janet.weaver@reqres.in |
@api
Scenario: Verify POST call for single user
When User sends "POST" call to endpoint "api/users"
| Name | Job |
| Yogesh | SDET |
Then User verifies the status code is "201"
And User verifies POST response body contains following information
| Name | Job |
| Yogesh | SDET |
@api
Scenario: Verify PUT call for single user
When User sends "PUT" call to endpoint "api/users/2"
| Name | Job |
| Yogesh | SDET |
Then User verifies the status code is "200"
And User verifies PUT response body contains following information
| Name | Job |
| Yogesh | SDET |
@api
Scenario: Verify DELETE call for single user
When User sends DELETE call to the endpoint "api/users/2"
Then User verifies the status code is "200"
Step4: Creating a Step File
Unlike the automation framework which we have built in the previous blog, we will be creating a single-step file for all the feature files. In the BDD framework, the step files are used to map and implement the steps described in the feature file. Python’s behave library is very accurate to map the steps with the steps described in the feature file. We will be describing the same steps in the step file as they have described in the feature file so that behave will come to know the step implementation for the particular steps present in the feature file.
from behave import *
from Utility.API_Utility import API_Utility
api_util = API_Utility()
@when('User sends "{method}" call to endpoint "{endpoint}"')
def step_impl(context, method, endpoint):
global response
response = api_util.Method_Call(context.table, method, endpoint)
@then('User verifies the status code is "{status_code}"')
def step_impl(context, status_code):
actual_status_code = response.status_code
assert actual_status_code == int(status_code)
@step("User verifies GET response contains following information")
def step_impl(context):
api_util.Verify_GET(context.table)
response_body = response.json()
assert response_body['data']['first_name'] == context.table[0][0]
assert response_body['data']['last_name'] == context.table[0][1]
assert response_body['data']['email'] == context.table[0][2]
@step("User verifies POST response body contains following information")
def step_impl(context):
api_util.Verify_POST(context.table)
response_body = response.json()
assert response_body['name'] == context.table[0][0]
assert response_body['job'] == context.table[0][1]
@step("User verifies PUT response body contains following information")
def step_impl(context):
api_util.Verify_PUT(context.table)
response_body = response.json()
assert response_body['Name'] == context.table[0][0]
assert response_body['Job'] == context.table[0][1]
@when('User sends DELETE call to the endpoint "{endpoint}"')
def step_impl(context, endpoint):
api_util.Delete_Call(endpoint)
Step5: Creating Utility File
Till now we have successfully created a feature file and a step file now in this step we will be creating a utility file. Generally, in Web automation, we have page files that contain the locators and the actions to perform on the web elements but in this framework, we will be creating a single utility file just like the step file. The utility file contains the API methods and the endpoints to perform the specific action like, POST, PUT, GET, or DELETE. The request body i.e. payload and the response body will be captured using the methods present in the utility file. So the reason these methods are created in the utility file is that we can use them multiple times and don’t have to create the same method over and over again.
import json
import requests
class API_Utility:
data = json.load(open("Resources/config.json"))
api_url = data["APIURL"]
global response
def Method_Call(self, table, method, endpoint):
if method == 'GET':
uri = self.api_url + endpoint
response = requests.request("GET", uri)
return response
if method == 'POST':
uri = self.api_url + endpoint
payload = {
"name": table[0][0],
"job": table[0][1]
}
response = requests.request("POST", uri, data=payload)
return response
if method == 'PUT':
uri = self.api_url + endpoint
reqbody = {
"Name": table[0][0],
"Job": table[0][1]
}
response = requests.request("PUT", uri, data=reqbody)
return response
def Get_Status_Code(self):
status_code = response.status_code
return status_code
def Verify_GET(self, table):
for row in table:
first_name = row['First_name']
last_name = row['Last_name']
email = row['Mail-id']
return first_name, last_name, email
def Verify_POST(self, table):
for row in table:
name = row['Name']
job = row['Job']
return name, job
#Following method can be merged with POST, however for simplicity I kept it
def Verify_PUT(self, table):
for row in table:
name = row['Name']
job = row['Job']
return name, job
def Delete_Call(self, endpoint):
uri = self.api_url + endpoint
response = requests.request("DELETE", uri)
return response
Step6: Create a Config file
A good tester is one who knows the use and importance of config files. In this framework, we are also going to use the config file. Here, we are just going to put the base URL in this config file and will be using the same in the utility file over and over again. The config file contains more data than just of base URL when you start exploring the framework and start automating the new endpoints then at some point, you will realize that some data can be added to the config file.
Additionally, the purpose of the config files is to make tests more maintainable and reusable. Another benefit of a config file is that it makes the code more modular and easier to understand as all the configuration settings are stored in a separate file and it makes it easier to update the configuration settings for all the tests at once.
"APIURL": "https://reqres.in/"
Step7: Execute and Generate Allure Report
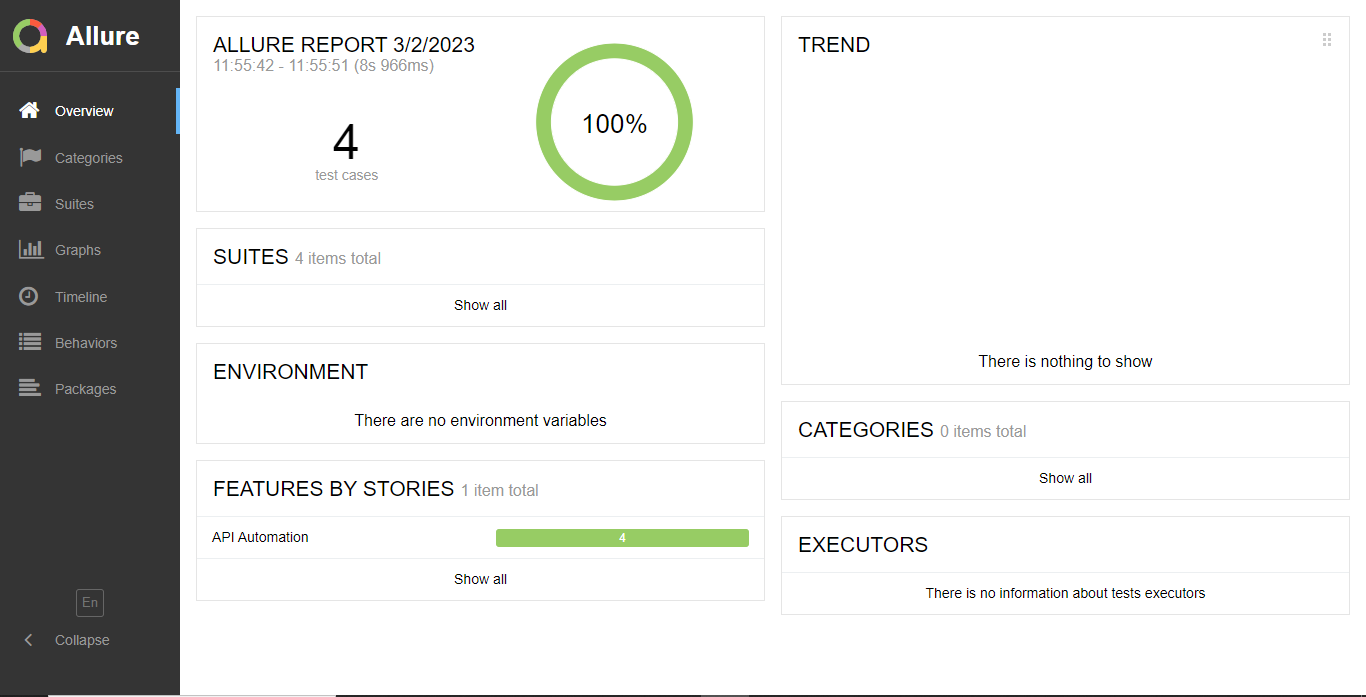
The reason behind using allure reports as a reporting medium is because the allure report provides detailed information about the test execution process and results which includes the test status, test steps, duration, and screenshots of the test run. The report is generated in HTML i.e. web format making it easy to share with team members and with clients and easy to understand. It provides a dashboard that is user-friendly having interactive charts and graphs that provide a detailed analysis of the test results.
Let’s understand how to execute API tests and generate an allure report for automated API calls. To generate the report we will have to execute the test using the terminal or command line. There are two steps to follow sequentially they are as follows:
The purpose of the above command is to execute the test present in the mentioned feature file and generate a JSON report folder.
allure generate Report_Json -o Report_Html –clean
This command is used to generate an HTML report from the JSON report. So, that it is easy to understand and can be shared with team members or clients.
Please find the attached GitHub repository link. I have uploaded the same project to this repository and also attached a Readme.md file which explains the framework and the different commands we have used so far in this project.
Before creating a framework it is very important to understand the concept and I hope I have provided enough information for the different queries on APIs. In conclusion, creating a BDD API testing framework using Python and Behave is easy to process if you know how to proceed further. By following the steps outlined in this blog I am sure you can create a powerful and flexible framework that will help you to define and execute the test cases, generate a detailed report with allure and also iterate with other testing tools and systems. Again I am suggesting you check out the previous blog here because that will clear most of your doubts on automation testing frameworks and will help you to create your own automation testing framework.
To deliver a good quality of work creating a robust software testing framework is a very important task. Every tester has his/her own approach or method to create a testing framework but the most common and important thing is creating a framework in such a manner that the other testers with minimal knowledge of automation testing can easily utilize the framework. While creating a framework there are some key points that we should consider you will find these points mentioned below.
A good tester is one who has the ability to create a good testing framework. In this blog, I have explained how to create an automation testing framework. Even a beginner with minimal knowledge of automation testing can use this approach to create his own testing framework. There are many more things that you can implement in this explained framework so feel free to comment on it.
When I started my journey as an SDET creating a framework was my first task assigned in my training so I can understand how important it is to create your own framework. Together in this blog, we will see the guidelines I have described which will help us to create a testing framework.
Before we jump into the main topic of our discussion let’s just quickly see the steps we will be following while creating our own framework.
Key Considerations When Creating an Automation Testing Framework:
Understanding the Requirements
Selecting a Testing Framework
Designing Test Cases
Implementing Test Cases
Executing Tests
Maintaining and Improving the Framework
Among the various frameworks present one of the most popular frameworks used for automation testing i.e. the combination of python’s behave library and selenium. In this blog, we are going to explore how to build and use this framework for our automation testing.
As everyone is familiar with Selenium which is an open source and one of the widely used tools for web automation testing along with Playwright and Cypress. Behave is a python library that is used for the BDD (Behavior Driven Development). Let’s just quickly explore what are the different frameworks present out there for automation testing.
A software automation testing framework is designed to make the process of testing software more efficient and easy to use. Every framework has its own advantages and disadvantages as per the given requirement it is most important for us to choose the right framework for automation. Below you will find some of the most commonly used and popular automation frameworks.
Types of Test Automation Frameworks:
Linear Scription Framework.
Modular Testing Framework.
Data-Driven Framework.
Keyword Driven Framework.
Hybrid Framework
Behavior Driven Development Framework.
Test Driven Development Framework.
In this blog, we will be building a BDD framework using Python’s behave library and selenium. In BDD we use the natural language to describe our test scenario divided into steps using the Gherkin language. These test scenarios are present in a feature file and because of the use of natural language, the behavior of the application is easily understandable by all. So, we can say that while creating a BDD framework one of the key components we should consider to use of the feature files and the step files.
As described earlier a feature file is written in natural language with the help of Gherkin language by following a set format. While a step file is an implementation of the steps present in the feature file. Here, a step file is a python file and we can see that it is full of a set of functions where those functions correspond to the steps described in the feature file. Now that we have seen what is feature file and step file let’s see what is the use of python’s behave library here, so basically once the steps and feature file are ready the behave will start automatically matching the steps present in the feature file with its corresponding implementation in the step file and will also check for any assertion errors present.
5. We can also install all the required packages using the requirement.txt file using the below command.
pip install -r requirement.txt
Framework Structure Overview:
Here is the overview of our python selenium behave BDD framework.
As a beginning, we are going to start with creating a simple framework using one scenario outline. In the next blog, we are going to see how to create an API testing framework using python. To understand both of them please read the blog carefully as I am explaining all the points here in natural language, without wasting any time let’s dive into the main topic of our discussion i.e. how to create python selenium behave BDD automation testing framework.
For this, we will follow some guidelines which I have described as steps.
Step 1:
Create a project in Pycharm (here I am using Pycharm professional) and as mentioned in the prerequisites install the packages.
It is not compulsory to use pycharm professional we can use pycharm community as well.
Step 2:
In this step, we will be creating a Features folder in which we will be creating our feature files for different scenarios. A feature file is something that holds your test cases in the form of a scenario and scenario outline. In this framework, we are using a scenario outline. Both scenario and scenario outline contain steps that are easy to understand for non-technical persons. We can also assign tags for the feature files and for the scenarios present in that file. Note that the feature file should end with a .feature extension.
Feature: Create test cases using Selenium with Python to automate below BMI calculator tests
# We are using Scenario Outline in this feature as we can add multiple input data using examples.
Scenario Outline: Calculating BMI value by passing multiple inputs
Given I enter the "<Age>"
When I Click on "<Gender>"
And I Enter a "<Height>"
And I Enter the "<Weight>"
And I Click on Calculate btn
And I Verify Result with "<Expected Result>"
Examples:
| Age | Gender | Height | Weight | Expected Result |
| 20 | Male | 180 | 60 | BMI = 18.5 kg/m2|
| 35 | Female | 160 | 55 | BMI = 21.5 kg/m2|
| 50 | Male | 175 | 65 | BMI = 21.2 kg/m2|
| 45 | Female | 150 | 52 | BMI = 23.1 kg/m2|
Step 3:
Now, we have our feature file let’s create a step file to implement the steps described in the feature file. In order to recognize the step file we are adding step work after the name so that behavior will come to know the step file for that particular feature file. Both feature files and step files are essential parts of the BDD framework. We have to be careful while describing the steps in the feature file because we have to use the same steps in the step file so that behavior will understand and map the step implementation.
from behave import *
# The step file contains the implementation of the steps that we have described in the feature file.
@given('I enter the "{Age}"')
def step_impl(context, Age):
context.bmipage.age_input(Age)
@when('I Click on "{Gender}"')
def step_impl(context, Gender):
context.bmipage.gender_radio(Gender)
@step('I Enter a "{height}"')
def step_impl(context, height):
context.bmipage.height_input(height)
@step('I Enter the "{weight}"')
def step_impl(context, weight):
context.bmipage.weight_input(weight)
@step("I Click on Calculate btn")
def step_impl(context):
context.bmipage.calculatebtn_click()
@step('I Verify Result with "{expresult}"')
def step_impl(context, expresult):
context.bmipage.result_validation(expresult)
Step 4:
In step 4 we will be creating a page file that contains all the locators and the action methods to perform the particular action on the web element. We are going to add all the locators at the class level only and will be using them in the respective methods. The reason behind doing so is it is a good practice to declare your locators at the class level as when the locators get changed it is effortless to replace them and we don’t have to go through the whole code again.
from selenium.webdriver.common.by import By
import time
from Features.Pages.BasePage import BasePage
# The page contains all the locators and the actions to perform on that web element.
# In this page file we have declared all the locators at the class level and we are using them in the respective methods.
class BmiPage (BasePage):
def __init__(self, context):
BasePage.__init__(self, context.driver)
self.context = context
self.age_xpath = "//input[@id='cage']"
self.height_xpath = "//input[@id='cheightmeter']"
self.weight_xpath = "//input[@id='ckg']"
self.calculatebtn_xpath = "//input[@value='Calculate']"
self.actual_result_xpath = "//body[1]/div[3]/div[1]/div[4]/div[1]/b[1]"
def age_input(self, Age):
AgeInput = self.driver.find_element(By.XPATH, self.age_xpath)
AgeInput.clear()
AgeInput.send_keys(Age)
time.sleep(2)
def gender_radio(self, Gender):
SelectGender = self.driver.find_element(By.XPATH, "//label[normalize-space()='" + Gender+"']")
SelectGender.click()
time.sleep(2)
def height_input(self, height):
HeightInput = self.driver.find_element(By.XPATH, self.height_xpath)
HeightInput.clear()
HeightInput.send_keys(height)
time.sleep(3)
def weight_input(self, weight):
WeightInput = self.driver.find_element(By.XPATH, self.weight_xpath)
WeightInput.clear()
WeightInput.send_keys(weight)
time.sleep(3)
def calculatebtn_click(self):
Calculatebtn = self.driver.find_element(By.XPATH, "//input[@value='Calculate']")
Calculatebtn.click()
time.sleep(3)
def result_validation(self, expresult):
try:
Result = self.driver.find_element(By.XPATH, "//body[1]/div[3]/div[1]/div[4]/div[1]/b[1]")
Actualresult = Result.text
Expectedresult = expresult
assert Actualresult == Expectedresult, "Expected Result Matched"
time.sleep(5)
except:
self.driver.close()
assert False, "Expected Result mismatched"
The next one is the base page file. We are creating a base page file to make an object of the driver so that we can easily use that for our page and environment file.
from selenium.webdriver.support.wait import WebDriverWait
# In the base page we are creating an object of driver.
# We are using this driver in the other pages and environment page.
class BasePage(object):
def __init__(self, driver):
self.driver = driver
self.wait = WebDriverWait(self.driver, 30)
self.implicit_wait = 25
Step 5:
This step is very important because we will be creating an environment file (i.e. Hooks file). This file contains hooks for before and after scenarios to start and close the browser. Also if you want you can add after-step hooks for capturing screenshots for reporting. We have added a method to capture screenshots after every step and will attach them to the allure report.
import json
import time
from allure_commons._allure import attach
from allure_commons.types import AttachmentType
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from Pages.BasePage import BasePage
from Pages.BmiPage import BmiPage
data = json.load(open("Resources/config.json"))
# This environment page is used as hooks page. Here we can notice that we have used before, after hooks along side with some step hooks.
def before_scenario(context, scenario):
context.driver = webdriver.Chrome(ChromeDriverManager().install())
time.sleep(5)
basepage = BasePage(context.driver)
context.bmipage = BmiPage(basepage)
context.stepid = 1
context.driver.get(data['BMIWEBURL'])
context.driver.maximize_window()
context.driver.implicitly_wait(3)
def after_step(context, step):
attach(context.driver.get_screenshot_as_png(), name=context.stepid, attachment_type=AttachmentType.PNG)
context.stepid = context.stepid + 1
def after_scenario(context, scenario):
context.driver.close()
Step 6:
It is a good practice to store all our common data and files in a resource folder. So, whenever we need to make changes it will be easy to implement them for the whole framework. For now, we are adding a config.json file in the resource folder. This file contains the web URL used before the scenario to launch the web page for the specified tag in the feature file. The file is written in JSON format.
Congratulations, finally we have created our own Python Selenium Behave BDD framework. As I mentioned earlier we will be using Allure for reporting the test result. For this use the below command in the terminal and it will generate the result folder for you.
Creating a testing framework is very important as well as feels like a tedious task but with the right guidelines, everyone can create a testing framework. I hope in this blog I have provided all the answers related to the python selenium behavior automation testing framework. Here, we choose a BDD framework over other existing frameworks because of its better understanding, easy to adapt, and easy to understand for end users. If you still have any issues related to what we have seen earlier feel free to comment them down we will solve them together. There are many more things we can add to this existing framework but to get started I feel this framework is enough and will cover most of the requirements.
Hello! In this blog, I will be exploring how to automate tests using Taiko with Cucumber in JavaScript. The Taiko tool is easy to automate and is very reliable, and it works faster to execute and run test cases. It is a user-friendly tool as well.
What is Takio?
A Taiko is an automation tool that is available for free and it is an open-source browser automation tool. It is built by the ThoughtWorks team. It uses the Node.js library to automate the chrome browser. Taiko is very useful to create maintainable and highly readable JavaScript tests.
Taiko Features:
The Taiko was explicitly built to test modern web applications.
The features of Taiko that set it apart from other browser automation solutions are listed below.
Easy Installation
Interactive Recorder
Smart Selectors
Handle XHR and dynamic content
Request/Response stubbing and mocking
We can use Taiko on three platforms:
Windows
macOS
Linux
How to install Taiko?
A Taiko is available on npm: You can use the following NPM command to install the taiko on your system.
npm install -g taiko
What is cucumber?
A Cucumber is a testing tool that allows BDD. It offers a way to write tests that everyone, regardless of technical ability, can follow. Before developers build their code in BDD, users (business analysts, product owners) first write scenarios or acceptance tests that describe the system behavior from the perspective of the customer. Such scenarios and acceptance tests then are reviewed and approved by the product owners.
How to install Cucumber?
Basically, cucumber is available on npm: You can use the following NPM command to install the cucumber on your system.
npm install --save-dev @cucumber/cucumber
Getting Started
We will be using Visual Studio code to write our test automation code in JavaScript. We will create a feature file first, then click on the left side of the panel and choose “new file” from the menu that appears. Give a file name after that, such as the Calculator. feature
I’ll start out by introducing the Taiko framework, which integrates BDD and Cucumber. You will be guided through the code in the next step.
Feature: Calculator operations
@smoke
Scenario: Addition of 2 numbers
Given I launch calculator application
When I click on number 2
And I click on operator +
And I click on number 2
Then I verify the result is 4
I’ll describe how to automate the calculator page in this place. The code shown below builds calculator steps where we must import statements provided by cucumber before navigating to the support folder.
After that, we can import the cucumber and assertion statements and that will build a page where all the steps are generally placed.
Basically, this is the step definition file where we need to map the feature file steps and call methods declared in the page file.
After that, we have to import the page file in the step definition file. And we need to call the methods declared in the page file.
Following is the code snippet for the step definition file.
const { Given, When, Then } = require('@cucumber/cucumber')
const calculate = require('../../pages/calculatorPage')
Given('I launch calculator application', async function () {
await new calculate().launch()
})
When('I click on number {string}', async function (num) {
await new calculate().click_number(num)
})
When('I click on operator {string}', async function (num) {
await new calculate().click_operator(num)
})
Then('I verify the result is {string}', async function (num) {
await new calculate().verify_result(num)
})
Now let’s create a page(We are using Page Object Model (POM) structure here) file where we have to declare the class and all the methods cleaning in step definitions.
And, In the above code snippet, methods contain actions like opening the browser, visiting a website, CSS selectors and actions to be performed on it (click), and Assertions. You may notice that we are doing open browser and close browser actions into this page file itself which is not the best practice. You can move it to Before/After hooks and create a nice framework. However, that is for a later blog 🙂
So, to execute the test case, you can run the following command from the terminal.
npx cucumber-js --publish
Happy testing !!!
Conclusion:
We can automate tests using taiko with Cucumber with JavaScript very easily. Taiko is a very powerful tool and easy to implement. It will definitely compete with Selenium and Playwright in the coming years.
By profession an Automation Test Engineer, Having 3+year experience in Manual and automation testing. Having hands-on experience in Cypress with JavaScript, NodeJS. Designed automation web framework in Cypress, Webdriver.io, Selenium with jest in JavaScript. He loves to explore and learn new tools and technologies.