
How to download a File using Python and Selenium
This article provides you with a solution for downloading a file using python and selenium in a folder. Handling files can be a tedious task at times. Especially, when you have test scenarios like downloading a file and verifying if the file is downloaded and if yes then delete the downloaded file.
Despite visiting many websites and reading many articles, I was not able to find the right solution. Here, I am providing all the solutions in one place, as visiting multiple web pages to find a single solution is tiring. Here, we are using the python and selenium combination to download a file in a folder. You can use the language you like for example, java, javascript, c#, etc. After reading this article, you will get to know how you can handle this type of scenario and we will solve this issue together. So just follow the steps described.
Traditional Approach:

When you download any file from the website it generally gets downloaded in your download folder i.e. on your local system, but here, is what we are doing we are creating a folder download in our framework. Then we download that file in this newly created folder.
Till this point, I assume you have understood the test scenario and also we will be passing the file name to delete the particular file. Also, to verify whether the particular file is getting downloaded or not.
It would help if you imported some packages of python and selenium they have listed below.
To change the download folder path from our local system to the framework folder we need to add some script here, that will set the new download folder as our default folder, to download the files from the webpage.
Step1:
Import the following packages.
from selenium import webdriver
import os
From selenium.webdriver.common.by import By
From webdriver_manager.chrome import ChromeDriverManagerAfter adding the above imports now we will have to change the path to do so see the script and you will get an idea.
op = webdriver.ChromeOptions()
op.add_argument('--no-sandbox')
op.add_argument('--verbose')
op.add_argument("--disable-notifications")
op.add_experimental_option("prefs", {
"download.default_directory": "G:/Python/Download/",
"download.prompt_for_download": False,
"download.directory_upgrade": True,
"safebrowsing.enabled": True})
op.add_argument('--disable-gpu')
op.add_argument('--disable-software-rasterizer')Now we have set the download path to our new folder now we have to set the driver.
Step2:
Here, I have used the web driver manager you can use the chrome driver and provide the path if you want to. But, I suggest using web driver manager, as it is a good practice to use. Because it will download all the updated chrome driver versions automatically and you will save lots of your time.
driver = webdriver.Chrome(ChromeDriverManager().install(), chrome_options=op)I hope no one has any problems or doubts till this point, as these steps are crucial and if you have any doubts go through the steps again. Now you can launch your webpage URL.
Step3:
Here, I want you to write your script to locate the web element and click on that element for example refer to the following scrip
driver.find_element(By.XPATH, “//span[@type = ‘button’]”).click()After clicking, the file will get downloaded in the new download folder that we have created in our framework.
Step4:
The next step is to see if the file is present in the newly created download folder. In order to achieve this just go through the following script.
def download_file_verify(self,filename):
dir_path = "G:/Python/Download/"
res = os.listdir(dir_path)
try:
name = os.path.isfile("Download/" + res[0])
if res[0].__contains__(filename):
print("file downloaded successfully")
except "file is not downloaded":
name = False
return nameHere, you can provide the name of your downloaded file to the filename argument to avoid the hard coding of the script, as it is not a good practice.

Explanation:
For instance, the name of my downloaded file is extent report so now the value of the filename argument becomes extent report.
So, first of all, it will go to the directory path we have provided now it will store all the file names already present in the folder in a list format.
Here we have stored that list in the res variable. Now we can iterate over the list and verify if our desired file is present in the folder or not.
Take note here, that the newly downloaded file will always be present in the zeroth index of our download folder. That is why we have used res[0] to check, if the downloaded file is present at the zeroth index or not.
Now, it will check if the zeroth index file name is equal to that of the name of the file we have provided. So, if yes then it will print(“file downloaded successfully”), and if not then it will throw an exception and will print(“file is not downloaded”)
Here I have used assertion to verify whether the file is downloaded or not. I will suggest you use the same as it is good practice. You will get to know the assertion while handling the file.
Congratulations, we are done with the first part. We have successfully downloaded the file in the newly created download folder. We have also verified whether the file is downloaded or not.
Step5:
The next task is to delete the downloaded file by passing the name of the file. So, let’s get started then.
Script to delete the file from the download folder by passing the name of the file.
def delete_previous_file(self,filename):
try:
d_path = "G:/Python/Download/"
list = os.listdir(d_path)
for file in list:
print("present file is: " + file)
path = ("Download/" + file)
if file.__contains__(filename):
os.remove(path)
print("Present file is deleted")
except:
passExplanation:
Here, we don’t have to only delete the file that is present at the zeroth index. But we have to delete all the files present in the download folder with the same file name. So, that when a new file gets downloaded there will be only one file present.
So the above code will first go to the directory path. Store all the file names present as a list. So, now we have to iterate over that list and see if the same file is present. If yes then we have to delete that file.
Use try and except block. Here, if there is no file present, then our code will not raise any exceptions or will fail.
Congratulations now we have successfully completed the file handling with selenium python.
Output:
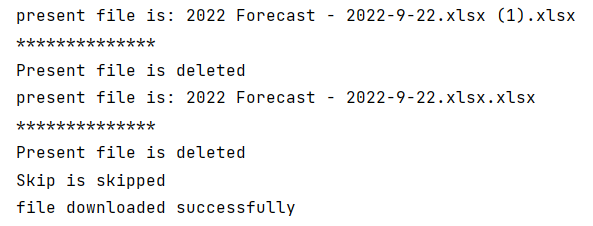
If you have any queries comment them down. We will solve that problem together like we just solved one. Also, if you have any suggestions then let me know. I will implement that in our next article. Also, don’t forget to share the article with your friends. Follow our pages on LinkedIn, Instagram, and Facebook. and subscribe to our blog. So, whenever we post some amazing content you will get to know it and, you will not have to wait for it.
For Reference: https://pynative.com/python/file-handling/
Conclusion:
In my opinion, validation of file downloading at a particular location is a very easy process. Only, if you have the right solution for reference. In this article, I am sure I have provided the right solution for all your file-downloading problems and validations.
Top-Tier SDET | Advanced in Manual & Automated Testing | Skilled in Full-Spectrum Testing & CI/CD | API & Mobile Automation | Desktop App Automation | ISTQB Certified