To ensure comprehensive mobile app testing, it is essential to do 360-degree testing for functions, appearance, and performance on multiple devices with various configurations, sizes, resolutions, and platforms.
There are three ways to conduct mobile app testing:
Emulators for Android devices and Simulators for iOS devices
Real physical devices
Cloud-based real devices platform
Testing an application on different platforms, including emulators and simulators, as well as physical devices, comes with a set of challenges.
Emulators and Simulators:
When it comes to emulators and simulators, creating multiple virtual devices with different configurations can be difficult, and they may not accurately replicate real-world situations compared to physical devices.
Physical devices:
On the other hand, testing on physical devices poses its own set of difficulties. It requires a large number of devices to test app compatibility with different configurations, and the list of devices keeps changing as new models are introduced to the market. Additionally, cross-location testing can be challenging since carrying multiple devices across different locations can be cumbersome.
To address these challenges, a possible solution is to use cloud-based platforms for testing applications in real-world conditions. By doing so, we can perform robust testing with a variety of devices and configurations without the need to physically acquire and maintain them.
Cloud-based platform (BrowserStack) :
BrowserStack is a cloud-based real devices platform that provides support for both manual and automated testing of mobile apps for both Android and iOS devices.
One of its standout features is the App Live feature, which allows users to manually test their mobile apps on over 3000 real Android and iOS devices.
BrowserStack also supports 15+ native features, such as GPS, network simulation, and localization, which can be used to test mobile apps in real-world scenarios.
Other features include debugging apps, viewing crash reports and logs, inspecting UI elements, and using stack traces to find and fix bugs instantly. These features make it easy for developers to identify and fix issues quickly and efficiently.
Furthermore, BrowserStack supports testing across different environments, including Dev, QA, Staging, and Production apps from the play store or app store. This makes it easy for developers to test their apps in various environments and ensure that they are working correctly in each environment.
To test a mobile app on BrowserStack, follow these steps:
4. Here in the left panel “SELECT SOURCE” you can see different options available to upload or install apps.
i. Uploaded Apps – You can upload an apk or ipa file here.
ii. Sync with App Centre – If you have access to the app center you can use this option to directly install the app from App Centre.
iii. Install via TestFlight – While testing on iOS devices you can install the app directly from TestFlight also.
iv. Install via Play Store – Select a device, sign in to the play store and install the app if available on Play Store.
v. Install via App Store – Select a device, sign in to the App store and install an app, if available on App Store.
Now let’s explore how to upload apk file from a local machine using Upload Apps here…
i. Click on Upload – Select apk/ipa file from your local machine to be uploaded.
ii. Select the uploaded apk/ipa file and device from the list of available devices in the right panel.
iii. You can select any device from the list for the selected device category.
iv. Once you click on the device name the device will be launched and the app will be installed on it.
Now once the app is launched on the selected device you can start testing the app.
Let’s explore various features that can be used effectively while testing…
1. Report Bug:
If you find a bug while testing, BrowserStack provides the option to highlight the bug on the screen and add a bug description.
You can download the image to include it in the defect report later or send a screenshot to the developer or your team via email.
Additionally, you can share the image using various applications such as Jira, Slack, GitHub, etc. This option is visible in the screenshot below.
Then click on Cancel to return back to the testing screen.
2. Record Session:
This feature can capture a video recording of a sequence of events that led to a bug.
Choose the screen to be recorded.
After recording a session using BrowserStack, you can stop the sharing by clicking on the “Stop Sharing” button. Then, you can download the recording for later use.
3. Switch Device
This feature allows users to switch to another device at any point in time to test the same app on different devices.
The toolbar on the right side of BrowserStack provides various features to simulate real device features, including:
View open apps on the device.
Kill existing apps if they become unresponsive or test app behavior on a relaunch.
Capture screenshots, similar to taking screenshots on a physical phone.
Rotate the screen to test the app’s responsiveness to different screen orientations.
Some other important features are:
Change Location: This feature is used to test app behavior and response across different geographical locations. You can use the “Device GPS” option to set the exact latitude and longitude coordinates or the “IP Location (Beta)” option to select a specific region from a list of locations. See the screenshot below for reference.
Change Language – This feature can be used to test apps in different languages.
File & Media – This feature allows you to transfer various types of files to and from the device during testing.
On the right-hand side of the window, we have the following options in the Dev Tools section:
INSPECT (BETA) –This option is used to find element locators for app automation testing.
NETWORK Tab – This feature is useful for monitoring backend HTTP requests and responses in real-time. It can help you to debug the cause of failures during certain events in the app.
On the BrowserStack cloud platform, you can also test various native device features just like physical devices. These include:
Geolocation testing
Push notifications
Pre-loaded images
Network simulation
Testing dependent apps
Uninstalling apps
Conclusion:
Overall, BrowserStack is a convenient and easy-to-use cloud-based real devices platform that provides a wide range of features for mobile app testing. Its support for manual and automated testing, along with its native features and ability to test across different environments, makes it a popular choice among developers.
Manisha is a Lead SDET at SpurQLabs with overall experience of 3.5 years in UI Test Automation, Mobile test Automation, Manual testing, database testing, API testing and CI/CD. Proven expertise in creating and maintaining test automation frameworks for Mobile, Web and Rest API in Java, C#, Python and JavaScript.
API’s the term we heard a lot and wanted to know more about it. The questions that come to our mind are what is it? Why is it so important? How to test it? So, let’s just explore these questions one by one. API testing is accessible only if you know what to test and how to test. Again, a proper framework will help you to achieve your goals and deliver a good quality of work. The importance of automation framework and the factors we should consider for choosing the proper framework are described in our previous blog. Please go through the blog here, then you can start reading this blog because you will have a good understanding of automation testing frameworks.
To build the API testing framework we will be using the BDD approach. Again, why I have chosen a BDD framework for API testing the reason is very simple the BDD approach provides you with an easy understanding of the framework, you can easily maintain the framework and they have feature files that are very easy to understand for a non-technical person.
What is API?
API (Application Programming Interface) is like a mechanism that works between the two software components and helps them to communicate with each other. The communication happened using sets of definitions and set protocols. In simple language, API works as an intermediate between two systems and helps them exchange data and communicate. The working mechanism of Rest API is straightforward they work by sending requests and receiving a response in a standardized format. Usually, the standardized format used for Rest API is JSON i.e. (JavaScript Object Notation)
Let’s understand it better with an example. Consider you are using a ticket booking app to book a flight ticket. As the app is connected to the internet so it will set data to the server. When the server receives the data it interprets it and performs the required actions and sends it back to your device. Then the application translates that data and display the information in a readable way. So this is how API works. I hope you have understood the working mechanism of API’s now let’s discuss the next topic i.e.
What is API Testing?
As we have understood what is an API and how they work so let’s see why their testing is important. Basically, API testing is a part of software testing that includes the testing of the functionality, reliability, security, and performance of API. API is used for data transfer and to establish communication between the two systems so testing APIs includes verifying that the APIs are meeting its requirement, performing as per the expectations, and can handle a variety of inputs. This testing provides you the information that the API’s functionality is correct and efficient and the data they return is accurate and consistent.
Why is API Testing Important?
API testing is an important part of a Software testing process as it helps you to understand the functionality of the working APIs and validate any defect present before the application is released to the end users. The other key reasons why API testing is important to include:
Ensuring Functionality
Validating data integrity
Enhancing the Security
Improving the Performance
Detecting Bugs and Issues
Improving readability and stability
Facilitating integration and collaboration
All the above-mentioned points get checked and validate in API testing. Till now we have discussed what is api, what is api testing, and why it is important. Let’s see what different tools are available to conduct the manual as well as automation testing of API.
Tools for Manual API Testing:
Postman
SoapUI
Insomnia
Paw
Advanced REST Client (ARC)
Fiddler
cURL
Tools for API Automation Testing:
Postman
SoapUI
RestAssured
RestSharp
Apache HTTP client
JMeter
Karate
Newman
Pact.js
Cypress.js
These are just a few examples of the tools available for both manuals as well as automation testing of API. Each mentioned tool has its own strength and weakness and the choice of the right tool for your API testing depends upon the requirement and the specific needs of the project. These tools will help us to ensure that the APIs meet the desired functionality and performance requirements.
Now we are more familiar with APIs so let’s start the main topic of our discussion and i.e. Python Behave API Testing BDD Framework.
Framework Overview:
To validate all the above-mentioned points creating a robust API testing framework is very essential. With the help of the below-mentioned steps, you will come to know how to create your own API testing framework. Here, we are going to create a BDD framework. Please go through this blog before starting to read this blog as the previous blog will help you to understand the advantages of BDD and this blog is linked to the previous blog topics. You can read the previous blog here.
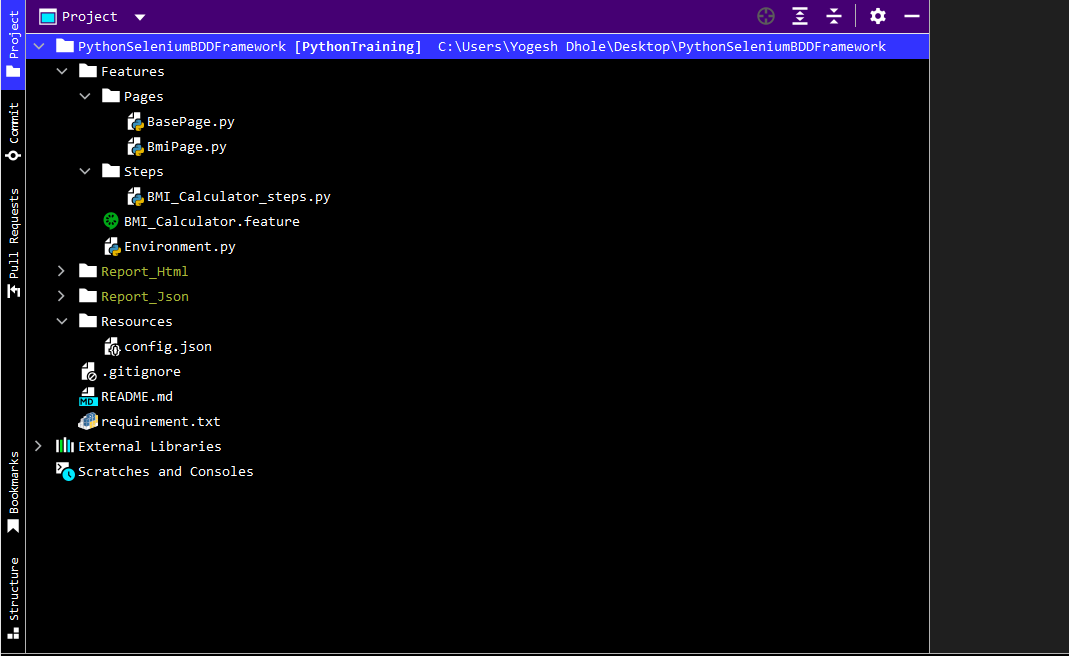
This framework structure contains a feature file, a step file, and a utility file. We will be discussing all these terms shortly. To create such a framework you need to follow certain steps to make your work tedious-free and easy.
Install all the required packages using the below command as long as you have all the packages mentioned in rquirement.txt with the right version number
We can also install the mentioned packages from the settings of Pycharm IDE
Step2: Creating Project
After understanding the prerequisites the next step is to create a project in our IDE. Here I am using a Pycharm Professional IDE. As mentioned in the above step, we will install the packages mentioned in the requirement.txt file. Please note it is not compulsory to use Pycharm Professional IDE to create this framework you can use the community version too.
Step3: Creating a Feature File
In this, we will be creating a feature file. A feature file consists of steps. These steps are mentioned in the gherkin language. The feature is easy to understand and can be written in the English language so that a non-technical person can understand the flow of the test scenario. In this framework we will be automating the four basic API request methods i.e. POST, PUT, GET and DELETE. We are taking https://reqres.in/
We can assign tags to our scenarios mentioned in the feature file to run particular test scenarios based on the requirement. The key point you must notice here is the feature file should end with .feature extension. We will be creating four different scenarios for the four different API methods.
Feature: User API
Verify the GET PUT POST DELETE methods of User API
@api
Scenario: Verify GET call for single user
When User sends "GET" call to endpoint "api/users/2"
Then User verifies the status code is "200"
And User verifies GET response contains following information
| First_name | Last_name | Mail-id |
| Janet | Weaver | janet.weaver@reqres.in |
@api
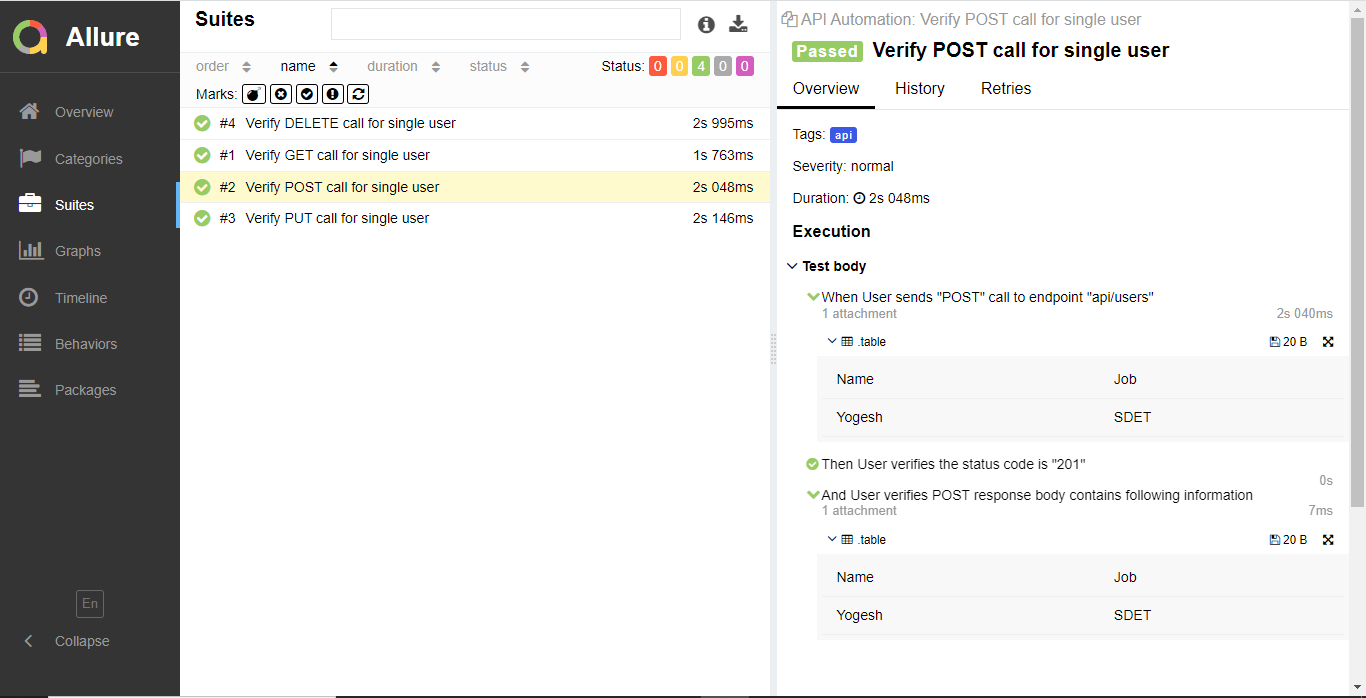
Scenario: Verify POST call for single user
When User sends "POST" call to endpoint "api/users"
| Name | Job |
| Yogesh | SDET |
Then User verifies the status code is "201"
And User verifies POST response body contains following information
| Name | Job |
| Yogesh | SDET |
@api
Scenario: Verify PUT call for single user
When User sends "PUT" call to endpoint "api/users/2"
| Name | Job |
| Yogesh | SDET |
Then User verifies the status code is "200"
And User verifies PUT response body contains following information
| Name | Job |
| Yogesh | SDET |
@api
Scenario: Verify DELETE call for single user
When User sends DELETE call to the endpoint "api/users/2"
Then User verifies the status code is "200"
Step4: Creating a Step File
Unlike the automation framework which we have built in the previous blog, we will be creating a single-step file for all the feature files. In the BDD framework, the step files are used to map and implement the steps described in the feature file. Python’s behave library is very accurate to map the steps with the steps described in the feature file. We will be describing the same steps in the step file as they have described in the feature file so that behave will come to know the step implementation for the particular steps present in the feature file.
from behave import *
from Utility.API_Utility import API_Utility
api_util = API_Utility()
@when('User sends "{method}" call to endpoint "{endpoint}"')
def step_impl(context, method, endpoint):
global response
response = api_util.Method_Call(context.table, method, endpoint)
@then('User verifies the status code is "{status_code}"')
def step_impl(context, status_code):
actual_status_code = response.status_code
assert actual_status_code == int(status_code)
@step("User verifies GET response contains following information")
def step_impl(context):
api_util.Verify_GET(context.table)
response_body = response.json()
assert response_body['data']['first_name'] == context.table[0][0]
assert response_body['data']['last_name'] == context.table[0][1]
assert response_body['data']['email'] == context.table[0][2]
@step("User verifies POST response body contains following information")
def step_impl(context):
api_util.Verify_POST(context.table)
response_body = response.json()
assert response_body['name'] == context.table[0][0]
assert response_body['job'] == context.table[0][1]
@step("User verifies PUT response body contains following information")
def step_impl(context):
api_util.Verify_PUT(context.table)
response_body = response.json()
assert response_body['Name'] == context.table[0][0]
assert response_body['Job'] == context.table[0][1]
@when('User sends DELETE call to the endpoint "{endpoint}"')
def step_impl(context, endpoint):
api_util.Delete_Call(endpoint)
Step5: Creating Utility File
Till now we have successfully created a feature file and a step file now in this step we will be creating a utility file. Generally, in Web automation, we have page files that contain the locators and the actions to perform on the web elements but in this framework, we will be creating a single utility file just like the step file. The utility file contains the API methods and the endpoints to perform the specific action like, POST, PUT, GET, or DELETE. The request body i.e. payload and the response body will be captured using the methods present in the utility file. So the reason these methods are created in the utility file is that we can use them multiple times and don’t have to create the same method over and over again.
import json
import requests
class API_Utility:
data = json.load(open("Resources/config.json"))
api_url = data["APIURL"]
global response
def Method_Call(self, table, method, endpoint):
if method == 'GET':
uri = self.api_url + endpoint
response = requests.request("GET", uri)
return response
if method == 'POST':
uri = self.api_url + endpoint
payload = {
"name": table[0][0],
"job": table[0][1]
}
response = requests.request("POST", uri, data=payload)
return response
if method == 'PUT':
uri = self.api_url + endpoint
reqbody = {
"Name": table[0][0],
"Job": table[0][1]
}
response = requests.request("PUT", uri, data=reqbody)
return response
def Get_Status_Code(self):
status_code = response.status_code
return status_code
def Verify_GET(self, table):
for row in table:
first_name = row['First_name']
last_name = row['Last_name']
email = row['Mail-id']
return first_name, last_name, email
def Verify_POST(self, table):
for row in table:
name = row['Name']
job = row['Job']
return name, job
#Following method can be merged with POST, however for simplicity I kept it
def Verify_PUT(self, table):
for row in table:
name = row['Name']
job = row['Job']
return name, job
def Delete_Call(self, endpoint):
uri = self.api_url + endpoint
response = requests.request("DELETE", uri)
return response
Step6: Create a Config file
A good tester is one who knows the use and importance of config files. In this framework, we are also going to use the config file. Here, we are just going to put the base URL in this config file and will be using the same in the utility file over and over again. The config file contains more data than just of base URL when you start exploring the framework and start automating the new endpoints then at some point, you will realize that some data can be added to the config file.
Additionally, the purpose of the config files is to make tests more maintainable and reusable. Another benefit of a config file is that it makes the code more modular and easier to understand as all the configuration settings are stored in a separate file and it makes it easier to update the configuration settings for all the tests at once.
"APIURL": "https://reqres.in/"
Step7: Execute and Generate Allure Report
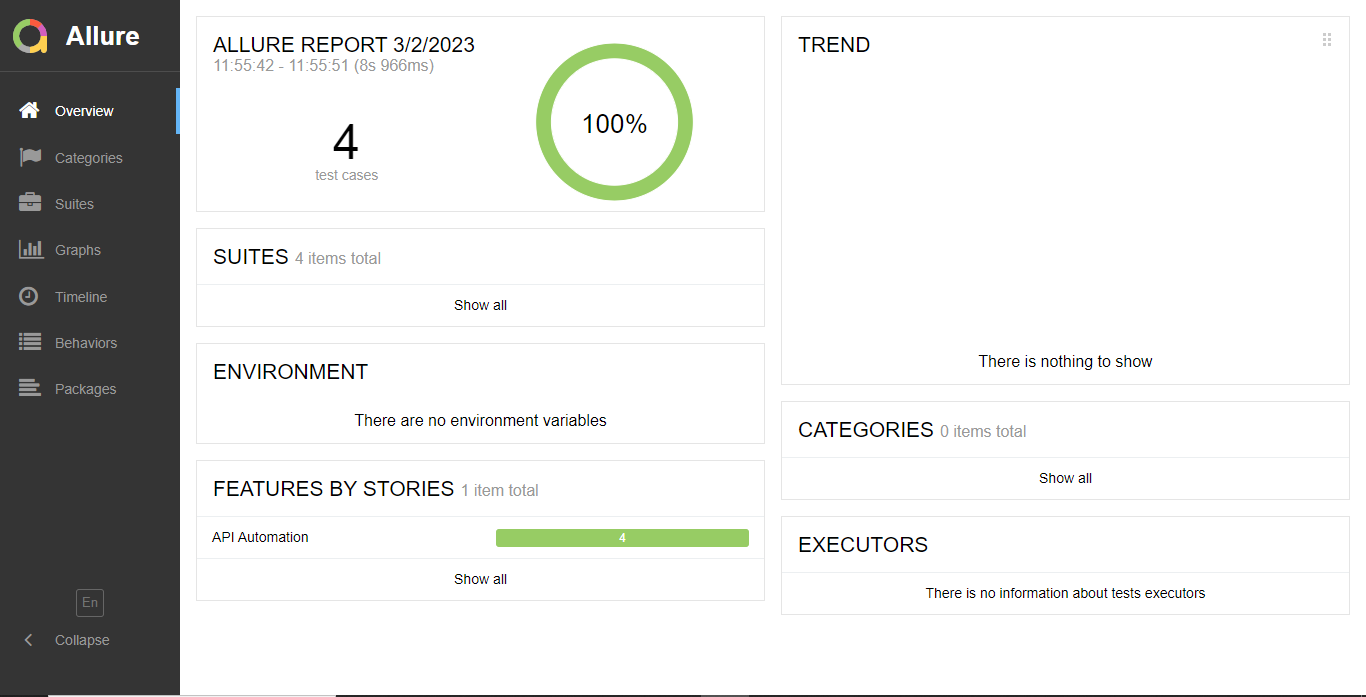
The reason behind using allure reports as a reporting medium is because the allure report provides detailed information about the test execution process and results which includes the test status, test steps, duration, and screenshots of the test run. The report is generated in HTML i.e. web format making it easy to share with team members and with clients and easy to understand. It provides a dashboard that is user-friendly having interactive charts and graphs that provide a detailed analysis of the test results.
Let’s understand how to execute API tests and generate an allure report for automated API calls. To generate the report we will have to execute the test using the terminal or command line. There are two steps to follow sequentially they are as follows:
The purpose of the above command is to execute the test present in the mentioned feature file and generate a JSON report folder.
allure generate Report_Json -o Report_Html –clean
This command is used to generate an HTML report from the JSON report. So, that it is easy to understand and can be shared with team members or clients.
Please find the attached GitHub repository link. I have uploaded the same project to this repository and also attached a Readme.md file which explains the framework and the different commands we have used so far in this project.
Before creating a framework it is very important to understand the concept and I hope I have provided enough information for the different queries on APIs. In conclusion, creating a BDD API testing framework using Python and Behave is easy to process if you know how to proceed further. By following the steps outlined in this blog I am sure you can create a powerful and flexible framework that will help you to define and execute the test cases, generate a detailed report with allure and also iterate with other testing tools and systems. Again I am suggesting you check out the previous blog here because that will clear most of your doubts on automation testing frameworks and will help you to create your own automation testing framework.
What if we could catch a bug during the requirements analysis stage? It would not only save time, but it could also save costs for the organization. There’s a powerful, free, and open-source tool called Xmind that can help us create Mind Maps, which can be highly effective for this purpose. By using mind mapping, we can identify test scenarios and get an accurate algorithm of the product flow, which is essential for requirements analysis.
To start, let’s gain a deep understanding of the expected flow of the application, and use mind mapping to help identify and clear any potential glitches in the requirement documents themselves. This blog will provide guidance on how to implement this strategy in any phase of the software testing life cycle (STLC), to help you improve the workflow of any application.
Why use Mind maps in STLC?
There are many reasons to use mind maps in the software testing life cycle (STLC). To begin, let’s compare a written flow of an application with a visual representation, as shown in the picture below. This will help to illustrate the benefits of using mind maps.
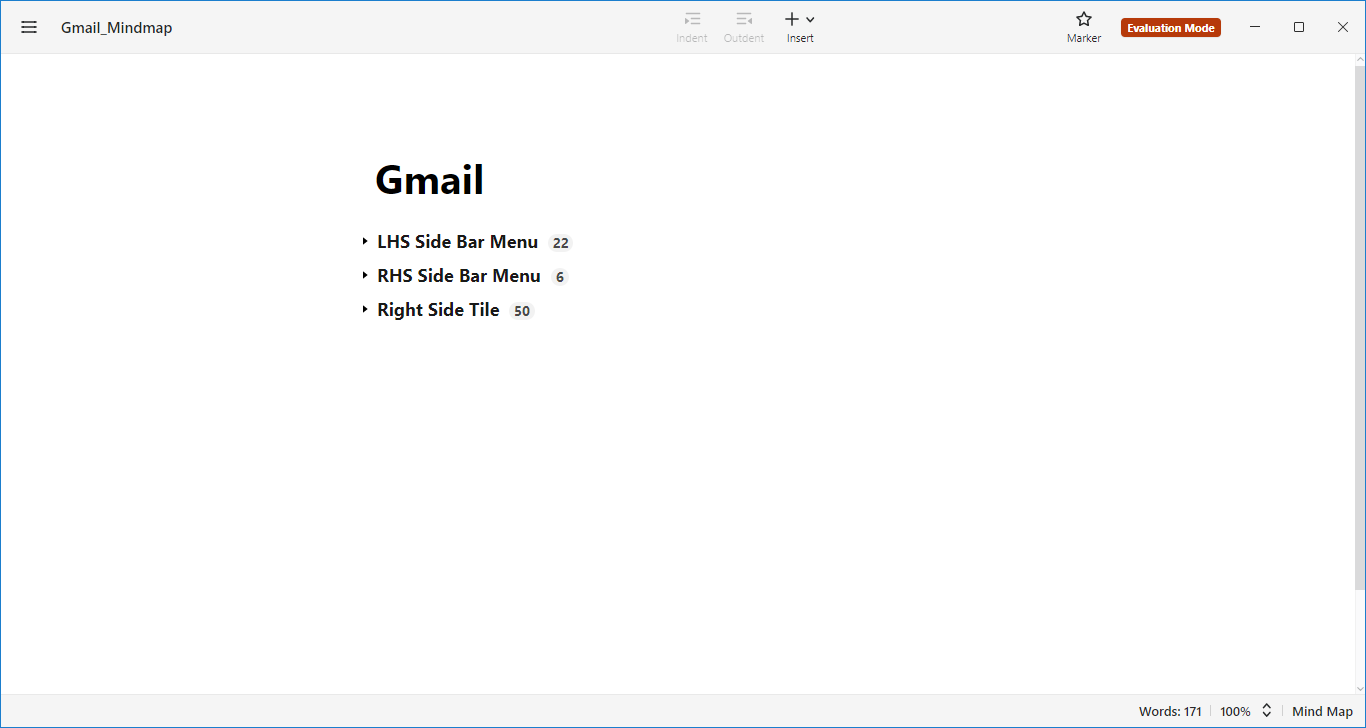
To understand how mind maps can be useful, let’s consider an example of exploratory testing on the Gmail app. If the application and domain are not familiar to you, it can be challenging to understand the workflow of the app. In this case, using a mind map can be extremely helpful.
During exploratory testing, you can acquire a lot of information that needs to be represented in an organized and clear manner. There are two ways to do this, as shown below. Using mind maps is an effective and efficient way to capture all the information in a clear and concise manner. This can help to improve the testing process, streamline communication, and ensure that all key areas are covered.
Option 1 – List View
Left Nav
Compose Mail
Pop-Up Window
To (Recipient Text filed)
Enter single email
To-Select Contact(Pop-Up window)
Enter multiple emails
Add Cc Recipient
Enter Single email
valid
Does have @
Does have domain
Invalid
Does not have @
Does not have domain
To-Select Contact(Pop-Up window)
Enter multiple emails
Add Bcc Recipient
Enter single email
To-Select Contact(Pop-Up window)
Enter multiple emails
Inbox
Starred
Sent
Drafts
Dropdown: More/ Less
Snoozed
Importatnt
Chats
Scheduled
Important
All mail
Spam
Trash
Label
Notes/ Important
when user Hover over tab ellipsis icon appeared (Three dots)
Label Color
Add Custom color
Remove color
In Label List
Tick: Show/ Hide
In Message List
Tick: Show/ Hide
Edit
Remove label
Delete / Cancel
Add sublabel
Create new label '+'
New Label
Check Box: Nest label under previous label
Text box: Enter a new label name
Button: Create
Button: Cancel
Icon: Close 'x'
Create new Label
Manage labels
Opens the label setting page
Categories
Social + Email count
Updates + Email count
Forum + Email count
Promotions + Email count
Right Nav
(Side Panel)
Calender
Keep
Tasks
Contacts
Get Add-ons
Hide Side panel (Arrow icon)/ Show side panel
Top Nav
(Search Filter)
Second Top menu bar
Select Checkmark box
Select mail checkmark in front of any mail(Dropdown appear at main select tab)
All
none
read
unread
Starred
Unstarred
Archive
Report Spam
Delete
Mark as read
Snooze
Add to task
Move to
Label
More
Mark as read
Mark as important
Add star
Filter Messages Like these
Mute
Forward as attachment
Page Numbers
Newest
Oldest
Newer (Arrow icon)
Older (Arrow icon)
Input Tool On/Off
Select input tool dropdown
English
Input tool setting
Deselect Checkmark box
Refresh
More
Mark all as read (When any mail checkbox is not selected)
filter tabs
From
To
Subject
Has the words
Doesn't have
Size
Dropdown: Greater than/ Less than
Date within
5 Days/2 months/ 1 year
Pop-up: Calendar
Month/Year/day
Search
Checkbox: Has attachment
Checkbox: Don't include chats
Top Right Corner Nav
Support
Help
Training
Updates
Send feedback to google
Setting
General
labels
Inbox
Accounts and Import
Filters and Blocked Addresses
Add-Ons
Chat and Meet
Advanced
Google apps
all apps provided by google opens in new tab
Google account
Manage Google accounts
Add account
Sign Out from all accounts
Main Frame
List of Emails
Open any mail
Paper-pin icon: Attachment
Sender: Show details
from: jej.rashant@yrdsb.com
to: Jenny ar@gmail.com
Print All
date: Oct 5, 2020, 1:31 AM
subject: Re: Welcome to the YRDSB Elementary Virtual School Anushri!
In new Window
Reply
Forward
Star
Ellipsis icon: More
reply
reply to all
forward
Print
Delete
Block
Report spam
Report phishing
Show original
Translate message
Download message
Mark as read/ Mark as unread
Scroll Bar (up-down)
checkbox: Select
Starred/ Not starred
Bullet Checkmark: Important
Hover over each mail
Archive/ Delete/ Mark as read/ Snooze
Memory Used by Gmail
Storage indicator bar
Term
GOOGLE TERMS OF SERVICE
privacy
GOOGLE PRIVACY POLICY
Program Policies
New tab: Gmail Program Policies
Last account activities time duration
Details
Pop-up: Activity Info
Search Bar
Show search option
Check/Uncheck: Has attachment
Check/Uncheck: Last 7 days
Check/Uncheck: From me
Icon: Search
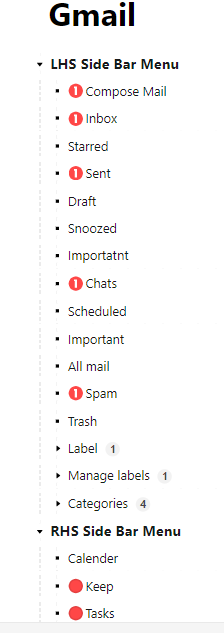
Option 2 – Mind Map view:
So with the help of all this information, What if you need to present a demo of an application to your team in 10 minutes? From the above options, which one would you prefer to use for presenting the information?
The pictured presentation (screenshot) is surely more understandable right!!
This is where a Mind Map can really help:
A mind map can be an incredibly useful tool in software development. It can help us to better understand client requirements and application flow, especially in cases where the client is unsure of the requirements and the application is difficult to express in a team.
In software development, it is crucial to have a clear understanding of the client’s requirements. Mind maps can help us to capture the sequence and interrelated functionality in a clear and organized manner. Additionally, visual representation through mind maps can make it easier for people to understand complex information.
To create mind maps, we are currently using the Xmind application. A mind map is a diagram that visually arranges information in a hierarchy of application or product progression, displaying the relationships between the product components. It typically revolves around a single concept that is drawn as an image in the center of a blank page. The main ideas are linked directly to the central concept, with additional ideas branching out from the sub-menus of those main ideas. Mind maps can include images, words, and parts of words to effectively illustrate and organize information.
Advantages of Mind Mapping in STLC:
Mind mapping can bring numerous benefits to the software testing life cycle (STLC). Here are some of the key advantages:
At the verification level, a mind map can help to present a demo of the requirements to the client or team, providing a detailed understanding of the product or service. Xmind is a great tool to use for this purpose as it allows us to express the flow of the application in a clear and organized way.
By using a mind map, we can create a more effective test plan that prioritizes the most important functions. This can help to ensure that all critical areas are covered during testing.
Mind maps can help us to check test coverage more easily by using color-coded tags such as red, green, and grey. This allows us to quickly identify which areas have been tested and which still require attention.
Traceability metrics can be more easily understood using a mind map, making it simpler to track requirements and test cases throughout the STLC.
Tracking test progress is made easier with a mind map as it provides a clear overview of what has been completed and what still needs to be done.
Finally, mind maps allow us to add pointers for completed or developed functionalities, making it easier to track progress and stay on top of all aspects of the testing process.
Using Mind Maps in Requirement Analysis:
In order to better understand the flow of an application and its requirements, we can create a rough mind map using prototype models and client requirements for each functionality.
For instance, let’s consider the example of creating a new email in Gmail. If the product owner writes a user story requirement in Jira as follows:
“As a user, I should be able to add additional email recipients while drafting an email in a compose pop-up.”
Acceptance Criteria:
Must have “To” by default.
Can add “CC” as an additional recipient.
Can add “Bcc” as an additional recipient.
To better understand this requirement and the flow of the application, we can create a mind map to explore. The above example makes it clear that the “To” field is mandatory, while “CC” and “BCC” are optional fields that can be added. However, it does not elaborate on whether we can type a single email id, multiple email ids, or even get the contacts from our contact list. Hence, creating a Mind Map provides a space to brainstorm these possibilities.
We can use this mind map to ask questions to the product owner and validate whether the possibilities uncovered during exploration are valid. If yes, we can add them to the user story. If not, we can simply remove them from the mind map. It’s important to remember that we will use the same mind map as a basis for our testing plan.
Using Mind Map in Test Planning:
Test planning is the process of defining the scope, objectives, and approaches for testing a software application. It involves creating a detailed plan that outlines the test strategy, test objectives, test environment, test cases, and other important aspects of the testing process. The purpose of test planning is to ensure that testing is conducted in a systematic and efficient manner to identify and eliminate defects in the software application. Test planning is a crucial part of the software testing process and helps to ensure that the software application meets the required quality standards and fulfills the end user’s expectations. Imagine rather than sharing a boring word document, you present your test plan in the Mind Map way. Wouldn’t it make more sense?
Using mind maps in Test Case Design and Execution:
Using mind maps in test case design and execution can make the process more efficient and effective. By referring to a mind map, we can easily write down the test steps for any test scenario, which can improve the overall test coverage. In addition, visualizing negative test scenarios using mind maps can help identify potential defects and improve the quality of the product.
During the execution phase, we can compare the actual product flow with the created mind map. If there are any discrepancies, we can trace the defects and take appropriate action to fix them.
For example, let’s consider the email recipient field. We need to verify that the ‘To’ field is present by default and can be used to add up to 30 email recipients at once. To develop and execute the test cases, we can use testing techniques like boundary value analysis and equivalence class partitioning. By using the mind map as a reference, we can easily set the lower and upper boundaries (e.g., 1 and 30) and ensure that the test cases cover all possible scenarios.
Using Mind maps in Test Reporting:
Mind maps can also be used to represent test reporting by adding symbols to indicate passed, failed, and blocked functionality.
For instance, let’s use the email recipient field scenario again. We can track the total number of test cases created during the test case development phase and mark which ones have passed, failed, or were blocked during execution. This can be achieved by inserting stickers, markers, or icons on the mind map to help understand the test report and the proportion of executed tests.
In addition, we can provide reasons for blocked and failed test cases by using the “insert note” or “label” feature in Xmind or similar applications. This helps us identify the root cause of the issue and take corrective measures. We can also show the progress of testing by adding the percentage of the work completed, giving us a clear picture of the current state of testing.
XMind Application:
When starting a project, it is essential to gain a comprehensive understanding of the application. One way to achieve this is by creating a mind map using the XMind application, which is a user-friendly and open-source tool.
XMind offers a variety of features to help users create detailed and visually appealing mind maps. These include different styles, themes, and templates to choose from, as well as options for adding images, icons, and notes. The application also allows for easy collaboration among team members by enabling the sharing of mind maps and the tracking of changes.
One of the most significant advantages of using XMind is its flexibility in adapting to different project needs. Whether it’s for requirement analysis, test planning, test case design and execution, or test reporting, XMind can accommodate various mind-mapping techniques and support the entire software development life cycle.
Overall, XMind is a versatile and powerful tool that can enhance project management and streamline workflow processes.
Features of Xmind:
Mind Maps are structured with a primary topic located in the center, and sub-topics presented in branches.
The function name refers to the primary or branch name, providing a clear understanding of the relationship between topics.
Mind Map diagrams represent relationships as parent (main), siblings (branch), and child branches, making it easy to understand complex concepts.
Mind Maps can be used across all fields and activities, from project management and software development to education and personal planning.
With Xmind, we can add links, marked information, notes, pictures, attachments, audio equations, and illustrations to enhance the Mind Map’s visual representation.
Xmind allows us to show the priority and progress of work using markers, which is especially helpful in project management.
We can represent parent-child relationships or internal connections of features, making it easier to visualize complex information.
With Xmind, we can select the skeleton format, map previews, styles, or colors at any point in a Mind Map creation, giving us the flexibility to customize and personalize our Mind Maps to our needs.
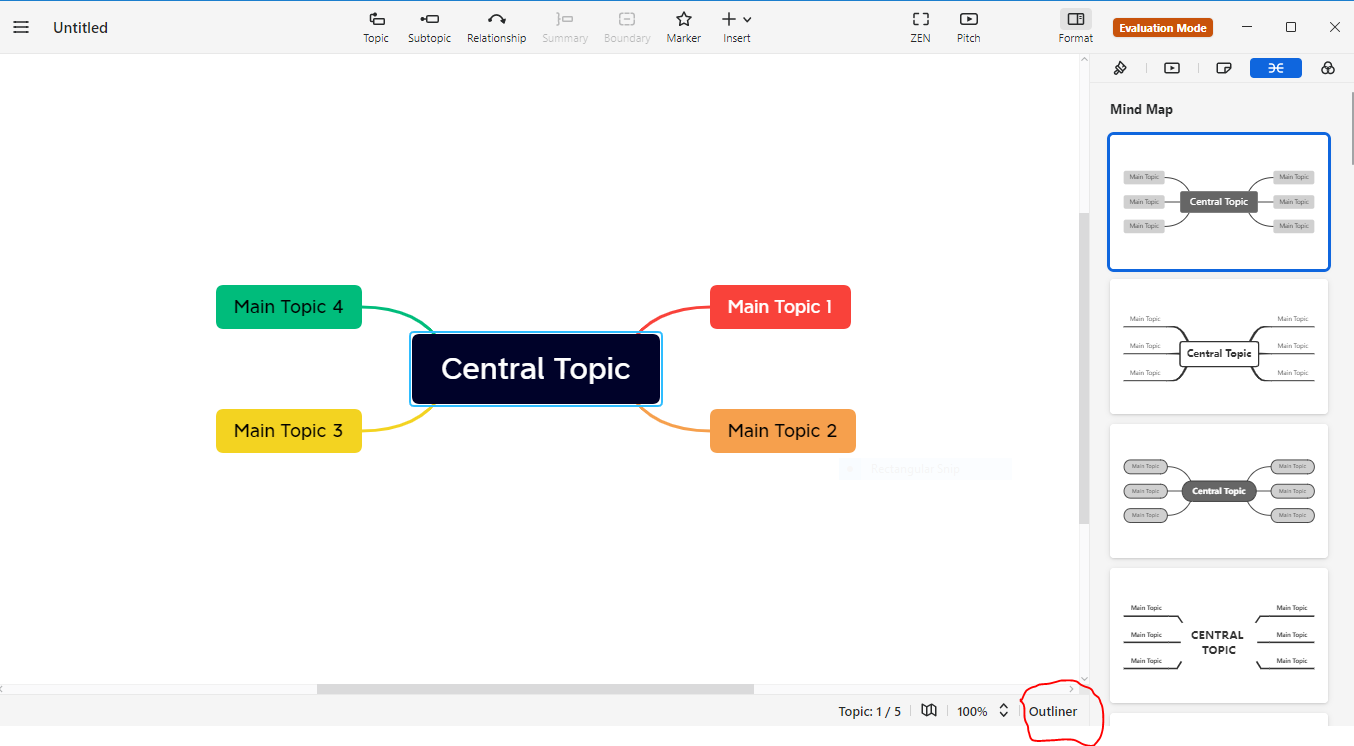
Below are the steps to build a mindmap in the Xmind application.
2. Now, Click on a new slide (+ icon) to create a new mind map, as can be seen below.
3. Click on the outliner link at the bottom of the Xmind app. as shown below in fig.
Here we also can add main features directly in the mind map as a topic and subfeatures as subtopics, or by clicking on the outliner button at the bottom of the page. The view changes as I have shown in the step 5 image.
4. Add main or subtopic by using Indent/ Outdent.
5. Again click on the Mind map button at the bottom of the right corner.
6. Click on the Mind map button at the bottom of the right corner.
At last, you will be able to see the beautifully designed Mind map below.
Note:
Xmind application can be used in two directions either as a web or as a desktop application.
2. There are so many apps available to create mind maps, I have mentioned some below.
i) Mind Maister
ii) Free Mind
iii) Mind Manager
iv) Xmind (Which I feel is more user-friendly)
Conclusion:
Not only in specific testing domains but also in other domains, mind maps are an excellent tool for representing information more effectively. Additionally, mind maps can effectively convey almost all possible details in a single picture.
Pratibha is an SDET skilled in manual and automation testing. The technologies she has expertise in include Selenium, Playwright, SpecFlow, Cucumber, Postman, Maven, TestNG, Java, C#, HTML, and CSS. Having a strong knowledge of API Testing. She has also worked on Azure DevOps and JIRA for project management and defect reporting.
To deliver a good quality of work creating a robust software testing framework is a very important task. Every tester has his/her own approach or method to create a testing framework but the most common and important thing is creating a framework in such a manner that the other testers with minimal knowledge of automation testing can easily utilize the framework. While creating a framework there are some key points that we should consider you will find these points mentioned below.
A good tester is one who has the ability to create a good testing framework. In this blog, I have explained how to create an automation testing framework. Even a beginner with minimal knowledge of automation testing can use this approach to create his own testing framework. There are many more things that you can implement in this explained framework so feel free to comment on it.
When I started my journey as an SDET creating a framework was my first task assigned in my training so I can understand how important it is to create your own framework. Together in this blog, we will see the guidelines I have described which will help us to create a testing framework.
Before we jump into the main topic of our discussion let’s just quickly see the steps we will be following while creating our own framework.
Key Considerations When Creating an Automation Testing Framework:
Understanding the Requirements
Selecting a Testing Framework
Designing Test Cases
Implementing Test Cases
Executing Tests
Maintaining and Improving the Framework
Among the various frameworks present one of the most popular frameworks used for automation testing i.e. the combination of python’s behave library and selenium. In this blog, we are going to explore how to build and use this framework for our automation testing.
As everyone is familiar with Selenium which is an open source and one of the widely used tools for web automation testing along with Playwright and Cypress. Behave is a python library that is used for the BDD (Behavior Driven Development). Let’s just quickly explore what are the different frameworks present out there for automation testing.
A software automation testing framework is designed to make the process of testing software more efficient and easy to use. Every framework has its own advantages and disadvantages as per the given requirement it is most important for us to choose the right framework for automation. Below you will find some of the most commonly used and popular automation frameworks.
Types of Test Automation Frameworks:
Linear Scription Framework.
Modular Testing Framework.
Data-Driven Framework.
Keyword Driven Framework.
Hybrid Framework
Behavior Driven Development Framework.
Test Driven Development Framework.
In this blog, we will be building a BDD framework using Python’s behave library and selenium. In BDD we use the natural language to describe our test scenario divided into steps using the Gherkin language. These test scenarios are present in a feature file and because of the use of natural language, the behavior of the application is easily understandable by all. So, we can say that while creating a BDD framework one of the key components we should consider to use of the feature files and the step files.
As described earlier a feature file is written in natural language with the help of Gherkin language by following a set format. While a step file is an implementation of the steps present in the feature file. Here, a step file is a python file and we can see that it is full of a set of functions where those functions correspond to the steps described in the feature file. Now that we have seen what is feature file and step file let’s see what is the use of python’s behave library here, so basically once the steps and feature file are ready the behave will start automatically matching the steps present in the feature file with its corresponding implementation in the step file and will also check for any assertion errors present.
5. We can also install all the required packages using the requirement.txt file using the below command.
pip install -r requirement.txt
Framework Structure Overview:
Here is the overview of our python selenium behave BDD framework.
As a beginning, we are going to start with creating a simple framework using one scenario outline. In the next blog, we are going to see how to create an API testing framework using python. To understand both of them please read the blog carefully as I am explaining all the points here in natural language, without wasting any time let’s dive into the main topic of our discussion i.e. how to create python selenium behave BDD automation testing framework.
For this, we will follow some guidelines which I have described as steps.
Step 1:
Create a project in Pycharm (here I am using Pycharm professional) and as mentioned in the prerequisites install the packages.
It is not compulsory to use pycharm professional we can use pycharm community as well.
Step 2:
In this step, we will be creating a Features folder in which we will be creating our feature files for different scenarios. A feature file is something that holds your test cases in the form of a scenario and scenario outline. In this framework, we are using a scenario outline. Both scenario and scenario outline contain steps that are easy to understand for non-technical persons. We can also assign tags for the feature files and for the scenarios present in that file. Note that the feature file should end with a .feature extension.
Feature: Create test cases using Selenium with Python to automate below BMI calculator tests
# We are using Scenario Outline in this feature as we can add multiple input data using examples.
Scenario Outline: Calculating BMI value by passing multiple inputs
Given I enter the "<Age>"
When I Click on "<Gender>"
And I Enter a "<Height>"
And I Enter the "<Weight>"
And I Click on Calculate btn
And I Verify Result with "<Expected Result>"
Examples:
| Age | Gender | Height | Weight | Expected Result |
| 20 | Male | 180 | 60 | BMI = 18.5 kg/m2|
| 35 | Female | 160 | 55 | BMI = 21.5 kg/m2|
| 50 | Male | 175 | 65 | BMI = 21.2 kg/m2|
| 45 | Female | 150 | 52 | BMI = 23.1 kg/m2|
Step 3:
Now, we have our feature file let’s create a step file to implement the steps described in the feature file. In order to recognize the step file we are adding step work after the name so that behavior will come to know the step file for that particular feature file. Both feature files and step files are essential parts of the BDD framework. We have to be careful while describing the steps in the feature file because we have to use the same steps in the step file so that behavior will understand and map the step implementation.
from behave import *
# The step file contains the implementation of the steps that we have described in the feature file.
@given('I enter the "{Age}"')
def step_impl(context, Age):
context.bmipage.age_input(Age)
@when('I Click on "{Gender}"')
def step_impl(context, Gender):
context.bmipage.gender_radio(Gender)
@step('I Enter a "{height}"')
def step_impl(context, height):
context.bmipage.height_input(height)
@step('I Enter the "{weight}"')
def step_impl(context, weight):
context.bmipage.weight_input(weight)
@step("I Click on Calculate btn")
def step_impl(context):
context.bmipage.calculatebtn_click()
@step('I Verify Result with "{expresult}"')
def step_impl(context, expresult):
context.bmipage.result_validation(expresult)
Step 4:
In step 4 we will be creating a page file that contains all the locators and the action methods to perform the particular action on the web element. We are going to add all the locators at the class level only and will be using them in the respective methods. The reason behind doing so is it is a good practice to declare your locators at the class level as when the locators get changed it is effortless to replace them and we don’t have to go through the whole code again.
from selenium.webdriver.common.by import By
import time
from Features.Pages.BasePage import BasePage
# The page contains all the locators and the actions to perform on that web element.
# In this page file we have declared all the locators at the class level and we are using them in the respective methods.
class BmiPage (BasePage):
def __init__(self, context):
BasePage.__init__(self, context.driver)
self.context = context
self.age_xpath = "//input[@id='cage']"
self.height_xpath = "//input[@id='cheightmeter']"
self.weight_xpath = "//input[@id='ckg']"
self.calculatebtn_xpath = "//input[@value='Calculate']"
self.actual_result_xpath = "//body[1]/div[3]/div[1]/div[4]/div[1]/b[1]"
def age_input(self, Age):
AgeInput = self.driver.find_element(By.XPATH, self.age_xpath)
AgeInput.clear()
AgeInput.send_keys(Age)
time.sleep(2)
def gender_radio(self, Gender):
SelectGender = self.driver.find_element(By.XPATH, "//label[normalize-space()='" + Gender+"']")
SelectGender.click()
time.sleep(2)
def height_input(self, height):
HeightInput = self.driver.find_element(By.XPATH, self.height_xpath)
HeightInput.clear()
HeightInput.send_keys(height)
time.sleep(3)
def weight_input(self, weight):
WeightInput = self.driver.find_element(By.XPATH, self.weight_xpath)
WeightInput.clear()
WeightInput.send_keys(weight)
time.sleep(3)
def calculatebtn_click(self):
Calculatebtn = self.driver.find_element(By.XPATH, "//input[@value='Calculate']")
Calculatebtn.click()
time.sleep(3)
def result_validation(self, expresult):
try:
Result = self.driver.find_element(By.XPATH, "//body[1]/div[3]/div[1]/div[4]/div[1]/b[1]")
Actualresult = Result.text
Expectedresult = expresult
assert Actualresult == Expectedresult, "Expected Result Matched"
time.sleep(5)
except:
self.driver.close()
assert False, "Expected Result mismatched"
The next one is the base page file. We are creating a base page file to make an object of the driver so that we can easily use that for our page and environment file.
from selenium.webdriver.support.wait import WebDriverWait
# In the base page we are creating an object of driver.
# We are using this driver in the other pages and environment page.
class BasePage(object):
def __init__(self, driver):
self.driver = driver
self.wait = WebDriverWait(self.driver, 30)
self.implicit_wait = 25
Step 5:
This step is very important because we will be creating an environment file (i.e. Hooks file). This file contains hooks for before and after scenarios to start and close the browser. Also if you want you can add after-step hooks for capturing screenshots for reporting. We have added a method to capture screenshots after every step and will attach them to the allure report.
import json
import time
from allure_commons._allure import attach
from allure_commons.types import AttachmentType
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from Pages.BasePage import BasePage
from Pages.BmiPage import BmiPage
data = json.load(open("Resources/config.json"))
# This environment page is used as hooks page. Here we can notice that we have used before, after hooks along side with some step hooks.
def before_scenario(context, scenario):
context.driver = webdriver.Chrome(ChromeDriverManager().install())
time.sleep(5)
basepage = BasePage(context.driver)
context.bmipage = BmiPage(basepage)
context.stepid = 1
context.driver.get(data['BMIWEBURL'])
context.driver.maximize_window()
context.driver.implicitly_wait(3)
def after_step(context, step):
attach(context.driver.get_screenshot_as_png(), name=context.stepid, attachment_type=AttachmentType.PNG)
context.stepid = context.stepid + 1
def after_scenario(context, scenario):
context.driver.close()
Step 6:
It is a good practice to store all our common data and files in a resource folder. So, whenever we need to make changes it will be easy to implement them for the whole framework. For now, we are adding a config.json file in the resource folder. This file contains the web URL used before the scenario to launch the web page for the specified tag in the feature file. The file is written in JSON format.
Congratulations, finally we have created our own Python Selenium Behave BDD framework. As I mentioned earlier we will be using Allure for reporting the test result. For this use the below command in the terminal and it will generate the result folder for you.
Creating a testing framework is very important as well as feels like a tedious task but with the right guidelines, everyone can create a testing framework. I hope in this blog I have provided all the answers related to the python selenium behavior automation testing framework. Here, we choose a BDD framework over other existing frameworks because of its better understanding, easy to adapt, and easy to understand for end users. If you still have any issues related to what we have seen earlier feel free to comment them down we will solve them together. There are many more things we can add to this existing framework but to get started I feel this framework is enough and will cover most of the requirements.
In this article, I will introduce the concept of codeless automation as an innovative and efficient solution for software testing with minimal coding. Performs to increase the importance of time-to-market in product success, codeless automation helps to reduce testing time in release cycles, making it a growing trend in software testing.
One of the most notable codeless automation frameworks is Ginger, an open-source tool created and published by Amdocs under an Apache 2.0 license.
Advantages of codeless automation over traditional code-based automation:
No programming skills are required
Test automation can start from day 1
Keep pace with the development cycle
Faster and more efficient test development
Ginger is a free and open-source automation framework with the following features:
AI-driven automation
Supports various platforms such as web, mobile, windows, APIs, etc.
Simple drag-and-drop approach for codeless automation
Dynamic Error handling with self-healing capabilities
Ability to reuse existing automation scripts
Reduced average repair time
Software reusability across the software lifecycle
Automates visual validations
Built-in integrations with popular open-source tools such as QC, Jira, CI/CD, Jenkins, Bambootools, and others.
Similarly, we will expand the Ginger to investigate and create a web application automation script:
Where can you find Ginger?
You need to Visit “ginger.amdocs.com” and download the latest version of the tool. Below you can see the dashboard.
How do you set up Ginger?
Once the Ginger is downloaded, now double-click on the application file, and a license agreement window will be displayed – select ‘I accept the agreement’, browse the destination location where you want it installed, and click on ‘Next’.
Now, select the default user type and terminology, and then click ‘Install’.
After successfully installing the application. Now, click on the created shortcut to access the Ginger homepage.
Your first Project in Ginger
Here, we will perform Web application automation using Ginger, let’s create a solution for the same. A solution in Ginger is a logical structure with complete automation-related files and only one solution can be loaded at a time. However, multiple target applications can be added to the same solution.
Click on ‘Create a new solution‘
‘Add Solution’ window
Enter the solution name
Browse the location to be stored
Select the ‘main application platform (‘web’)
Enter the ‘solution password encryption key’
Click on the ‘Create’ button
The following diagram depicts the ‘Business Flow,’ which is an end-to-end (start-to-finish) logical flow of the project/business.
So, now the folder structure is automatically created. Once the project solution is created.
Here, multiple target applications can be added to the same solution.
Go to the ‘Configurations’ tab
Click on ‘add (+)’ button
Select the desired application from the window displayed
Accordingly, the target applications have been merged into the solution:
Go to the ‘Business Flows’ tab
Click on the ‘Edit’ tab
Select the desired application in the solution
Configure the agent
Agents are the platform where the scripts will run. First, you select the driver type where you want to launch the application and click the ‘Agents’ tab.
Now, navigate to the ‘Resources’ tab and create an environment for the desired application. An environment stores application-related data such as login credentials, server connection information, and automation flow. One should use environment variables as much as possible to store any configurations that may change per environment.
Given that you have created a new environment, it will ask whether you want to share it with all or a subgroup of the target applications created under business flow.
Given that you have created a new environment, it will ask whether you want to share it with all or a subgroup of the target applications created under business flow. Therefore, you can also create a new environment by cloning one that already exists.
You can also create a new environment by cloning one that already exists.
Now, click on the environment created
A list of target applications assigned to this environment is displayed
Select the desired application and it will open displaying three environment-specific tabs: Parameters, Databases, and Login Users.
Add a new Activity
Basically, you need to navigate to Business Flows and add a new activity. These activities are a collection of actions required to complete a function or intended task.
For example:
The user successfully logged in using valid credentials. Here logging in with valid credentials is a functional activity that can be completed using a set of actions.
Under this activity, multiple actions can be created. You can click on the ‘Automate’ tab in the top right corner of the page and add automation actions from the ‘Action Library’ in the toggle panel. Now on the top bar, the target application configured agent, and environment that you have chosen for the current business flow is displayed.
Essentially, the actions library is divided into four categories: plugin actions, legacy actions, platform actions, and general actions.
In the below image, a ‘Bowser Action’ is added, and double-click it to add a value, i.e. to add various operation settings.
First, go to Expression settings, navigate to the desired folder structure, and enter the URL value, which can be parameterized in the environment.
Now let’s add actions to the activity
We’ve launched the website in the driver; now we’ll locate the elements and log in with the appropriate credentials.
After that Select ‘UI Element Action’ from the Action Library in the toggle panel and provide details about the element to be located.
So, the element ‘Username’ is located using XPath to perform send keys operation.
The following shows the configuration for locating a button and clicking on it for successful login.
Because the configuration shown in the following figures is used to verify the element that appears on the page is successful login.
Variables – To validate the text retrieved after login, go to the expression editor and add the activity variable.
A variety of variables can be included, such as –
‘Variable String’ – To verify a string on the page
‘Variable Random Number’ – To verify a number randomly generated every time within a given range
‘Variable List’ – To verify a variable from a list specified
‘Variable Number’ – To generate a random number between the given minimum and maximum range of number
‘Variable Password String’ – To encrypt the entered password
‘Variable Sequence’ – To give minimum and maximum range of numbers with a specified interval
‘Variable Timer’ – To use as a timer
Similarly, other actions, as shown in the figure below, are added to browse other tabs.
From the ‘Execution Report’ tab, screenshot capture and log details can be enabled.
So here, all the actions of the test scenario are completed, Now click the ‘Run Activity’ button located at the top of the page.
Following is the execution, you can check the output values under ‘Actual Value’ and ‘Expected Value,’ as shown below.
The following image shows the execution in progress
The actual below image shows the execution is completed.
Adding run set
The Run Set is a real-time dashboard with a single complete end-to-end project flow comprised of various activities. It displays the entire Business flow, including actions, activities added and executed, and steps passed, pending, failed, or blocked.
First, you need to Set up the ‘Run Sets’ by adding the desired Business Flow and to start the execution, click on the runner tab button.
Also, you can get a complete execution history:
Navigate to ‘Run Sets
Executions History’ tab
Following are the Execution Results shown in the output of the execution.
Execution Report
The following section shows a failed scenario.
To start, we need to create a new Run Set.
Then add a new runner set, go to the ‘Run Sets’ tab, and click the ‘+’ button.
Now, Click on the ‘+’ button to add a Business flow to the runner.
After adding the business flow, you can see the number of activities and actions in the run set.
So, to run the run set, click the ‘run button’ shown in the image below.
Now, the execution is seen in progress
Here, the runner display number of failed actions, and clicking on the ‘Generate Run Set Report option’, will create a detailed execution report.
The following shows the execution report of the failed test scenario.
Formation of the Execution Reports displays a detailed execution that includes. The following information is an action name, and action type, So now execution – start, duration, and end time, number of retry iterations, status (passed/failed), Error details, and screenshots.
Therefore, we have completed Web application automation using Ginger successfully. Happy Testing!!
Conclusion: –
Ginger strikes me as a simple and modern automation tool that can be used to create test cases in natural language, making it a valuable platform for continuous testing, regression testing, and progressive testing.
An SDET with hands-on experience in Functional testing on Web and Mobile applications, System testing, Requirement analysis, Defect reporting, Web, Mobile, and API Test Automation. Practical experience in Python, JavaScript, C#, Selenium, Playwright, SpecFlow, Behave, Pytest, BrowserStack, Appium, Postman, SQL