Looking to simplify your UI test automation without compromising on speed or reliability?
Welcome to CodeceptJS + Puppeteer — a powerful combination that makes browser automation intuitive, maintainable, and lightning-fast. Whether you’re just stepping into test automation or shifting from clunky Selenium scripts, this CodeceptJS Puppeteer Guide will walk you through the essentials to get started with modern JavaScript-based web UI testing.
Why CodeceptJS + Puppeteer?
Beginner-Friendly: Clean, high-level syntax that’s easy to read—even for non-coders.
Stable Tests: Auto-waiting eliminates the need for flaky manual waits.
Built-in Helpers & Smart Locators: Interact with web elements effortlessly.
CI/CD Friendly: Easily integrates into DevOps pipelines.
Rich Debugging Tools: Screenshots, videos, and console logs at your fingertips.
In this blog, you’ll learn:
How to install and configure CodeceptJS with Puppeteer
Writing your first test using Page Object Model (POM) and Behavior-Driven Development (BDD)
Generating Allure Reports for beautiful test results
Tips to run, debug, and manage tests like a pro
Whether you’re testing login pages or building a complete automation framework, this guide has you covered.
Ready to build your first CodeceptJS-Puppeteer test? Let’s dive in!
1. Initial Setup
Prerequisites
Node.js installed on your system. (Follow below link to Download and Install Node.)
https://nodejs.org/
Basic knowledge of JavaScript.
Installing CodeceptJS Run the following command to install CodeceptJS and its configuration tool: npm install codeceptjs @codeceptjs/configure –save-dev
2. Initialize CodeceptJS
Create a New Project
Initialize a new npm project using following commend:
npm init –y
Install Puppeteer Install Puppeteer as the default helper: npm install codeceptjs puppeteer –save-dev
Setup CodeceptJS Run the following command to set up CodeceptJS: npx codeceptjs init
As shown below, follow the steps as they are; they will help you build the framework. You can choose Puppeteer, Playwright, or WebDriver—whichever you prefer. Here, I have used Puppeteer to create the framework
This will guide you through the setup process, including selecting a test directory and a helper (e.g., Puppeteer).
3. Writing Your First Test
Example Test Case
The following example demonstrates a simple test to search “codeceptjs” on Google:
Dependencies
Ensure the following dependencies are included in your package.json:
A simple test case to perform a Google search is shown below:
Feature('google_search');
Scenario('TC-1 Google Search', ({ I }) => {
I.amOnPage('/');
I.seeElement("//textarea[@name='q']");
I.fillField("//textarea[@name='q']", "codeceptjs");
I.click("btnK");
I.wait(5);
});
4. As we have seen how to create a simple test, we will now explore how to create a test in BDD using the POM approach.
Using Page Object Model (POM) and BDD
CodeceptJS supports BDD through Gherkin syntax and POM for test modularity. If you want to create a feature file configuration, use this command. “npx codeceptjs gherkin:init”
The setup will be created; however, some configurations still need to be modified, as explained below. You can refer to the details provided.
After this, the following changes will be displayed in the CodeceptJS configuration file. Ensure that these changes are also reflected in your configuration file.
A Feature file in BDD is a plain-text file written in Gherkin syntax that describes application behavior through scenarios using Given-When-Then steps. Example: Orange HRM Login Test Feature: Orange HRM
Scenario: Verify user is able to login with valid credentials Given User is on login page When User enters username “Admin” and password “admin123” When User clicks on login button Then User verifies “Dashboard” is displayed on page
Step Definitions
A Step Definitions file in BDD maps Gherkin step definitions to executable code, linking test scenarios to automation logic. Define test steps in step_definitions/steps.js:
const { I } = inject();
const { LoginPage } = require('../Pages/LoginPage');
const login = new LoginPage();
Given('User is on login page', async () => {
await login.homepage();
});
When('User enters username {string} and password {string}', async (username, password) => {
await login.enterUsername(username);
await login.enterPassword(password);
});
When('User clicks on login button', async () => {
await login.clickLoginButton();
});
Then('User verifies {string} is displayed on page', async (text) => {
await login.verifyDashboard(text);
});
Page Object Model
A Page File represents a web page or UI component, encapsulating locators and actions to support maintainable test automation. Create a LoginPage class to encapsulate page interactions:
Run tests and generate reports: npx codeceptjs run npx allure generate –clean npx allure open
6. Running Tests
To execute tests, use the following command: npx codeceptjs run
To log the steps of a feature file on the console, use the command below:
npx codeceptjs run –steps
The — verbose flag provides comprehensive information about the test execution process, including step-by-step execution logs, detailed error information, configuration details, debugging assistance, and more.
npx codeceptjs run –verbose
To target specific tests:
npx codeceptjs run <test_file>
npx codeceptjs run –grep @yourTag
Conclusion:From Clicks to Confidence with CodeceptJS & Puppeteer
In this guide, we walked through the essentials of setting up and using CodeceptJS with Puppeteer—from writing simple tests to building a modular framework using Page Object Model (POM) and Behavior-Driven Development (BDD). We also explored how to integrate Allure Reports for insightful test reporting and saw how to run and debug tests effectively.
By leveraging CodeceptJS’s high-level syntax and Puppeteer’s powerful headless automation capabilities, you can build faster, more reliable, and easier-to-maintain test suites that scale well in modern development workflows.
Whether you’re just starting your test automation journey or refining an existing framework, this stack is a fantastic choice for UI automation in JavaScript—especially when aiming for stability, readability, and speed.
Harish is an SDET with expertise in API, web, and mobile testing. He has worked on multiple Web and mobile automation tools including Cypress with JavaScript, Appium, and Selenium with Python and Java. He is very keen to learn new Technologies and Tools for test automation. His latest stint was in TestProject.io. He loves to read books when he has spare time.
Selenium 4 features significant enhancements over Selenium 3, including a revamped Selenium Grid for distributed testing, native support for HTML5, and integration of the W3C WebDriver protocol for improved compatibility. Additionally, it offers enhanced debugging and error-handling capabilities, streamlining the testing process for better efficiency and reliability.
Benefits of Selenium Automation: Exploring Selenium 4 New Features
Streamline Testing Processes: Selenium automation allows organizations to streamline and enhance their testing processes by automating repetitive tasks associated with web application testing.
Interact with Web Elements: Automation scripts, facilitated by Selenium’s WebDriver, interact with web elements, imitating user actions to test functionality.
Accelerate Testing: Selenium automation accelerates testing by eliminating manual intervention and executing tests efficiently.
Ensure Consistency and Reliability: By automating tests, Selenium ensures consistent and reliable results across diverse browser environments, reducing the risk of human error.
Faster Releases: Selenium automation acts as a catalyst for achieving faster releases by expediting the testing phase.
Improve Test Coverage: With automation, organizations can improve test coverage by running tests more frequently and comprehensively.
Maintain Application Integrity: Selenium automation helps in maintaining the integrity of web applications by identifying and addressing issues promptly.
The Architecture of Selenium 3
The Architecture of Selenium 4
Selenium 4 New Features:W3C WebDriver Standardization
Selenium 4 fully supports the W3C WebDriver standard, improving compatibility across different browsers and reducing inconsistencies.
Standardized Communication:The adoption of the W3C WebDriver protocol ensures consistent behavior across different browsers, reducing compatibility issues.
Improved Grid Architecture: Enhanced scalability and easier management with support for distributed mode, Docker, and Kubernetes.
User-Friendly Selenium IDE: Modernized interface and parallel test execution simplify test creation and management.
Enhanced Browser Driver Management: Unified driver interface and automatic updates reduce manual configuration and ensure compatibility.
Advanced Browser Interactions: Integration with DevTools Protocols for Chrome and Firefox enables comprehensive network and performance monitoring.
Simplified Capabilities Configuration: Using Options classes instead of DesiredCapabilities improves the readability and maintainability of test scripts.
Improved Actions API: Enhancements provide more reliable and consistent complex user interactions across different browsers.
Enhanced Performance: Overall performance improvements result in faster and more efficient test execution.
Better Documentation: Comprehensive and improved documentation reduces the learning curve and enhances productivity.
Backward Compatibility: Designed to be backward compatible, allowing seamless upgrades without significant changes to existing test scripts.
Here, I’ll outline the precise changes introduced in Selenium 4 when compared to its earlier versions:
1. W3C WebDriver Protocol:
Selenium 4 further aligns with the W3C WebDriver standard, ensuring better compatibility across different browsers.
Full support for the W3C WebDriver protocol was a significant improvement to enhance consistency and stability across browser implementations.
2. New Grid :
Selenium Grid has been updated in Selenium 4 with a new version known as the “Grid 4”.
The new grid is more scalable and provides better support for Docker and Kubernetes.
Let’s briefly understand Selenium Grid, which consists of two major components:
Node: Used to execute tests on individual computer systems, there can be multiple nodes in a grid.
Hub: The central point from which it controls all the machines present in the network. It contains only one hub, which helps in allocating test execution to different nodes.
In Selenium 4, the Grid is highly flexible. It allows testing cases against multiple browsers, browsers of different versions, and also on different operating systems.
Even now, there is no need for a setup to start the hub and nodes individually. Once the user starts the server, the Grid automatically functions as both nodes and hub.
3. Relative Locators:
Selenium 4 introduced a new set of locators called “Relative Locators” or “Relative By”.
Relative Locators provide a more natural way of interacting with elements concerning their surrounding elements, making it easier to write maintainable tests.
There are five locators added in Selenium 4:
below(): Web element located below the specified element.
toLeftOf(): Target web element present to the left of the specified element.
toRightOf(): Target web element presented to the right of the specified element.
above(): Web element located above the specified element.
near(): Target web element away (approximately 50 pixels) from the specified element.
Note: All the above relative locator methods support the withTagName method.
The below example demonstrates the toLeftOf() and below() locators:
WebElement book = driver.findElement(RelativeLocators.withTagName("li").toLeftOf(By.id("pid1")).below(By.id("pid2")));
String id1 = book.getAttribute("id1");
The below example illustrates the toRightOf() and above() locators:
Selenium IDE received significant updates with Selenium 4 new features, making it more powerful and versatile for recording and playing back test scenarios.
The Selenium IDE has become a browser extension available for Chrome and Firefox.
The features include:
Improved Browser Support:
The new version enhances browser support, allowing any browser vendor to seamlessly integrate with the latest Selenium IDE.
CLI Runner Based on NodeJS:
The Command Line Interface (CLI) Runner is now built on NodeJS instead of the HTML-based runner.
It supports parallel execution, providing a more efficient way to execute tests concurrently.
The CLI Runner generates a comprehensive report, detailing the total number of test cases passed and failed, along with the execution time taken.
These improvements in Selenium IDE aim to enhance compatibility with various browsers and provide a more versatile and efficient test execution environment through the CLI Runner based on NodeJS.
5. New Window Handling API:
Selenium 4 introduced a new Window interface, providing a more consistent and convenient way to handle browser windows and tabs.
if the user wants to access two applications in the same browser, follow the below code
driver.get(“https://www.google.com/”);
driver.switchTo().newWindow(WindowType.WINDOW);
driver.navigate().to(“https://www.bing.com/”);
Set<String> windowHandles = driver.getWindowHandles();
for (String handle : windowHandles) {
driver.switchTo().window(handle);
// Perform actions on each window
}
6. Improved DevTools API:
Selenium 4 provides enhanced support for interacting with the browser DevTools using the DevTools API.
This allows testers to perform advanced browser interactions and access additional information about the browser.
In the new version of Selenium 4, they have made some internal changes in the API. Earlier in Selenium 3, the Chrome driver directly extended the Remote Web Driver class. However, in Selenium 4, the Chrome driver class now extends to the Chromium Driver class.The Chromium Driver class has some predefined methods to access the dev tool, highlighting the new features of Selenium 4.
Note: Chromium Driver extends the Remote Web driver class.
By using the API, we can perform the following operations:
In Selenium 4, a notable enhancement is the provision to capture a screenshot of a specific web element, which was unavailable in earlier versions. This feature lets users focus on capturing images of individual elements on a webpage, providing more targeted and precise visual information during testing or debugging processes. The capability to take screenshots of specific web elements enhances the flexibility and granularity of testing scenarios, making Selenium 4 a valuable upgrade for web automation tasks. Among the various Selenium 4 features, this improvement stands out for its practical application in detailed web testing.
In Selenium 4, the parameters received in Waits and Timeout have changed from expecting (long time, TimeUnit unit) to expect (Duration duration) which you see a deprecation message for all tests.
WebDriverWait is also now expecting a ‘Duration’ instead of a long for timeout in seconds and milliseconds.
The method is now deprecated in selenium public WebDriverWait(@NotNull org.openqa.selenium.WebDriver driver, long timeoutInSeconds)
Before Selenium 4 –
//Old syntax
WebDriverWait wait = new WebDriverWait(driver,10);
wait.until(ExpectedConditions.visibilityOfElementLocated(By.cssSelector(".classlocator")));
After Selenium 4 –
//Selenium 4 syntax
WebDriverWait wait = new WebDriverWait(driver,Duration.ofSeconds(10));
wait.until(ExpectedConditions.visibilityOfElementLocated(By.cssSelector(".classlocator")));
FluentWait –
Before Selenium 4 –
Wait<WebDriver> wait = new FluentWait<WebDriver>(driver)
.withTimeout(30, TimeUnit.SECONDS)
.pollingEvery(5, TimeUnit.SECONDS)
.ignoring(NoSuchElementException.class);
After Selenium 4 –
Wait<WebDriver> fluentWait = new FluentWait<WebDriver>(driver)
.withTimeout(Duration.ofSeconds(30))
.pollingEvery(Duration.ofSeconds(5))
.ignoring(NoSuchElementException.class);
9. Bi-Directional Communication:
Selenium 4 introduced better bi-directional communication between Selenium and browser drivers.
This allows for more efficient communication, resulting in improved performance and stability.
10. Enhanced Documentation:
Selenium 4 comes with improved and updated documentation, making it easier for users to find information and resources related to Selenium.
11. Support for Chrome DevTools Protocol (CDP):
Selenium 4 allows users to interact with Chrome DevTools using the Chrome DevTools Protocol directly.
Conclusion:
Selenium 4 marks a substantial leap forward, addressing limitations present in Selenium 3 and introducing new features to meet the evolving needs of web automation. The Relative Locators, enhanced window handling, improved DevTools API, and Grid 4 support make Selenium 4 a powerful and versatile tool for testers and developers in the realm of web testing and automation.
Click here for more blogs on software testing and test automation.
Harish is an SDET with expertise in API, web, and mobile testing. He has worked on multiple Web and mobile automation tools including Cypress with JavaScript, Appium, and Selenium with Python and Java. He is very keen to learn new Technologies and Tools for test automation. His latest stint was in TestProject.io. He loves to read books when he has spare time.
In this Blog, I’ll walk you through the process of fetching an email link and OTP from Email using Python. Learn how to fetch links & OTP from email efficiently with simple steps. Email and OTP (One-Time Password) verification commonly ensure security and verify user identity in various scenarios.
Some typical scenarios include:
User Registration
Password Reset
Two-factor authentication (2FA)
Transaction Verification
Subscription Confirmation
We’ll leverage the imap_tools library to interact with Gmail’s IMAP server. We’ll securely manage our credentials using the dotenv library. This method is efficient and ensures that your email login details remain confidential.
Store Credentials Securely to Fetch OTP from Email:
A .env file is typically used to store environment variables. This file contains key-value pairs of configuration settings and sensitive information that your application needs to run but which you do not want to hard-code into your scripts for security and flexibility reasons.
Create a .env file in your project directory to store your Gmail credentials.
EMAIL_USER=your-email@gmail.com
EMAIL_PASS=your-password
How to Create and Use an App Password for Gmail
To securely fetch emails using your Gmail account in a Python script, you should use an App Password.
This is especially important if you have two-factor authentication (2FA) enabled on your account.
Here’s a step-by-step guide on how to generate an App Password in Gmail:
Go to your Google Account settings.
Select “Security” from the left-hand menu.
Enable Two-Factor Authentication:
Go to your Google Account Security Page.
Under the “Signing in to Google” section, ensure that 2-Step Verification is turned on. If it’s not enabled, click on “2-Step Verification” and follow the instructions to set it up.
Generate an App Password:
Once 2-step Verification is enabled, return to the Google Account Security Page.
Under the “Signing in to Google” section, you will now see an option for “App passwords.” Click on it.
You might be prompted to re-enter your Google account password.
In the “Select app” dropdown, choose “Mail” or “Other (Custom name)” and provide a name (e.g., “Python IMAP”).
In the “Select device” dropdown, choose the device you’re generating the password for, or select “Other (Custom name)” and enter a name (e.g., “My Computer”).
Click on “Generate.”
Google will provide you with a 16-character password. Note this password down securely, as you’ll need it for your Python script.
Load Environment Variables:
In your Python script, use the dotenv library to load these credentials securely. Here’s how you can do it:
from dotenv import load_dotenv
from imap_tools import MailBox, AND
import os
# Load .env file
load_dotenv()
# Read variables
email_user = os.getenv('EMAIL_USER')
email_pass = os.getenv('EMAIL_PASS')
Loading Environment Variables:
The dotenv library is used to load the email username and password from the .env file. This approach keeps your credentials secure and out of your source code.
Connect to Gmail and Fetch Emails:
We will create a function to connect to Gmail’s IMAP server and fetch the latest unread email. The function will look like this:
def check_latest_email():
# Connect to Gmail's IMAP server
with MailBox('imap.gmail.com').login(email_user, email_pass, 'INBOX') as mailbox:
# Fetch the latest unread email
emails = list(mailbox.fetch(AND(seen=False), limit=1, reverse=True))
if len(emails) == 0:
return None, None, None # No Emails Found
return emails[0]
if __name__ == "__main__":
email = check_latest_email()
if email:
print("Email subject: ", email.subject)
print("Email text: ", email.text)
print("Email from: ", email.from_)
else:
print("No new emails found.")
Connecting to Gmail’s IMAP Server:
Using the imap_tools library, we connect to Gmail’s IMAP server.
The MailBox class handles the connection.
The login method authenticates using your email and password.
Fetching the Latest Unread Email:
The fetch method retrieves emails based on specified criteria.
AND(seen=False) ensures we only get unread emails.
limit=1 fetches the latest one.
reverse=True sorts the emails in descending order.
Handling Email Data:
The function check_latest_email returns the most recent unread email’s subject, text, and sender.
If no new emails are found, it returns None.
By following these steps, you can efficiently fetch the latest unread email from your Gmail inbox using Python.
This method is not only secure but also straightforward, making it easy to integrate into your projects.
Fetching the link from email:
def extract_link(email_text):
# Regex pattern to match URLs
url_pattern = re.compile(r'https?://[^\s]+')
match = url_pattern.search(email_text)
if match:
return match.group()
return None
#Example to fetch link from email content:
link = extract_link(email.text)
if link:
print("Extracted Link: ", link)
else:
print("No link found in the email content.")
Fetching OTP from email:
Create a function to extract the OTP from the email content using a regular expression. This assumes the OTP is a 6-digit number, which is common for many services:
def extract_otp(email_text):
# Regex pattern to match a 6-digit number
otp_pattern = re.compile(r'\b\d{6}\b')
match = otp_pattern.search(email_text)
if match:
return match.group()
return None
#Example to extract otp from email
otp = extract_otp(email.text)
if otp:
print("Extracted OTP: ", otp)
else:
print("No OTP found in the email content.")
Refer to the following GitHub repository for instructions on how to fetch links and OTPs from Gmail.
Fetching links and OTPs from email content programmatically is essential for enhancing security, improving user experience, and increasing operational efficiency. Automation ensures timely and accurate processing, reducing the risk of errors and phishing attacks while providing a seamless user experience. This approach allows businesses to scale their operations, maintain compliance, and focus on strategic activities.
Click here for more blogs on software testing and test automation.
Harish is an SDET with expertise in API, web, and mobile testing. He has worked on multiple Web and mobile automation tools including Cypress with JavaScript, Appium, and Selenium with Python and Java. He is very keen to learn new Technologies and Tools for test automation. His latest stint was in TestProject.io. He loves to read books when he has spare time.
“Cypress Testing – Assertions Techniques Best Practices and Tips” focuses on enhancing the efficiency and effectiveness of test assertions in Cypress, a popular JavaScript end-to-end testing framework.
Cypress testing plays a crucial role in ensuring the reliability and correctness of web application tests. Developers and testers use these to validate expected outcomes, allowing them to assert conditions about the application’s state during test execution. Automation Testing.
We can summarise the key features of Assertions in Cypress Testing as:
Rich Assertions: Comprehensive checks for element properties (existence, visibility, text content, attributes).
Seamless Integration: Assertions smoothly blend into test syntax, improving readability and maintenance.
Automatic Retry: Robust handling of asynchronous tasks, minimizing test flakiness.
Expressive Tests: Empowers developers to create clear, comprehensive, and efficient tests, boosting confidence in the testing process.
<button id="myButton">Visible Button</button>
<button id="hiddenButton">Hidden Button</button>
//To check visibility of element
cy.get(' button#myButton ').should('be.visible')
//To check invisibility of element
cy.get('button#hiddenButton').should('not.be.visible');
Verify that an element is hidden:
Syntax: .should(‘be.hidden)
Example:
<body>
<div id="hiddenElement">This element is hidden</div>
</body>
cy.get('#hiddenElement').should('be.hidden');
Verify that an element has the expected value that the user has entered in the textbox:
Verify that a string includes the expected substring:
Syntax: .should(‘include’, ‘expectedSubstring’)
Example:
<title>Cypress Example</title>
<body>
<div id="myText">This is some text content.</div>
</body>
// Verify that the text content includes the expected substring
const expectedSubstring = 'some text';
cy.get('#myText').should('include.text', expectedSubstring);
Verify that a string matches a regular expression pattern:
Syntax: .should(‘match’, /regexPattern/)
Example:
<title>Cypress Example</title>
<body>
<div id="myText">This is some text content.</div>
</body>
// Verify that the text content matches a regular expression pattern
const regexPattern = /some.*content/;
cy.get('#myText').invoke('text').should('match', regexPattern);
Verify the length of an array or the number of elements matched:
<title>Cypress Example</title>
<body>
<input type="text" id="myInput" />
</body>
// Focus on the input element
cy.get('#myInput').focus();
// Verify that the input element is focused
cy.get('#myInput').should('have.focus');
cy.get('#myInput').should('be.focused ');
cy.get('h1')
.should('exist') // Assertion 1: Check if the h1 element exists
.and('be.visible') // Assertion 2: Check if the h1 element is visible
.and('have.text', 'Example Domain'); // Assertion 3: Check if the h1 element has the expected text
Property Assertion in Cypress Testing
Verify that an element has the expected attribute value:
Verify that a given value is NaN, or “not a number”:
Syntax: .should(‘be.a.NaN’)
Example:
// Some operation that results in NaN, for example, dividing by zero
const result = 1 / 0;
// Verify that the result is NaN
1) cy.wrap(result).should('be.a.NaN');
2) cy.wrap(result).then(value => {
expect(value).to.not.be.NaN;
});
Verify an element or collection of elements is empty:
<body>
<div id="emptyElement"></div>
<div id="nonEmptyElement">Some content</div>
</body>
// Verify that the empty element is empty
cy.get('#emptyElement').should('be.empty');
// Verify that the non-empty element is not empty
cy.get('#nonEmptyElement').should('not.be.empty');
Verify that a numeric value is within a certain range of another value:
Syntax: .should(‘be.closeTo’, expectedValue, delta)) .should(‘be.within’, Start range, End range);
Example:
const actualValue = 15;
const referenceValue = 10;
const range = 5;
// Verify that the actual value is within the specified range of the reference value
cy.wrap(actualValue).should('be.within', referenceValue - range, referenceValue + range);
});
// Verify that the actual value is close to the expected value within the specified delta
cy.wrap(actualValue).should('be.closeTo', 50, 2); // Verify that actual value is close to (50-2) to (50+2) i.e. 48 to 52.
In the context of Cypress Testing, the .is() block typically utilizes conditions that check various states or attributes of an element. Here are some examples of selectors and conditions you might use inside the .is() block:
Check if an element is visible:
if($element.is(':visible')){
// Code to execute when the element is visible
}
Check if a button or input is enabled:
if ($element.is(':enabled')) {
// Code to execute when the element is enabled
}
Check if an input field is readonly:
if ($element.is('[readonly]')) {
// Code to execute when the element is readonly
}
Check if an element contains specific text:
if ($element.is(':contains("Some Text")')) {
// Code to execute when the element contains the specified text
}
Check if an element has a specific attribute value:
if ($element.is('[data-type="value"]')) {
// Code to execute when the element has the specified attribute value
}
Create custom conditions based on your specific requirements:
if ($element.is('.custom-class')) {
// Code to execute when the element has a specific class
}
Conclusion:
Cypress Testing with its rich set of functionalities and integration benefits, empowers developers to create expressive and comprehensive tests. The combination of these features fosters a more efficient and confident testing process, ultimately contributing to the overall reliability of web applications.
Harish is an SDET with expertise in API, web, and mobile testing. He has worked on multiple Web and mobile automation tools including Cypress with JavaScript, Appium, and Selenium with Python and Java. He is very keen to learn new Technologies and Tools for test automation. His latest stint was in TestProject.io. He loves to read books when he has spare time.
In this blog, we have created the WebdriverIO framework, which will help to run test cases on web applications on different browsers. WebdriverIO is a popular open-source test automation framework for Node.js.Creating a test automation framework using Cucumber, JavaScript, and WebdriverIO offers several benefits that can streamline your testing process and improve the efficiency and maintainability of your automated tests. Here’s why you might want to consider using this combination:
1. BDD Approach with Cucumber:
Cucumber enables Behavior-Driven Development (BDD), allowing you to write test scenarios in a human-readable format.
2. JavaScript Language:
JavaScript is a widely used programming language for web development, making it accessible to many developers.
WebdriverIO is a popular JavaScript-based WebDriver framework that simplifies interactions with browsers and elements on web pages. It also provides a variety of built-in commands for browser automation, making test script development more efficient.WebdriverIO supports multiple testing frameworks, including Mocha and Jasmine, which can be integrated with Cucumber for BDD.
4. Cross-Browser Testing:
With WebdriverIO, you can quickly run your tests across different browsers and browser versions. This ensures that your application functions correctly and consistently across various browser environments.
5. Reusability and Maintainability:
The combination of Cucumber and WebdriverIO promotes the creation of reusable step definitions. Moreover, this modularity makes it easier to maintain test scripts and reduces duplication of code.
6. Parallel Execution:
WebdriverIO supports parallel test execution, which can significantly reduce the overall test execution time.
7. Community and Support:
Both Cucumber and WebdriverIO have active communities, which means you can find a wealth of resources, tutorials, and plugins to enhance your automation efforts.
Let’s see how webdriverIO works and Its process:
Pre-requisites:
1. Make sure you have Node.js installed on your system. You can download and install it from the official website: https://nodejs.org/en/
2. Open your terminal or command prompt and create a new directory for your WebdriverIO project or else create a folder wherever you want & open it in VSCode
3. VSCode
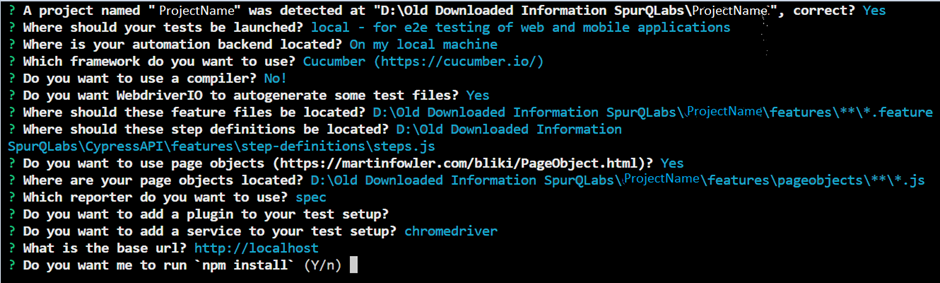
Initialize a new npm project by running the following command: “npm init wdio .” This will create WebdriverIO packages and their installation.
Once you execute that command you will get the following message:
“Need to install the following packages:
create-wdio@8.2.3
Ok to proceed? (y)”
If you proceed by pressing “y”, you will receive a list of instructions on how to generate the framework. You can follow these instructions to create the desired WebdriverIO framework.
Once you have completed the framework generation process, it will create a package.json file that will serve as a record of your project’s dependencies. This file will help you manage and keep track of the dependencies required for your project.
“Install WebdriverIO and its CLI tool by running the following command:
“npm install webdriverio @wdio/cli –save-dev”.
This will install WebdriverIO and its CLI tool as dev dependencies and save them in your package.json file.”
Package-json:
package.json is a file used in Node.js projects that contains metadata and configuration information for the project, as well as a list of dependencies and dependencies required for the project to run. It is located in the root directory of the project and is used by package managers such as npm (Node Package Manager) to install and manage dependencies.
Wdio.conf.js:
This file contains the configuration settings that define how the test automation framework runs and interacts with the web application being tested. It has Capabilities, Specs, Framework, Reporter, Hooks, Services, etc.
So here we have selected the “cucumber” framework which will help create test cases in BDD format. Before we go into framework details, you all should know that all WebdriverIO commands are asynchronous and need to be properly handled using async/await.
The Page Object Model (POM) is a popular design pattern used in software testing to represent web pages as objects and simplify the process of automated testing. The POM structure usually includes a “pageobjects” folder, which contains classes or files that represent individual pages on a website or application. These page object classes or files encapsulate the elements and actions related to a specific page, making writing and maintaining automated tests easier. By using the POM, testers can create a more organized and maintainable framework for their test automation efforts.
1) Features
2) Steps
3) Pages
Features:
This folder contains another two folders, i.e., pageobjects, Step-definitions, and features files. The “feature” folder is typically used in the context of behavior-driven development (BDD) frameworks such as Cucumber, which uses a natural language syntax to describe test scenarios. The “feature” folder houses files that define the scenarios or features to be tested.
To create a feature file in VSCode for implementing behavior-driven development (BDD) scenarios using Cucumber, you can follow these steps:
· Open VSCode and navigate to the folder where you want to create the feature file.
· Right-click on the folder, go to “New File”, and click on it to create a new file.
· Give the file a name with the “.feature” extension, for example, “login.feature”
Feature: Checking calculator functionality
Scenario: Verify addition on calculator
Given User is on the calculator page
When User taps on "4"
And User taps on operator
And User taps on "5"
Then User verifies the answer as "9"
Scenario Outline: Verify user can perform multiple operation
Given User is on the calculator page
When User clicks on num1 "<number1>"
The user clicks on the "<operator>"
And User clicks on num2 "<number2>"
Then User verifies "<answer>"
Examples:
| number1 |number2 | operator | answer |
| 4 | 5 | + | 9 |
| 5 | 3 | - | 2 |
| 4 | 5 | * | 20 |
| 6 | 2 | / | 3 |
In the above feature file, I have shown one simple scenario where I have performed a simple addition operation, and in the next scenario, I have created a scenario outline where different operations are performed, including addition, subtraction, multiplication, and division.
Step-definitions:
The “step-definitions” folder contains files or classes that define the behavior or actions associated with each step in the BDD scenario.
In WebDriverIO, you can generate step definitions for the given scenarios in a feature file using a tool called “cucumber-boilerplate”.
Following are the steps to generate steps in WebDriverIO using cucumber:
Install the “cucumber-boilerplate” package as a development dependency by running the following command in your project directory: “npm install cucumber-boilerplate –save-dev”
Once the installation is complete, you can generate the step definitions by running the following command: “npx cucumber-boilerplate generate”
This will prompt you to enter the path to the feature file for which you want to generate the steps.
Provide the path to the feature file (e.g., “./features/login.feature”) and press Enter.
The tool will generate the step definitions in JavaScript format, which you can then copy and paste into your WebDriverIO project’s step definition files.
const { Given, When, Then } = require('@wdio/cucumber-framework');
const addPage = require('../pageobjects/AddPage');
Given(/^User is on calculator page$/, async () => {
await addPage.visitWeb()
});
When(/^User taps on "(\d+)"$/, async (num) => {
await addPage.tapNumber(num)
})
When(/^User taps on operator$/, async () => {
await addPage.tapOperator()
}
Then(/^User verifies answer as "(\d+)"$/, async (ans) => {
await addPage.getAns(ans)
})
When(/^User clicks on num1 "([^"]*)"$/, async (num1) => {
await addPage.clickNum1(num1)
})
When(/^User clicks on num2 "([^"]*)"$/, async (num2) => {
await addPage.clickNum2(num2)
})
When(/^User clicks on the "([^"]*)"$/, async(opt) =>{
await addPage.clickOperator(opt)
})
Then(/^User verifies "([^"]*)"$/, async(ans) =>{
await addPage.verifyAnswer(ans);
})
In the above code, you can see we have integrated steps for each line of the feature file, so we can run code in BDD format.
Page objects:
These are classes that represent a web page, containing methods and properties that interact with the page’s elements, such as buttons, links, and input fields.
const { config } = require("../../wdio.conf");
const assert = require('assert');
const addPageLoc = require("../../Locators/AddPageLocators")
const scr = require('../pageobjects/ScreenshotPage')
class AddPage{
constructor(){
this.plusOpt = addPageLoc.plusOpt;
this.answer = addPageLoc.answer;
}
// Since we parameterized the value for the locator, we kept it as is.
getNumber(num){
return $('[onclick="r('+num+')"]')
}
async tapNumber(num){
await this.getNumber(num).click();
scr.takeScreenshot('tapping_number');
}
async tapOperator(){
await this.plusOpt.click()
await browser.pause(3000);
scr.takeScreenshot('tapping_operator');
}
async getAns(){
let txt = await this.answer.getText()
console.log("Answer of addition: " +txt);
scr.takeScreenshot('gettingTextOfElement');
}
async visitWeb(){
await browser.url(config.baseUrl)
scr.takeScreenshot('webUrl');
}
async clickNum1(num1){
await this.getNumber(num1).click();
scr.takeScreenshot('clicking_number1');
}
async clickNum2(num2){
await this.getNumber(num2).click();
scr.takeScreenshot('clicking_number2');
}
async clickOperator(opt){
await $('[onclick="r(\''+opt+'\')"]').click();
// await this.operator.replace('XXX', opt).click();
scr.takeScreenshot('clicking_operator');
}
async verifyAnswer(ans){
let result = await this.answer.getText()
console.log("Retrieving text value from element: " +result)
assert.equal(result,parseInt(ans));
scr.takeScreenshot('verifyingResult');
}
}
module.exports = new AddPage();
The browser.pause() method was used to pause it for the specified amount of time. It takes time in milliseconds.
Also, we added methods to the “AddPage” class, such as click() and setValue(), that are necessary to perform operations on web elements. Also, the setValue() method has been used for sending values for web elements.
Locators: This folder includes all the locators required to operate web elements
In the above code, we listed out all the locators in one file and then imported them into pages, removing clumsiness from the code
Now that we have completed implementing the Page Object Model (POM) design pattern, we can consider incorporating additional functionalities to further enhance the framework’s suitability and reliability.
Screenshots:
To add screenshot functionality to your code, you need to incorporate the following code into your implementation:
class ScreenshotPage{
takeScreenshot(filename) {
const timestamp = new Date().getTime();
const filepath = `./screenshots/${filename}_${timestamp}.png`;
browser.saveScreenshot(filepath);
}
}
module.exports = new ScreenshotPage();
Import this code into the page where you need to capture a screenshot by calling takeScreenshot(‘nameOfScreenshot’).
The above image displays the screenshots it took. The sequence of screenshots offers an overview of the test case, illustrating actions taken at each step.
Cross-Browser Testing:
Cross-browser testing is a practice in software testing that involves testing a web application or website across multiple web browsers and browser versions to ensure its consistent functionality and appearance across different browser environments.
Capabilities:
In the wdio.conf.js file, make changes similar to what I have done in the ‘capabilities’ section. I have attached the following code for your reference. You can use it for assistance and make changes accordingly.
In the ‘services’ section of the wdio.conf.js file, make changes similar to what I did in the following code snippets. You can make changes accordingly and run your test cases smoothly.
The above code will assist you in implementing different browsers for testing, and you can also add others like Microsoft Edge, Safari, etc.
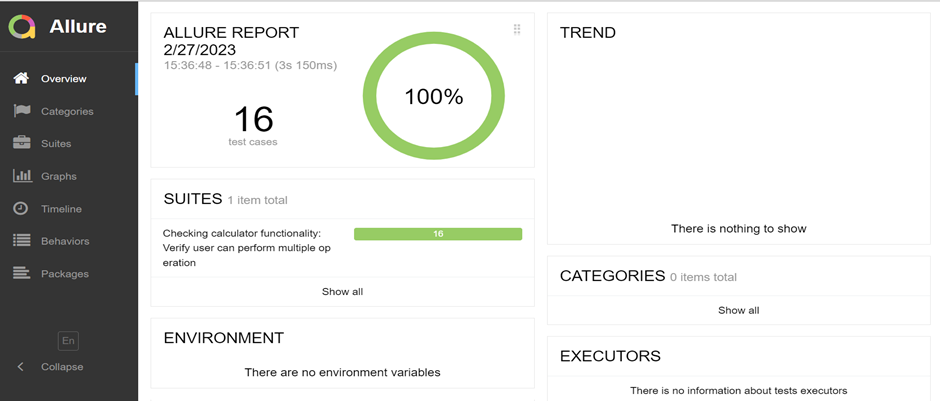
Allure_Report:
Allure Reports are often preferred over Cucumber Reports due to their visually appealing visualizations, comprehensive insights, step-by-step details, time tracking, integration capabilities, and historical trend analysis.
Once you have completed the automation process, testers need to generate reports to track the status of test cases, including pass or fail results and the exact location of failures. You can use the Allure report functionality for this purpose in your WebDriverIO project Follow these steps to include the Allure report:
1. Install the Allure Reporter plugin for WebDriverIO using the following command: “npm install @wdio/allure-reporter –save-dev”
2. Add the Allure Reporter plugin to your wdio.conf.js file as a reporter. Following is an example configuration:
In this example, we’re using the spec reporter for console output and the allure reporter for generating the allure report. The outputDir option specifies the directory where it will generate the report files.
1. Add the Allure command line tool to your project by running the following command: “npm install allure-commandline –save-dev”
2. After running your tests, generate the Allure report by running the following command: “npx allure generate allure-results –clean”
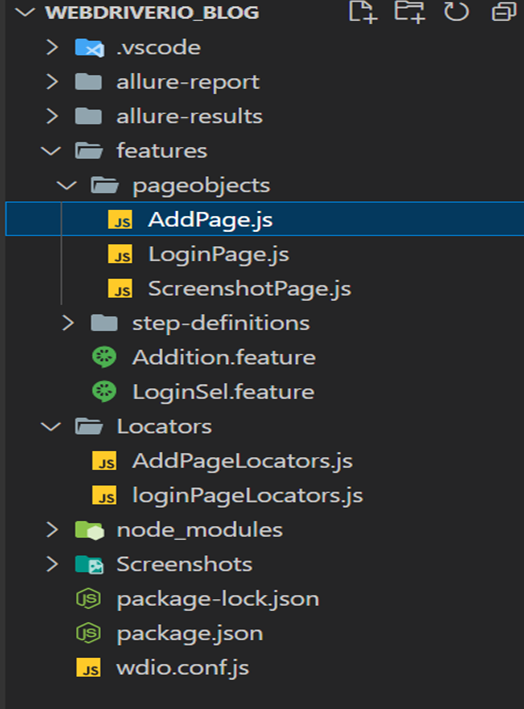
Project Folder Structure:
As we have completed the design of the folder structure for the framework, you can now see below the image of what the framework’s folder structure looks like.
The image above shows the integration of different folders in the WebdriverIO framework. I have provided explanations for each folder and its contents.
To run test cases on a browser, you can use the following commands:
· npx wdio wdio.conf.js
· npx wdio run wdio.conf.js –spec features\Addition.feature // To run a specific feature file
· npx wdio wdio.conf.js –spec ./path/to/your/test.js –browser chrome // To run on a specific browser”
Note: Please make sure to replace the path and file names with the appropriate ones for your specific setup
Conclusion:
WebdriverIO is a comprehensive and feature-rich framework that empowers developers and testers to create reliable and efficient automation tests for web applications. It is a vast ecosystem of plugins, extensive documentation, and also active community support make it a top choice for automation testing in the modern web development landscape. By adopting WebdriverIO, organizations can significantly improve their web application testing efforts and deliver high-quality software to their end-users.
Harish is an SDET with expertise in API, web, and mobile testing. He has worked on multiple Web and mobile automation tools including Cypress with JavaScript, Appium, and Selenium with Python and Java. He is very keen to learn new Technologies and Tools for test automation. His latest stint was in TestProject.io. He loves to read books when he has spare time.