Selenium is an open-source Web UI automation testing suite/tool. It supports automation across different browsers, platforms, and programming languages which includes Java, Python, C#, .net, Ruby, PHP, and Perl, etc. for developing automated tests. Selenium can be easily deployed on Windows, Linux, Solaris, and Macintosh Operating Systems. It also provides support for mobile applications like iOS, windows mobile, and Android for different Operating Systems.
Selenium consists of drivers specific to each language. Additionally, the Selenium Web driver is mostly used with Java and C#.
Test scripts can be coded in selenium in any of the supported programming languages and can be run directly in most modern web browsers which include Internet Explorer, Microsoft Edge, Mozilla Firefox, Google Chrome, Safari, etc.
Furthermore, C# is an object-oriented programming language derived from C++ and Java. It supports the development of console, windows, and web-based applications using Visual Studio IDE on the .Net platform.
With Selenium C#, there is a wide variety of automation frameworks that can be used for automated browser testing. Each framework has its own advantages and disadvantages, they are chosen on the basis of their requirement, compatibility, and the kind of solution they’d prefer. These are the most popular Selenium C# frameworks used for test automation.
NUnit:
It is a unit testing tool ported initially from JUnit for .Net Framework and is an Open Source Project. NUnit was released in the early 2000s, though the initial Nunit was ported from Junit, the recent .Net version 3 is completely rewritten from scratch.
To run the Nunit test we need to add attributes to our methods. An example, attribute [Test], Indicates the Test method. Below are the NuGet Packages required by NUnit
NUnit NUnit3TestAdapter Microsoft.NET.Test.Sdk
XUnit:
XUnit is a unit testing tool for .Net Framework which was released in 2007 as an alternative to Nunit. xUnit has attributes for the execution of tests but is not similar to NUnit. [Fact] and [Theory] attributes are similar to [Test]
MSTest is a unit testing framework developed by Microsoft and ships with Visual Studio. However, Microsoft made version 2 open-source which can easily be downloaded. Additionally, MSTest has an attributes range similar to NUnit and provides a wide range of attributes along with parallel run support at the Class and Method level.
Prerequisite:
To get started with Selenium C# and the Page Object Model framework, first, we need to have the following things installed.
1) IDE: Download and install any IDE of your choice.
After downloading the Visual Studio Installer, select the .NET desktop development option and then click on Install.
Now let the Visual Studio Installer download the packages and perform the installation.
Install the latest version of the .NET Framework on your machine.
2) Create New Project: After the installation is over, begin using Visual Studio.
select the Create a new project option, then select the xUnit Test Project option for C#.
3) Selenium Webdriver for Chrome Browser: You must also install Selenium’s web driver for Chrome browser.
In Visual Studio navigate to Tools -> NuGet Package Manager -> Manage NuGet Packages for Solution.
In the Search Bar, enter the name of the packages you want to install (e.g. Selenium .WebDriver).
Check the Project checkbox, and click on Install.
In the dialogue box asking to accept the licences click on Accept button.
This will start the installation process and install the Selenium WebDriver.
Selenium.WebDriver
This package contains the .NET bindings for concise and object-based
Selenium WebDriver API, which uses native OS-level events to manipulate the browser, Selenium.Chrome.WebDriver (chrome driver exe) This NuGet package installs Chrome Driver (Win32) for Selenium WebDriver in your xUnit Test Project.
Once Visual Studio is finished with the successful installation of the Selenium WebDriver, it will show a message in the output window. Once the Visual Studio is set up with all dependencies, it’s ready for work.
Note:We will be using the demo testing website (https://www.calculator.net/) and trying to achieve the addition and subtraction operations for our automation test.
Writing the First Selenium C# Test:
Download the WebDriverManager from Tools -> NuGet Package Manager -> Manage NuGet Packages for Solution.
WebDriverManager is an open-source Java Library that automates the management of driver executables required by Selenium WebDriverby performing the four steps (find, download, setup, and maintenance) for the drivers required for Selenium tests. Here are some benefits of WebDriverManager in Selenium:
WebDriverManager automates the management of WebDriver binaries, thereby avoiding installing any device binaries manually.
WebDriverManager checks the version of the browser installed on your machine and downloads the proper driver binaries into the local cache (~/.cache/selenium by default) if not already present.
WebDriverManager matches the version of the drivers. If unknown, it uses the latest version of the driver.
WebDriverManager offers cross-browser testing without the hassle of installing and maintaining different browser driver binaries.
In the UnitTest1 file, the final code looks like this:
public class UnitTest1
{
IWebDriver driver;
CalculatorPage calc_page;
public void Initialize_driver()
{
new WebDriverManager.DriverManager().SetUpDriver(new ChromeConfig());
driver = new ChromeDriver();
calc_page = new CalculatorPage();
}
public void Close_driver()
{
driver.Close();
}
[Fact]
public void Add()
{
initialize_driver();
calc_page.Initialize(driver);
string actualresult = calc_page.calculate("14", "+", "5");
Assert.Equal("19", actualresult);
Close_driver();
}
[Fact]
public void Subtract()
{
initialize_driver();
calc_page.Initialize(driver);
string actualresult = calc_page.calculate("24", "-", "5");
Assert.Equal("19", actualresult);
Close_driver()
}
}
Now just build your code by right-clicking the project xUnitTestProject1 or by pressing Ctrl + Shift + B and you will be able to see your test in “Test Explorer”.
After following the above procedure, run the test case. But this code will not execute unless the Chrome driver for the Selenium is not downloaded and unzipped on the system.
When developing a scalable and robust automation framework, it is important to consider the following challenges:
Keeping up with UI changes: The primary goal of automated UI web tests is to validate the functionality of web page elements. However, the UI is subject to constant evolution, leading to changes in web locators. These frequent changes in web locators pose a challenge to code maintenance.
Code maintenance: With the ever-changing UI, it is crucial to maintain the automation codebase effectively. Failing to update Selenium test automation scripts to reflect changes in web locators can result in test failures. Proper maintenance is essential to ensure the longevity and reliability of the test scripts.
Test failure due to lack of maintenance: Inadequate maintenance of automation scripts can lead to scenarios where tests fail. One common cause is a change in web locators. If the Selenium test automation scripts are not updated accordingly, it can cause a significant number of tests to fail, impacting the overall test suite’s reliability.
So to address this, restructure the Selenium test automation scripts for increased modularity and reduced code duplication.
Utilizing the Page Object Model (POM) design pattern achieves code restructuring and minimizes the effort required for test code maintenance.
Now, let’s delve into a comprehensive overview of the Page Object Model, including the implementation and effective maintenance of your Selenium test automation scripts.
Why do we need Page Object Model in Selenium C#?
Selenium test automation scripts become more complex as the web applications add more features and web pages. With every new page added, new test scenarios are included in the Selenium test automation scripts. With this increase in lines of code, its maintenance can become very tedious and time-consuming. Also, the Repetitive use of web locators and their respective test methods can make the test code difficult to read.
Instead of spending time updating the same set of locators in multiple Selenium test automation scripts, a design pattern such as the Page Object Model can be used to develop and maintain code.
What is Page Object Model In Selenium C#?
Page Object Model is the most widely used design pattern by the Selenium communityfor automation testsin which each web page (or significant ones) is considered as a separate class and a central object repository is created for controls on a web page.
Each Page Object (or page classes) contain the elements of the corresponding web page along with the necessary methods to access the elements on the page.
Thus it is a layer between the test scripts and UI and encapsulates the features of the page.
The Selenium test automation scripts do not interact directly with web elements on the page, instead, a new layer (i.e. page class/page object) resides between the test code and UI on the web page.
Hence, Selenium test automation implementation that uses the Page Object Model in Selenium C# will constitute different classes for each web page thereby making code maintenance easier.
In complex test automation scenarios, automation scripts based on Page Object Model can have several page classes (or page objects). It is recommended that you follow a common nomenclature while coming up with file names (representing page objects) as well as the methods used in the corresponding classes. For example, if automation for a login page & dashboard page is to be performed, our implementation will have a class each for login & dashboard. The controls for the login page are in the ‘login page’ class and the controls for the dashboard page are in the ‘dashboard page’ class.
How to Use Page Object Model:
We will now implement the Page Object Model for the use case we considered above i.e. trying to achieve the addition and subtraction operations for our automation test on the Calculator page. Create a class file – CalculatorPage.csfor Calculator page operation. This page class contains the locator information of the elements on that page. Also, we need to define the methods for that page in the CalculatorPage.cs class and call the methods from UnitTest1.cs.
We are initializing the Chromedriver object and launching the web page from the initialiseDriver() method from UnitTest1.cs. Also, we are creating the instance of CalculatePage from the same method. The CalculatePage.cs contain an instance of IWebDriver and the following methods –
Initialize(): this method takes one IWebDriver object as an input parameter and it is assigned to a locally defined IWebDriver object. Also, the required web page is launched using this driver.
Calculate(): this method is actually used to do the calculation operation of two numbers..either addition or subtraction using 3 input parameters as user input number value1, number value 2, and operator like -’+’ or ‘-’. The required elements from the page are located and as per the operator, the required operation is performed on those. The final code of CalculatePage.cs would look like the below:
public class CalculatePage
{
IWebDriver driver;
public void Initialize(IWebDriver driver)
{
this.driver = driver;
driver.Navigate().GoToUrl("https://www.calculator.net/");
}
public string Calculate(string no1, string op, string no2)
{
IWebElement number1;
char[] ch = no1.ToCharArray();
for (int i = 0; i < no1.Length; i++)
{
number1 = driver.FindElement(By.XPath("//span[@onclick='r(" + ch[i] + ")']"));
number1.Click();
}
IWebElement op_element = driver.FindElement(By.XPath("//span[@onclick=\"r('" +op + "')\"]"));
op_element.Click();
ch = no2.ToCharArray();
for (int i = 0; i < no2.Length; i++)
{
number1 = driver.FindElement(By.XPath("//span[@onclick='r(" + ch[i] + ")']"));
number1.Click();
}
IWebElement result = driver.FindElement(By.Id("sciOutPut"));
string actual_result = result.Text.Trim();
return actual_result;
}
}
Advantages of Page Object Model in Selenium C#:
Page Object Model is a widely used design pattern nowadays. It reduces code duplication, enhances code readability, and improves maintainability by emphasizing reusability and extensibility. Furthermore, below are some of the major advantages of using the Page Object Model in Selenium C#.
Better Maintenance – With separate page objects (or page classes) for different web pages, functionality or web locator changes will have less impact on the change in test scripts. This makes the code cleaner and more maintainable as Selenium test automation implementation is spread across separate page classes.
Minimal Changes Due To UI Updates – The effect of changes in the web locators will only be limited to the page classes, created for automated browser testing of those web pages. This reduces the overall effort spent in changing test scripts due to frequent UI updates.
Reusability – The page object methods defined in different page classes can be reused across Selenium test automation scripts. This, in turn, results in a reduction of code size as there is increased usage of reusability with the Page Object Model in Selenium C#.
Simplification –One more important point of using this design pattern is that it simplifies the visualization of the functionality and model of the web page as both these entities are located in separate page classes.
Execution:
Navigate to Test -> Run All Tests. This will launch the test explorer in Visual Studio and will run our test.
You can run the test from the command prompt or visual studio’s terminal (Developer Command Prompt) with the following command-
dotnet test
This dotnet test command is used to run the tests in the project in the current directory. The dotnet test command builds the solution and runs a test host application for each test project in the solution. While running the tests from the project, you can put different filters while running the test, like running the tests with particular tags, from specific projects, with particular names, etc.
You can find this framework in the following Git Repository.
Implementing the Page Object Model in Selenium with C# provides a structured approach to automation testing, making the code more maintainable and reusable. It simplifies the handling of UI changes and enhances the overall efficiency of the testing process for large-scale applications.
Trupti is a Sr. SDET at SpurQLabs with overall experience of 9 years, mainly in .NET- Web Application Development and UI Test Automation, Manual testing. Having hands-on experience in testing Web applications in Selenium, Specflow and Playwright BDD with C#.
To deliver a good quality of work creating a robust software testing framework is a very important task. Every tester has his/her own approach or method to create a testing framework but the most common and important thing is creating a framework in such a manner that the other testers with minimal knowledge of automation testing can easily utilize the framework. While creating a framework there are some key points that we should consider you will find these points mentioned below.
A good tester is one who has the ability to create a good testing framework. In this blog, I have explained how to create an automation testing framework. Even a beginner with minimal knowledge of automation testing can use this approach to create his own testing framework. There are many more things that you can implement in this explained framework so feel free to comment on it.
When I started my journey as an SDET creating a framework was my first task assigned in my training so I can understand how important it is to create your own framework. Together in this blog, we will see the guidelines I have described which will help us to create a testing framework.
Before we jump into the main topic of our discussion let’s just quickly see the steps we will be following while creating our own framework.
Key Considerations When Creating an Automation Testing Framework:
Understanding the Requirements
Selecting a Testing Framework
Designing Test Cases
Implementing Test Cases
Executing Tests
Maintaining and Improving the Framework
Among the various frameworks present one of the most popular frameworks used for automation testing i.e. the combination of python’s behave library and selenium. In this blog, we are going to explore how to build and use this framework for our automation testing.
As everyone is familiar with Selenium which is an open source and one of the widely used tools for web automation testing along with Playwright and Cypress. Behave is a python library that is used for the BDD (Behavior Driven Development). Let’s just quickly explore what are the different frameworks present out there for automation testing.
A software automation testing framework is designed to make the process of testing software more efficient and easy to use. Every framework has its own advantages and disadvantages as per the given requirement it is most important for us to choose the right framework for automation. Below you will find some of the most commonly used and popular automation frameworks.
Types of Test Automation Frameworks:
Linear Scription Framework.
Modular Testing Framework.
Data-Driven Framework.
Keyword Driven Framework.
Hybrid Framework
Behavior Driven Development Framework.
Test Driven Development Framework.
In this blog, we will be building a BDD framework using Python’s behave library and selenium. In BDD we use the natural language to describe our test scenario divided into steps using the Gherkin language. These test scenarios are present in a feature file and because of the use of natural language, the behavior of the application is easily understandable by all. So, we can say that while creating a BDD framework one of the key components we should consider to use of the feature files and the step files.
As described earlier a feature file is written in natural language with the help of Gherkin language by following a set format. While a step file is an implementation of the steps present in the feature file. Here, a step file is a python file and we can see that it is full of a set of functions where those functions correspond to the steps described in the feature file. Now that we have seen what is feature file and step file let’s see what is the use of python’s behave library here, so basically once the steps and feature file are ready the behave will start automatically matching the steps present in the feature file with its corresponding implementation in the step file and will also check for any assertion errors present.
5. We can also install all the required packages using the requirement.txt file using the below command.
pip install -r requirement.txt
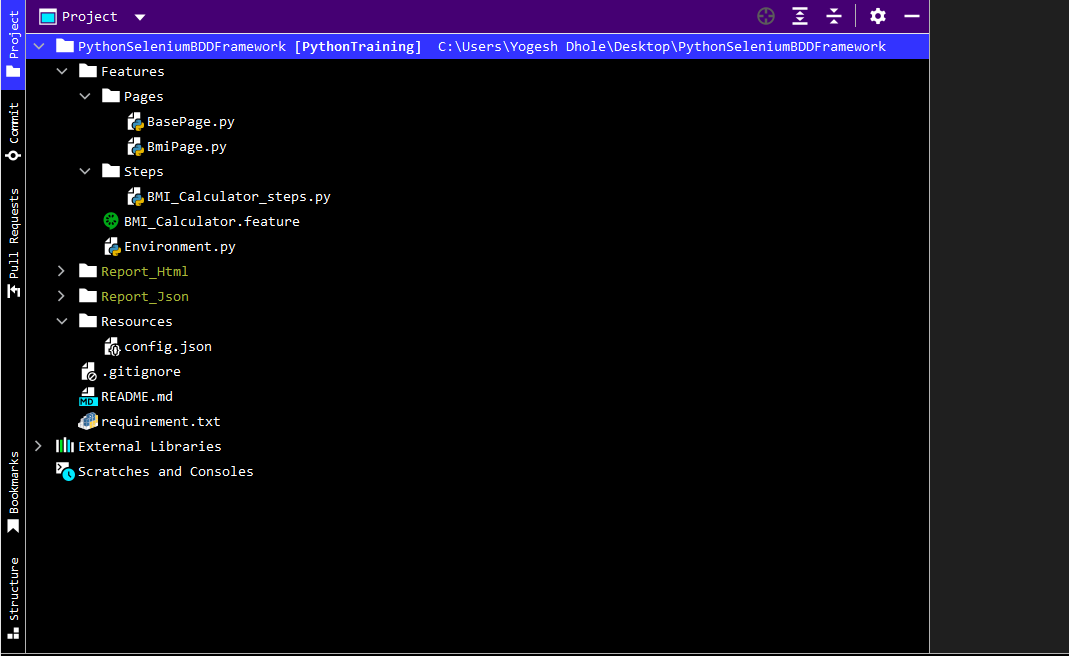
Framework Structure Overview:
Here is the overview of our python selenium behave BDD framework.
As a beginning, we are going to start with creating a simple framework using one scenario outline. In the next blog, we are going to see how to create an API testing framework using python. To understand both of them please read the blog carefully as I am explaining all the points here in natural language, without wasting any time let’s dive into the main topic of our discussion i.e. how to create python selenium behave BDD automation testing framework.
For this, we will follow some guidelines which I have described as steps.
Step 1:
Create a project in Pycharm (here I am using Pycharm professional) and as mentioned in the prerequisites install the packages.
It is not compulsory to use pycharm professional we can use pycharm community as well.
Step 2:
In this step, we will be creating a Features folder in which we will be creating our feature files for different scenarios. A feature file is something that holds your test cases in the form of a scenario and scenario outline. In this framework, we are using a scenario outline. Both scenario and scenario outline contain steps that are easy to understand for non-technical persons. We can also assign tags for the feature files and for the scenarios present in that file. Note that the feature file should end with a .feature extension.
Feature: Create test cases using Selenium with Python to automate below BMI calculator tests
# We are using Scenario Outline in this feature as we can add multiple input data using examples.
Scenario Outline: Calculating BMI value by passing multiple inputs
Given I enter the "<Age>"
When I Click on "<Gender>"
And I Enter a "<Height>"
And I Enter the "<Weight>"
And I Click on Calculate btn
And I Verify Result with "<Expected Result>"
Examples:
| Age | Gender | Height | Weight | Expected Result |
| 20 | Male | 180 | 60 | BMI = 18.5 kg/m2|
| 35 | Female | 160 | 55 | BMI = 21.5 kg/m2|
| 50 | Male | 175 | 65 | BMI = 21.2 kg/m2|
| 45 | Female | 150 | 52 | BMI = 23.1 kg/m2|
Step 3:
Now, we have our feature file let’s create a step file to implement the steps described in the feature file. In order to recognize the step file we are adding step work after the name so that behavior will come to know the step file for that particular feature file. Both feature files and step files are essential parts of the BDD framework. We have to be careful while describing the steps in the feature file because we have to use the same steps in the step file so that behavior will understand and map the step implementation.
from behave import *
# The step file contains the implementation of the steps that we have described in the feature file.
@given('I enter the "{Age}"')
def step_impl(context, Age):
context.bmipage.age_input(Age)
@when('I Click on "{Gender}"')
def step_impl(context, Gender):
context.bmipage.gender_radio(Gender)
@step('I Enter a "{height}"')
def step_impl(context, height):
context.bmipage.height_input(height)
@step('I Enter the "{weight}"')
def step_impl(context, weight):
context.bmipage.weight_input(weight)
@step("I Click on Calculate btn")
def step_impl(context):
context.bmipage.calculatebtn_click()
@step('I Verify Result with "{expresult}"')
def step_impl(context, expresult):
context.bmipage.result_validation(expresult)
Step 4:
In step 4 we will be creating a page file that contains all the locators and the action methods to perform the particular action on the web element. We are going to add all the locators at the class level only and will be using them in the respective methods. The reason behind doing so is it is a good practice to declare your locators at the class level as when the locators get changed it is effortless to replace them and we don’t have to go through the whole code again.
from selenium.webdriver.common.by import By
import time
from Features.Pages.BasePage import BasePage
# The page contains all the locators and the actions to perform on that web element.
# In this page file we have declared all the locators at the class level and we are using them in the respective methods.
class BmiPage (BasePage):
def __init__(self, context):
BasePage.__init__(self, context.driver)
self.context = context
self.age_xpath = "//input[@id='cage']"
self.height_xpath = "//input[@id='cheightmeter']"
self.weight_xpath = "//input[@id='ckg']"
self.calculatebtn_xpath = "//input[@value='Calculate']"
self.actual_result_xpath = "//body[1]/div[3]/div[1]/div[4]/div[1]/b[1]"
def age_input(self, Age):
AgeInput = self.driver.find_element(By.XPATH, self.age_xpath)
AgeInput.clear()
AgeInput.send_keys(Age)
time.sleep(2)
def gender_radio(self, Gender):
SelectGender = self.driver.find_element(By.XPATH, "//label[normalize-space()='" + Gender+"']")
SelectGender.click()
time.sleep(2)
def height_input(self, height):
HeightInput = self.driver.find_element(By.XPATH, self.height_xpath)
HeightInput.clear()
HeightInput.send_keys(height)
time.sleep(3)
def weight_input(self, weight):
WeightInput = self.driver.find_element(By.XPATH, self.weight_xpath)
WeightInput.clear()
WeightInput.send_keys(weight)
time.sleep(3)
def calculatebtn_click(self):
Calculatebtn = self.driver.find_element(By.XPATH, "//input[@value='Calculate']")
Calculatebtn.click()
time.sleep(3)
def result_validation(self, expresult):
try:
Result = self.driver.find_element(By.XPATH, "//body[1]/div[3]/div[1]/div[4]/div[1]/b[1]")
Actualresult = Result.text
Expectedresult = expresult
assert Actualresult == Expectedresult, "Expected Result Matched"
time.sleep(5)
except:
self.driver.close()
assert False, "Expected Result mismatched"
The next one is the base page file. We are creating a base page file to make an object of the driver so that we can easily use that for our page and environment file.
from selenium.webdriver.support.wait import WebDriverWait
# In the base page we are creating an object of driver.
# We are using this driver in the other pages and environment page.
class BasePage(object):
def __init__(self, driver):
self.driver = driver
self.wait = WebDriverWait(self.driver, 30)
self.implicit_wait = 25
Step 5:
This step is very important because we will be creating an environment file (i.e. Hooks file). This file contains hooks for before and after scenarios to start and close the browser. Also if you want you can add after-step hooks for capturing screenshots for reporting. We have added a method to capture screenshots after every step and will attach them to the allure report.
import json
import time
from allure_commons._allure import attach
from allure_commons.types import AttachmentType
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from Pages.BasePage import BasePage
from Pages.BmiPage import BmiPage
data = json.load(open("Resources/config.json"))
# This environment page is used as hooks page. Here we can notice that we have used before, after hooks along side with some step hooks.
def before_scenario(context, scenario):
context.driver = webdriver.Chrome(ChromeDriverManager().install())
time.sleep(5)
basepage = BasePage(context.driver)
context.bmipage = BmiPage(basepage)
context.stepid = 1
context.driver.get(data['BMIWEBURL'])
context.driver.maximize_window()
context.driver.implicitly_wait(3)
def after_step(context, step):
attach(context.driver.get_screenshot_as_png(), name=context.stepid, attachment_type=AttachmentType.PNG)
context.stepid = context.stepid + 1
def after_scenario(context, scenario):
context.driver.close()
Step 6:
It is a good practice to store all our common data and files in a resource folder. So, whenever we need to make changes it will be easy to implement them for the whole framework. For now, we are adding a config.json file in the resource folder. This file contains the web URL used before the scenario to launch the web page for the specified tag in the feature file. The file is written in JSON format.
Congratulations, finally we have created our own Python Selenium Behave BDD framework. As I mentioned earlier we will be using Allure for reporting the test result. For this use the below command in the terminal and it will generate the result folder for you.
Creating a testing framework is very important as well as feels like a tedious task but with the right guidelines, everyone can create a testing framework. I hope in this blog I have provided all the answers related to the python selenium behavior automation testing framework. Here, we choose a BDD framework over other existing frameworks because of its better understanding, easy to adapt, and easy to understand for end users. If you still have any issues related to what we have seen earlier feel free to comment them down we will solve them together. There are many more things we can add to this existing framework but to get started I feel this framework is enough and will cover most of the requirements.
For any web automation testing, the one and most important task is to identify and use robust locators to identify web elements so that your automated tests do not fail with “Unable to locate element”. In this article, we are providing you with the techniques that every tester should learn to create those robust locators. As we already know this can be done using different locator strategies. In this blog, we are going to learn about XPath. Before we dive into the topic of our discussion let’s just get more familiar with Xpaths. Let’s start with,
What is XPath?
XPath (XML Path Language) is an expression language that allows the processing of values conforming to the data model defined in the XQuery and XPath Data models. Basically, it is a query language that we use to locate or find an element present on the webpage. It is defined by the World Wide Consortium (W3C). Now, let’s discuss why Xpaths are necessary.
Why is XPaths necessary?
Xpaths are the most widely used locators in automation though there are other locators like id, name, class name, tag name, and so on. Also, it is used when there are no unique attributes available to locate the web element. It allows identification with the help of the visible test present on the screen with the help of Xpath function text().
Before explaining the importance of XPath let’s just go through the different types of locators available for automation testing.
In this blog, we will learn about the different types of Xpaths and how to implement them so that we can locate our web elements quickly using the selenium web driver. Basically, there are two types of Xpaths
1. Absolute XPath:
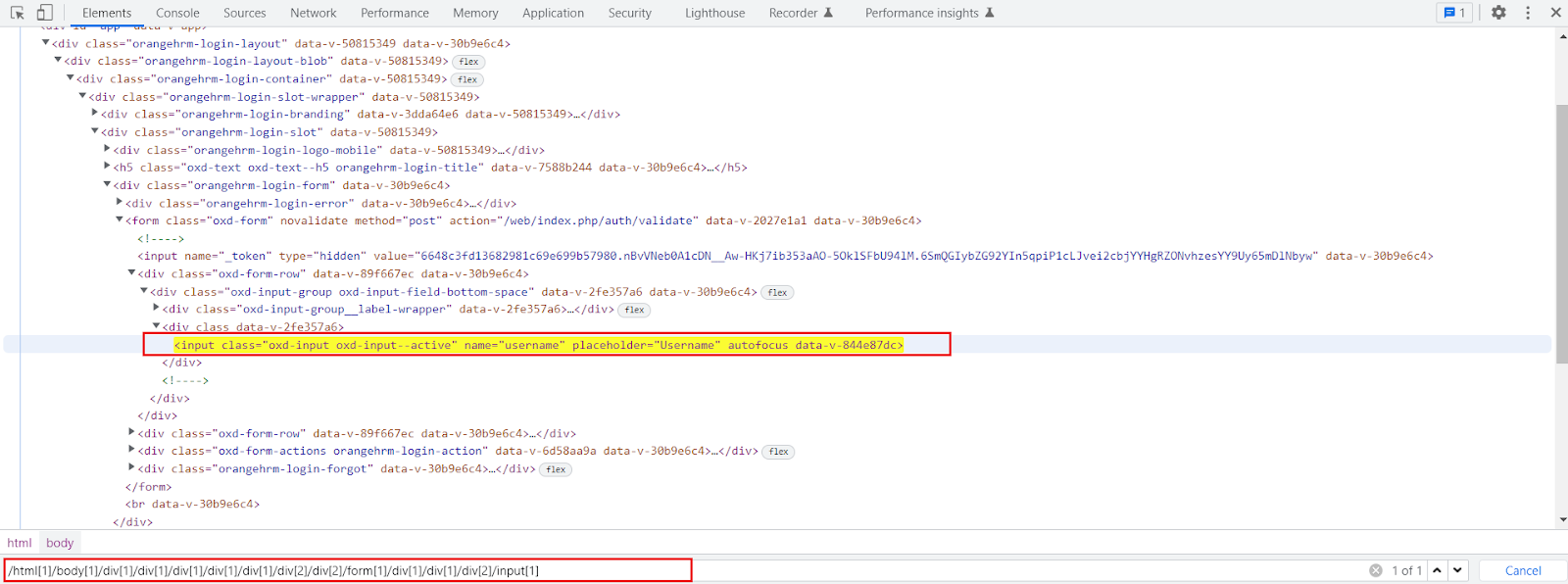
In this type, The XPath starts from the beginning or from the root node of the HTML DOM structure. It is a direct way to locate or find the web element but the disadvantage of absolute XPath is that as we are creating it from the start of the HTML DOM structure if there are any changes introduced in the created path of the web element then it gets failed. In this type of locator, we only use tags or nodes. The main advantage of this is that we can select a web element from the root node as it starts with the single forward slash “ / ”.
Example:
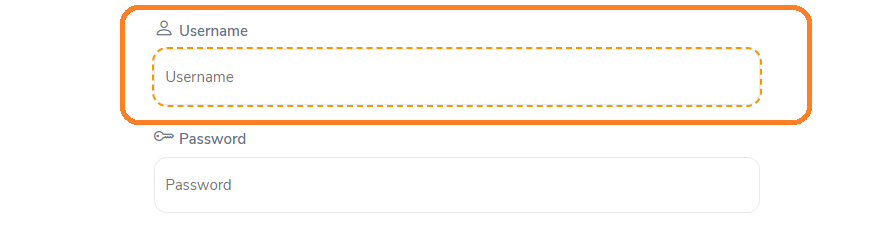
Here is an example of an absolute Xpath for an input field box.
The absolute XPath is: /html[1]/body[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[2]/div[2]/form[1]/div[1]/div[1]/div[2]/input[1]
2. Relative Xpath:
Compared to an absolute XPath the relative XPath does not start from the beginning of the HTML DOM structure. It starts from where the element is present e.g. from the middle of the HTML DOM structure if the element is located there. We don’t have to travel from the start of the HTML DOM structure. The relative Xpath starts with a double forward slash “ // “ and it can locate and search the web element anywhere on the webpage. Relative XPath directly jumps to elements on DOM. The other difference between absolute and relative XPath is that in absolute XPath we use tags or nodes but in relative XPath we use attributes.
Example:
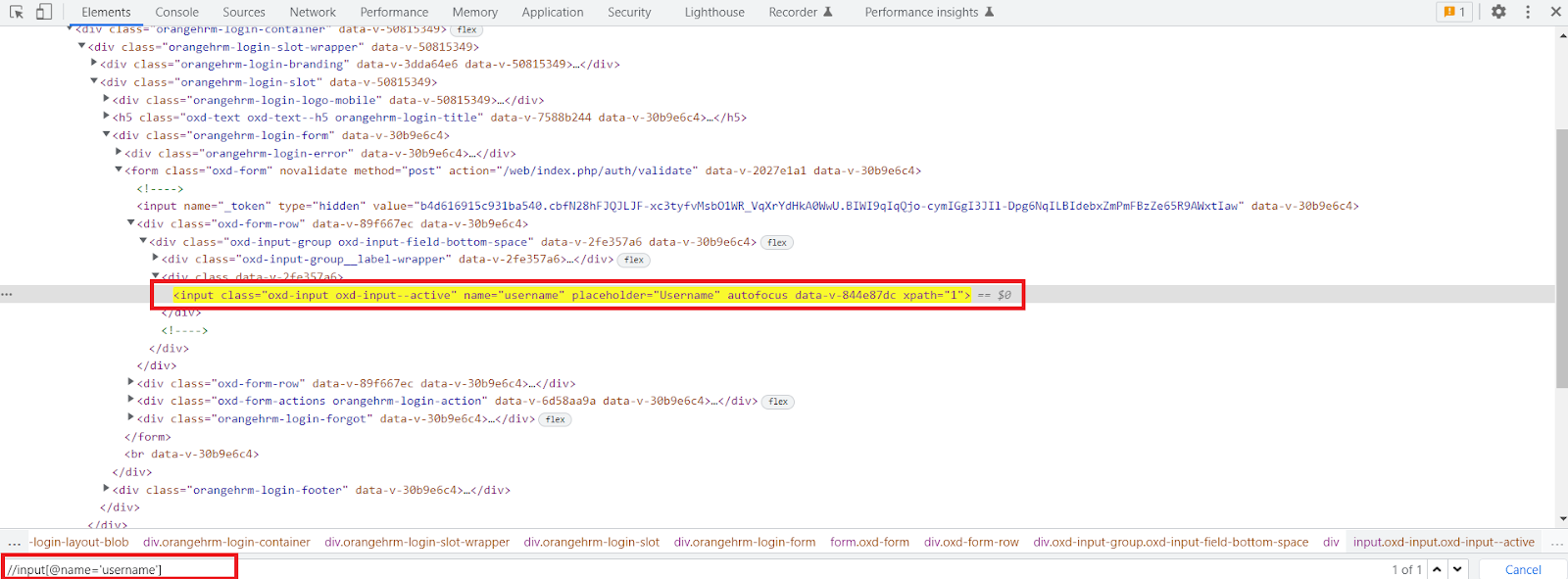
We are writing the relative XPath for the same input field for which earlier we created an absolute XPath.
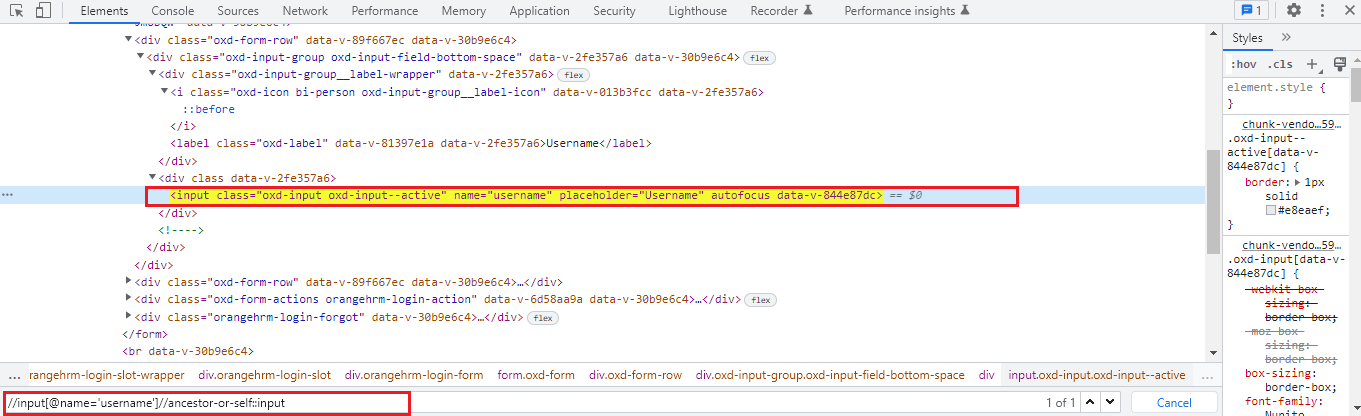
Relative XPath is:
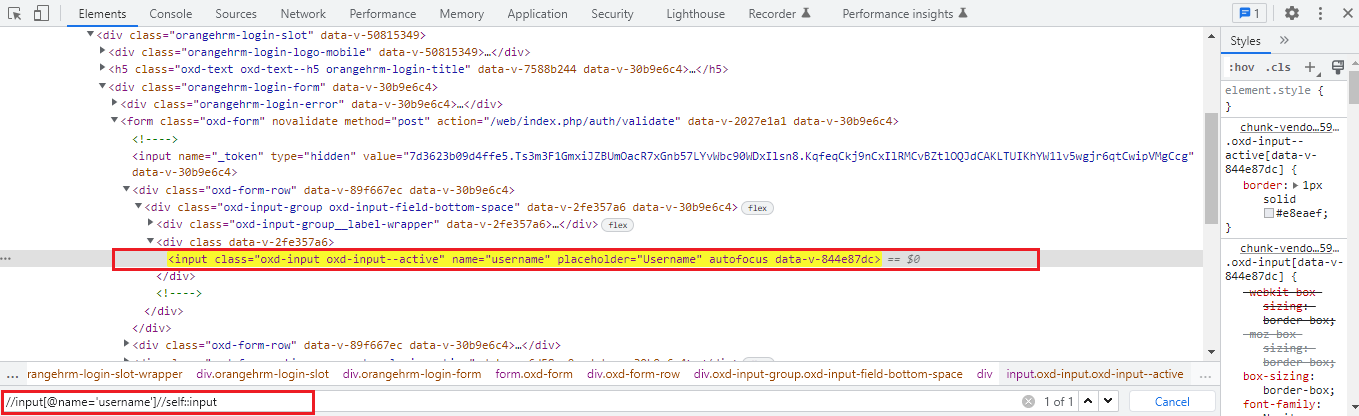
//input[@name=’username’]
XPath Functions:
It is not always possible to locate a web element using relative XPath that is because at some times while locating a particular web element there is the possibility of elements that have similar properties, for example, the same id, name, or same class name. So, here the basic XPath won’t work efficiently for finding that web element. Xpath functions are used to write the efficient XPath by locating a web element with a unique value. Basically, there are three types of XPath functions as follows,
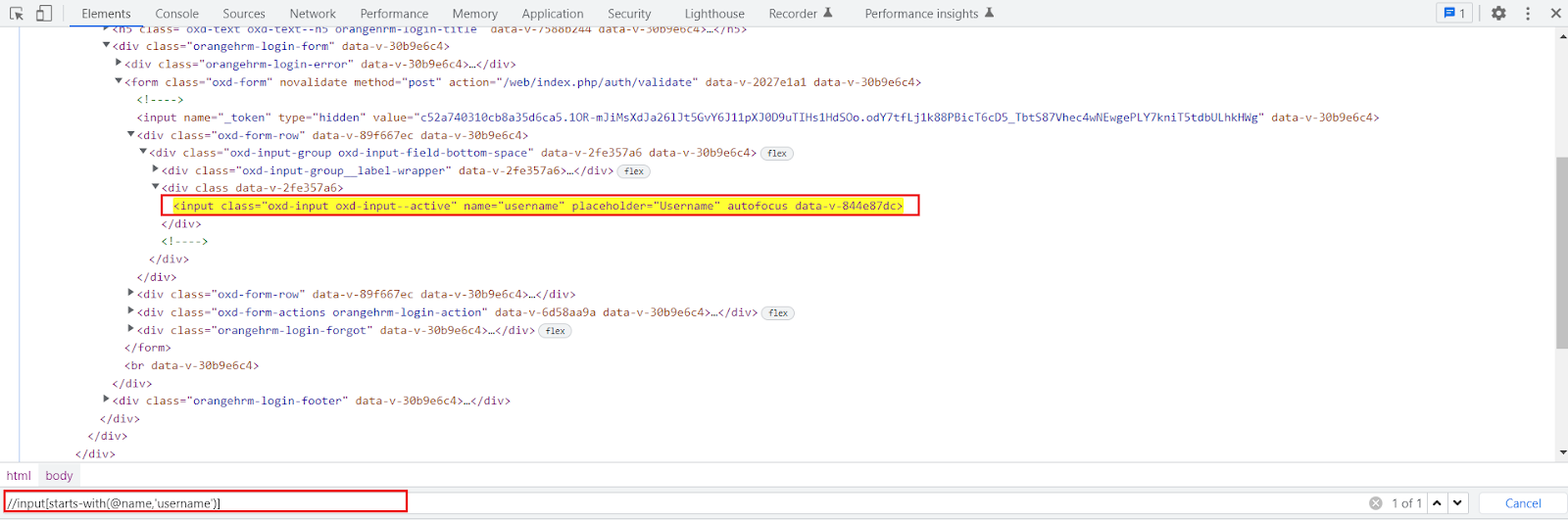
a. starts-with() Function:
starts-with() function is very useful in locating dynamic web elements. It is used to find the element in which the attribute value starts with some particular character or text.
While working on the dynamic web page the starts-with function plays an important role. We can use it to match the starting value of a web element that remains static.
It can also locate the web element whose attribute value is static.
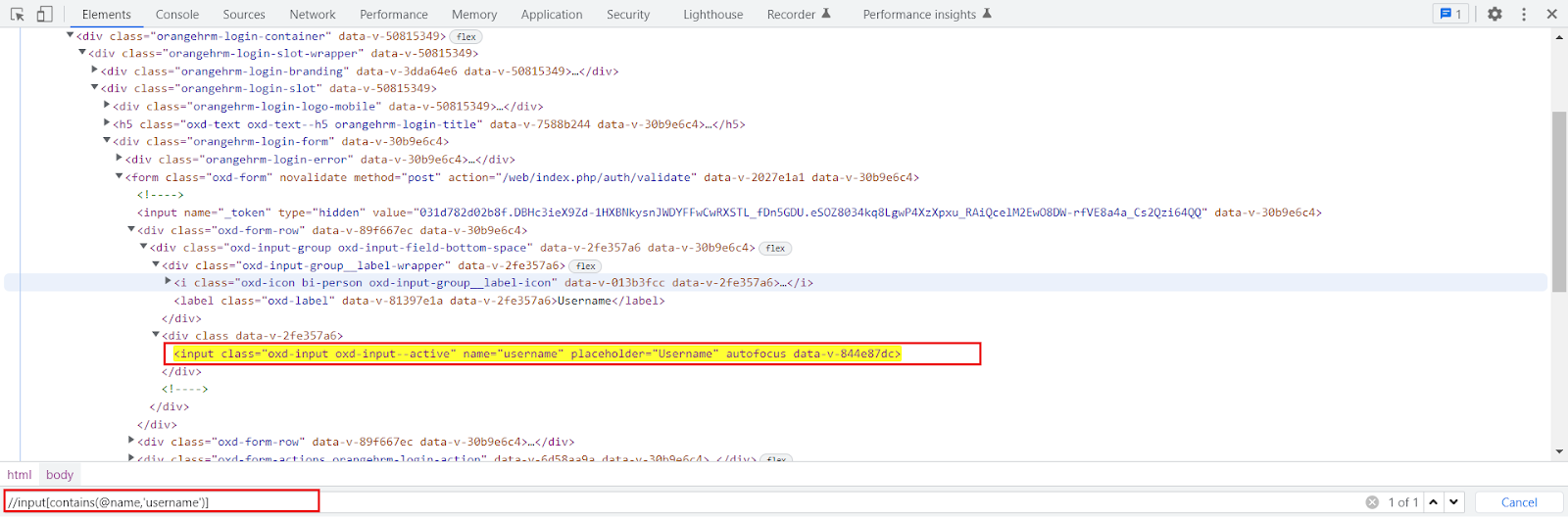
Just like the start-with() function explained above, the contains() function is also used to create a unique expression to locate a web element.
It is used when if a part of the value of an attribute changes dynamically the function can navigate to the web element with the partial text present.
We can provide any partial attribute value to locate the web element.
It accepts two parameters the first one is the attribute of the tag must validate to locate the web element and the second one is the value of an attribute is a partial value that the attribute must contain.
Syntax:
Xpath = //tagname[contains(@attribute,’value’)]
Example:
//input[contains(@name,’username’)]
c. text() Function:
text() Function:
The text() function is used to locate web elements with exact text matches.
The function only works if the element contains the text.
This method returns the text of the web element when identified by the tag name and compared it with the value provided on the right side.
Syntax:
Xpath = //tagname[text()=’Actual text present’]
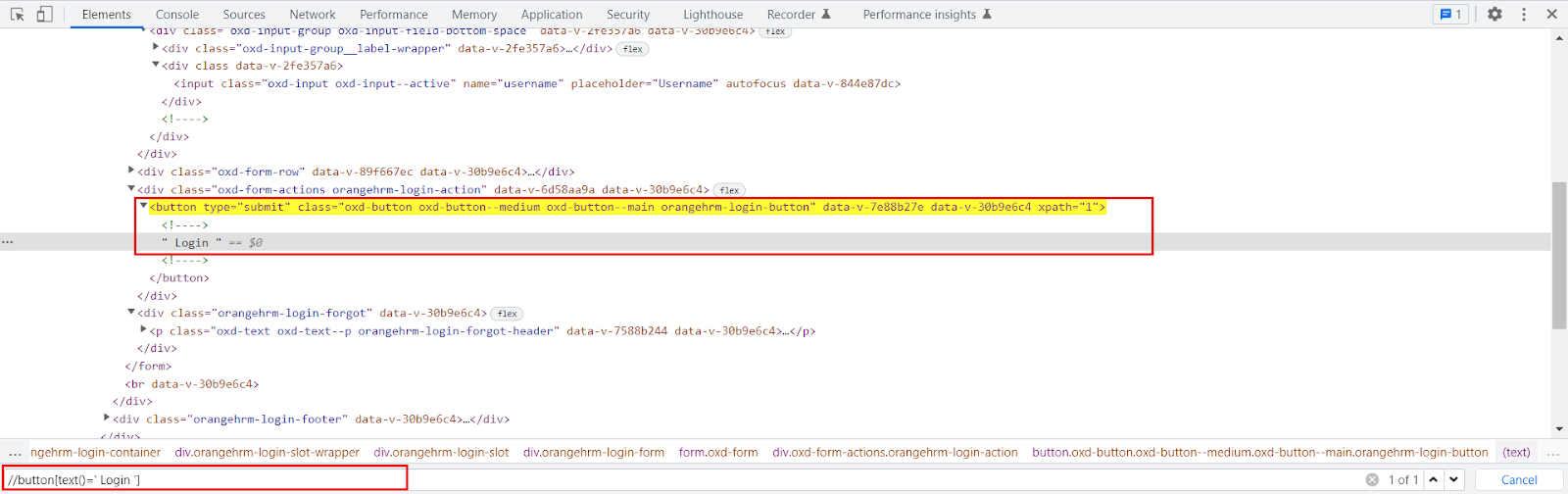
Example:
//button[text()=’ Login ‘]
How to use AND & OR in XPath:
AND & OR expressions can also be used in selenium Xpath expressions. Very useful if you want to use more than two attributes to find elements on a webpage.
The OR expression requires two conditions and it will check whether the first condition in the statement is true if so then it will locate that web element and if not then it will go for the second condition and if that is true then also it will locate that web element. So, here the point we should remember is that when we are using the OR expression at least either of two of the conditions should be true then, and then only it will find and locate that web element.
Syntax:
Xpath = //tagname[@attribute=’Value’ or @attribute=’Value’]
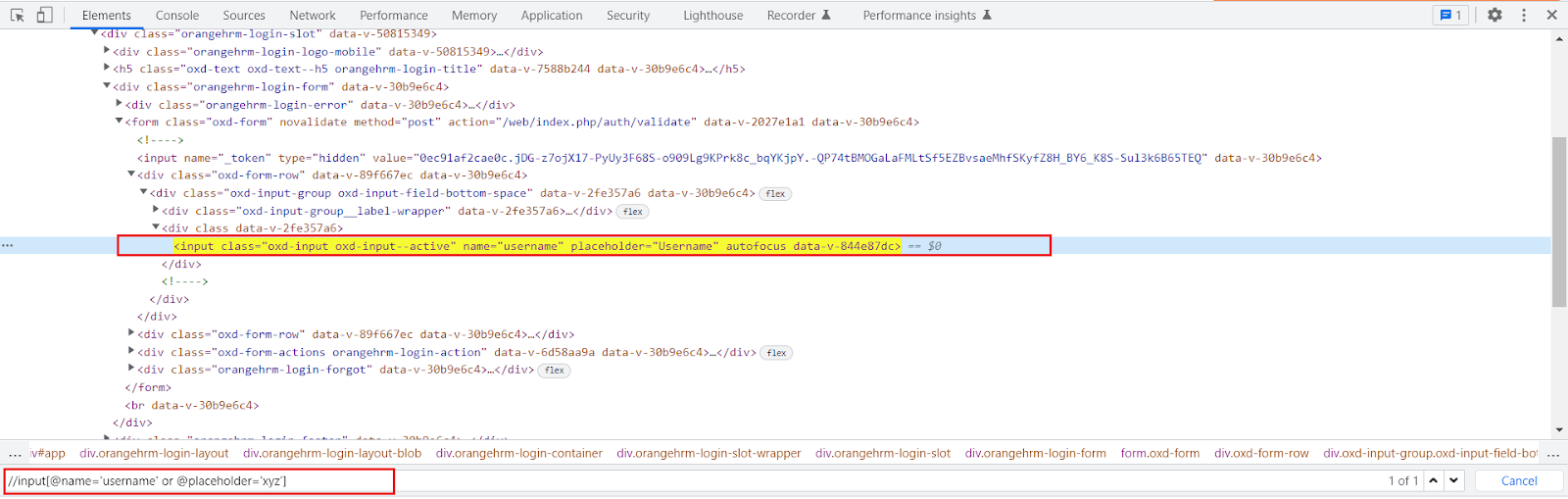
Example:
//input[@name=’username’ or @placeholder=’xyz’]
Here the first condition is true and the second one is false still the web element got located.
Just like the OR expression the AND expression also requires two conditions but the catch here is that both the provided condition must be true then and then only the web element will get located. If either of the conditions is false then it will not locate that web element.
Syntax:
Xpath = //tagname[@attribute=’Value’ and @attribute=’Value’]
Example:
//input[@name=’username’ and @placeholder=’Username’]
In this case, both the condition provided for an AND expression is true hence the web element got located.
XPath Axis:
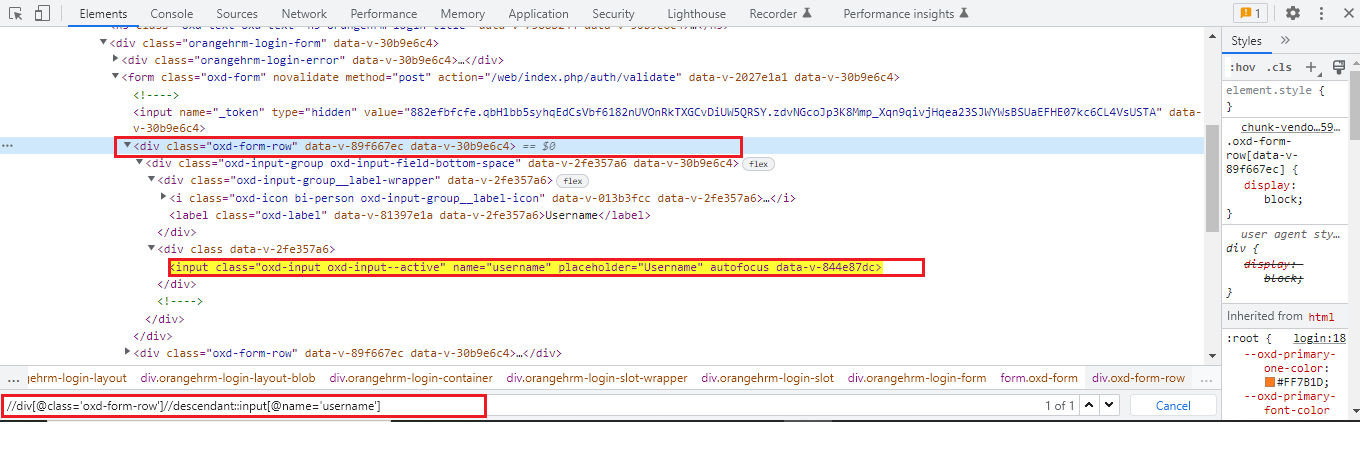
It is a method to identify those dynamic elements that are impossible to find by normal XPath methods. All the elements are in a hierarchical structure and can be either located using absolute or relative Xpaths but it provides specific attributes called XPath axis to locate those elements with unique XPath expressions. The axes show a relationship to the current node and help locate the relative nodes concerning the tree’s current node. The dynamic elements are those elements on the webpage whose attributes dynamically change on refresh or any other operations. The HTML DOM structure contains one or more element nodes and they are known as trees of nodes. If an element contains the content, whether it is other elements or text, it must be declared with a start tag and an end tag. The text defined between the start tag and the end tag is the element content.
Types of XPath Axis:
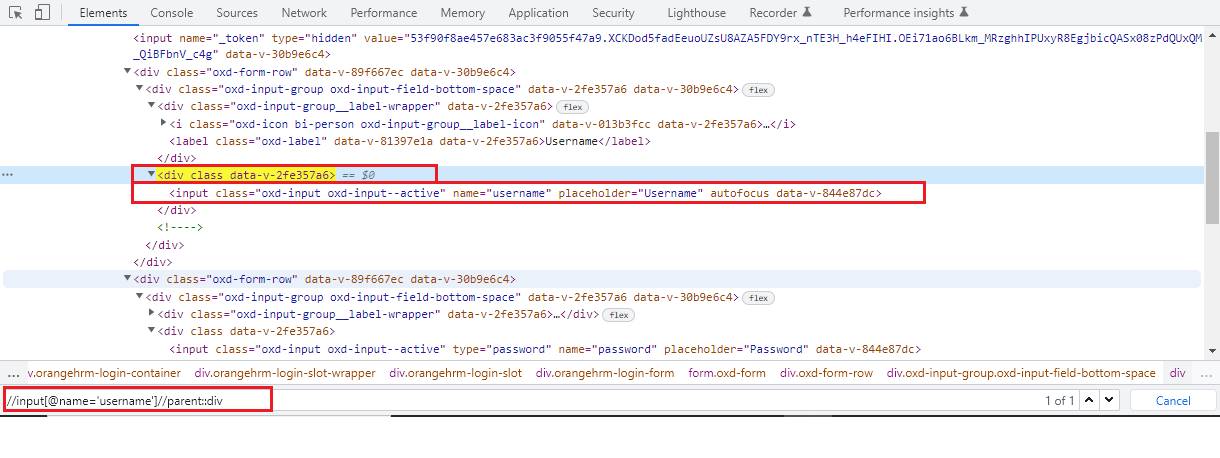
1. Parent Axis XPath:
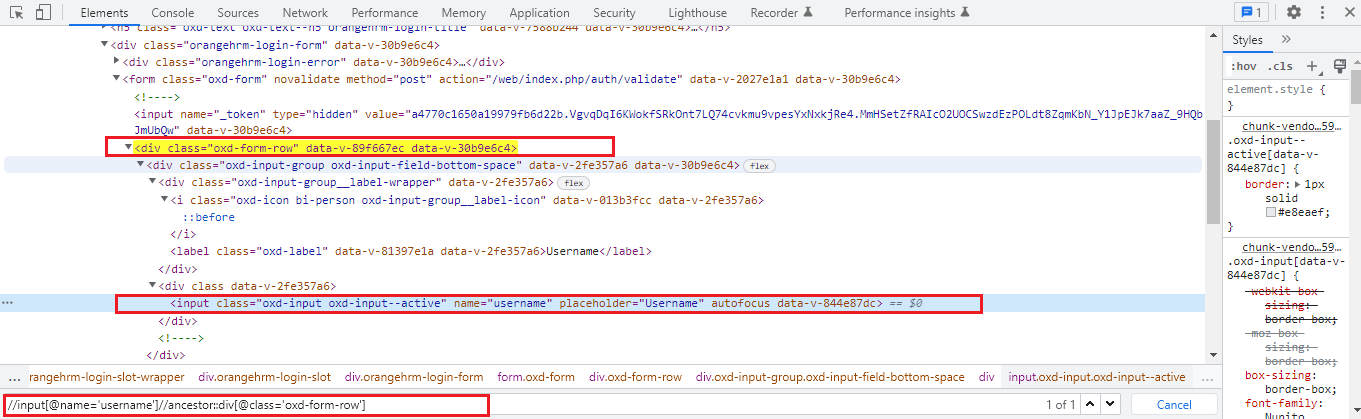
With the help of the parent axis XPath, we can select the parent of the current node. Here, the parent node can be either a root node or an element node. The point to consider here is that for all the other element nodes the maximum node the parent axis contains is one. Also, the root node of the HTML DOM structure has no parent hence the parent axis is empty when the current node is the root node.
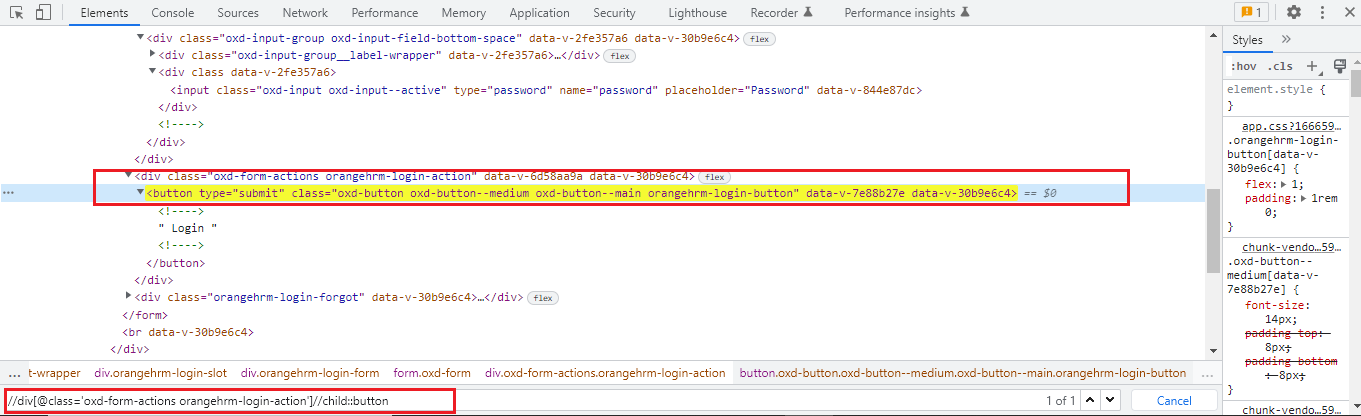
As we have seen using the parent axis XPath actually we are creating an XPath by the following bottom-up approach but here in the child axis case, we are going to follow the top-down approach to create an XPath. The child axis selects all the child elements present under the current node. We can easily locate a web element as a child of the current node.
This type of XPath uses its own current node and selects the web element belonging to that current node. You will always observe only one node that represents the self-web element. The tag name we provide at the start and at the end of XPath are the same as they are on the self-axis of the current node. However, this provides the confirmation of the element present when there is more than one element present having the same value and attribute.
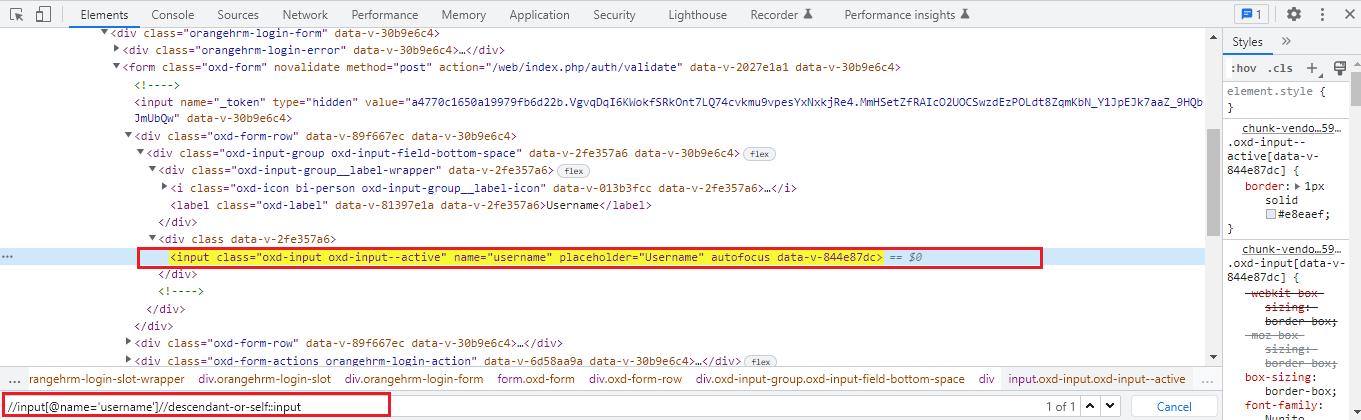
Using this axis we can select the current node and all its descendants i.e. child, grandchild, etc just like a descendant axis. The point to be noticed here is the tag name for descendants and self are the same.
As we understand how the descendant axis works now, the ancestor axis works exactly opposite to that of the descendant axis. It will select or locate all ancestors elements i.e. parent, grandparent, etc of the current node. This axis contains the root node too.
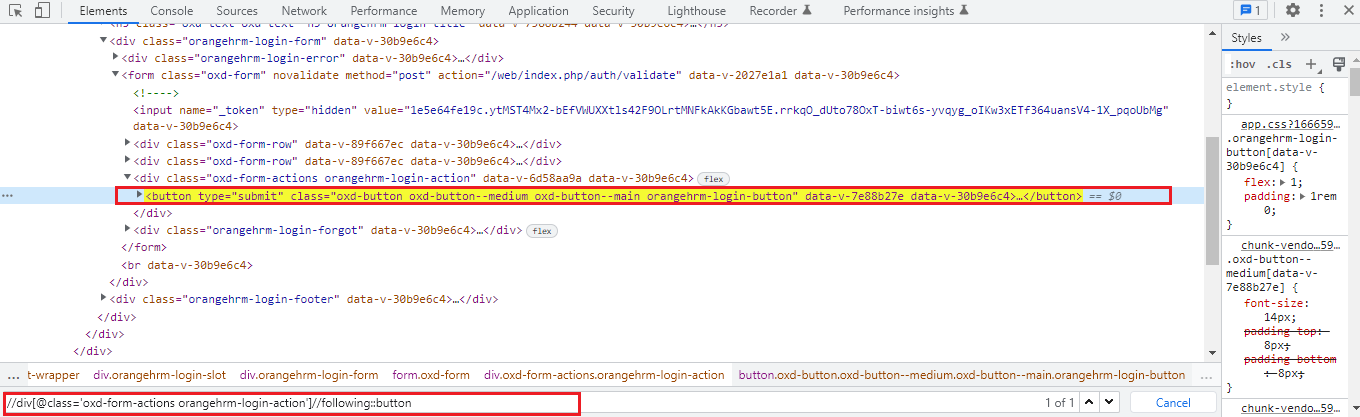
Using the following sibling axis method we can select all the nodes that have the same parent as that of the current node and that appear after the current node.
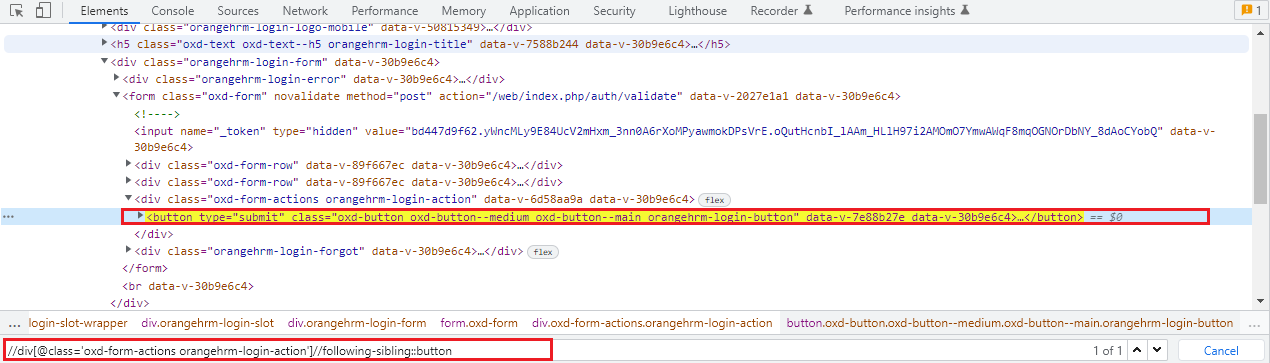
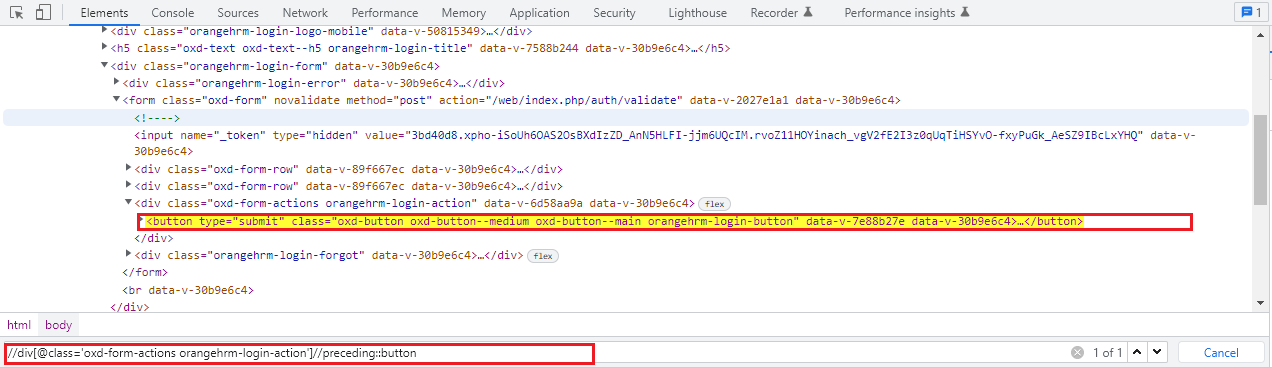
Using the following sibling axis method we can select all the nodes that have the same parent as that of the current node and that appear before the current node. It works opposite to that of the following sibling axis XPath.
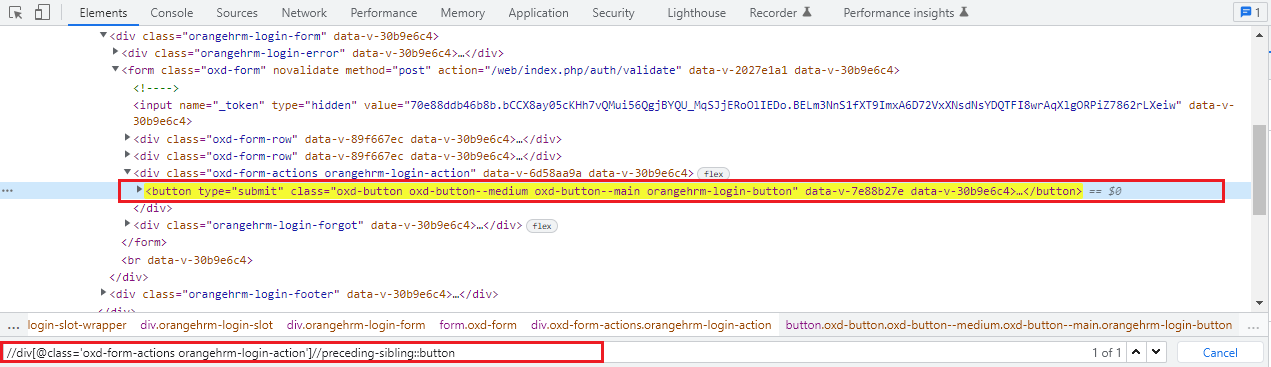
You can try all of these examples mentioned above with the Orange HRM Demo website here.
Conclusion:
In conclusion, XPath is an essential tool for web automation testing when using Selenium, Playwright, and Cypress. It allows for more flexibility and specificity in locating elements on a web page. Understanding the different types of XPath expressions and how to use them can greatly improve the efficiency and effectiveness of the automation testing process. It can be particularly useful in situations where elements do not have unique CSS selectors, or when the structure of the HTML changes frequently. With the knowledge of XPath, you can write more robust and stable automation tests.
What is the Robot class? and why I must use robot class in my Selenium automation framework as a Selenium automation engineer.
Hello, my name is Vishal, and in this blog, I will explain why you should use robot class. I was working on a project for one of our clients, and I was asked to test the web-file application’s upload feature. There was a button, and once we click the button, a window pop-up appeared, and I was asked to upload the file to the server of that web application. I was able to automate up until the button clicking part through selenium, but I was unable to automate the window’s pop using Selenium. I tried almost everything to automate that pop-up but failed. After doing some research, I got to know that we cannot use the Selenium application to automate the windows pop-ups.
Then I did more research on the subject and got to know about the Robot class.
What is Robot Class?
Before we start talking about how to use the robot class, we will first learn the basics of the robot class.
We deal with popups and alert many times in the java selenium web automation, using a method like a driver.switchTo(). Most of them can be easily handled using submethods like a driver.switchTo().alert().dismiss() or driver.switchTo().alert().accept() methods. But what if the pop-ups are system-generated, as shown in the following image?
As these pop-ups are not related to the webpage or browser, selenium will not be able to handle these pop-ups. In that case, we use robot class to tackle these situations.
Selenium’s Robot Class is used to enable automated testing for Java platform implementations. It generates input events in native systems for Test Automation, Self-Running Demos, and other applications that require mouse and keyboard control. It is simple to implement and integrate with an automated framework.
So this was about the introduction. In the next section of this, we will learn how to use that.
How to use robot class in selenium?
To understand how to use robot class in selenium, I am using this website. This website allows you to upload sample files.
So, before we begin automating, we must first comprehend the operation that will be carried out on this application. My primary goal here is to upload a text file from my machine’s download folder to the server of that web application. On that webpage, there is a button, and when we click it, a window appears, and I am asked to select the file that I want to upload to the server.
As previously stated, we will be able to automate up to the button-clicking stage, but we will be unable to control the windows pop-up using Selenium.
So, to control that part, we’ll use the robot class. You can use the following code.
public static void main(String[] args) throws AWTException, InterruptedException {
//Initialize the Web-driver
driver = driverSetUpForChrome();
driver.get("https://cgi-lib.berkeley.edu/ex/fup.html");
String title = driver.getTitle();
System.out.println("Title of the page is "+ title);
// Locate the upload button
WebElement uploadButton = driver.findElement(By.xpath("//form//input[@Name=\"upfile\"]"));
StringSelection s = new StringSelection("C:\\Downloads\\SampleText.txt");
// Clipboard copy
Toolkit.getDefaultToolkit().getSystemClipboard().setContents(s,null);
Actions actions = new Actions(driver);
actions.click(uploadButton).build().perform();
WebElement noteFiled = driver.findElement(By.xpath("//form//input[@Name=\"note\"]"));
actions.click(noteFiled).sendKeys("Uploading the text file.").build().perform();
WebElement pressButton = driver.findElement(By.xpath("//form//input[@type=\"submit\"]"));
actions.click(pressButton).build().perform();
}
public static WebDriver driverSetUpForChrome() {
WebDriverManager.chromedriver().setup();
WebDriver driver = new ChromeDriver();
return driver;
}
public static void quitDriver() {
driver.quit();
}
}
When you run the above code, a pop-up window similar to the one shown below will appear on your screen. The system will prompt you for a file name here. In this case, we’ll use the robot class to select the file to upload to the server.
To do so, we must first copy the file to the clipboard. Which we can do with the following line of code.
StringSelection s = new StringSelection("C:\\Downloads\\SampleText.txt");
// Clipboard copy
Toolkit.getDefaultToolkit().getSystemClipboard().setContents(s,null);
So, using the toolkit class, we copied the path to a string, which we need to paste into the pop window’s file field. We already know that we can copy and paste the content into fields by pressing the keyboard’s control and V buttons. Using the robot class, we will do the same thing.
To paste the copied file path, use the code below.
Now, after pasting the file path, we need to press the enter key to select the file. we can do with the code below.
r.keyPress(KeyEvent.VK_ENTER);
//releasing enter
r.keyRelease(KeyEvent.VK_ENTER);
We have successfully uploaded the file to the server in this manner.
So this is how we can use the robot class to handle window pop-ups.
The complete code is provided below.
//import dev.failsafe.internal.util.Assert;
import io.github.bonigarcia.wdm.WebDriverManager;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.interactions.Actions;
import java.awt.*;
import java.awt.datatransfer.StringSelection;
import java.awt.event.KeyEvent;
public class SeleniumExample {
private static WebDriver driver = null;
public static void main(String[] args) throws AWTException, InterruptedException {
//Initialize the Web-driver
driver = driverSetUpForChrome();
driver.get("https://cgi-lib.berkeley.edu/ex/fup.html");
String title = driver.getTitle();
System.out.println("Title of the page is "+ title);
// Locate the upload button
WebElement uploadButton = driver.findElement(By.xpath("//form//input[@Name=\"upfile\"]"));
StringSelection s = new StringSelection("C:\\Downloads\\SampleText.txt");
// Clipboard copy
Toolkit.getDefaultToolkit().getSystemClipboard().setContents(s,null);
Actions actions = new Actions(driver);
actions.click(uploadButton).build().perform();
Robot r = new Robot();
//pressing enter
//pressing ctrl+v
Thread.sleep(1000);
r.keyPress(KeyEvent.VK_CONTROL);
r.keyPress(KeyEvent.VK_V);
//releasing ctrl+v
Thread.sleep(1000);
r.keyRelease(KeyEvent.VK_CONTROL);
r.keyRelease(KeyEvent.VK_V);
//pressing enter
r.keyPress(KeyEvent.VK_ENTER);
//releasing enter
r.keyRelease(KeyEvent.VK_ENTER);
WebElement noteFiled = driver.findElement(By.xpath("//form//input[@Name=\"note\"]"));
actions.click(noteFiled).sendKeys("Uploading the text file.").build().perform();
WebElement pressButton = driver.findElement(By.xpath("//form//input[@type=\"submit\"]"));
actions.click(pressButton).build().perform();
}
public static WebDriver driverSetUpForChrome() {
WebDriverManager.chromedriver().setup();
WebDriver driver = new ChromeDriver();
return driver;
}
public static void quitDriver() {
driver.quit();
}
}
More about Robot Class Methods and Use:
In this section, we will learn more about the feature and its uses.
Robot robot = new Robot();
At this line, we are initializing the robot class.
keyPress():
For example robot.keyPress(KeyEvent.VK DOWN): This function is one keyword and that keyword is the name of the button that you want to press. For example, if you want to press button V then you will have to pass the following object:
KeyEvent.VK_V
mousePress():
For example, robot.mousePress(InputEvent.BUTTON3 DOWN MASK) will perform a right mouse click.
mouseMove():
For example, robot.mouseMove(point.getX(), point.getY()) will move the mouse cursor to the X and Y coordinates supplied.
keyRelease():
For example, robot.keyRelease(KeyEvent.VK DOWN): This method releases the Keyboard’s down arrow key. If there are any keys that you have pressed using the KeyPress function, then you can use this function to release those keys. – mouseRelease(): For example, robot.mouseRelease(InputEvent.BUTTON3 DOWN MASK): This method will release your mouse’s right click.
Conclusion:
So, in this way, we learned about the robot class and its application in this blog. I hope you got the information you were looking for. please share it with your testing squad, and if you have any suggestions or questions, please leave them in the comment section.
Vishal is proficient in a variety of programming languages, including Python, Java, and Javascript, C++, Jpython, C. He has also worked on a number of testing technologies, such as playright, selenium, and helenium. He is an tie loathing adventurer and thrill seeker, who believes in turning ideas into reality…
This article provides you with a solution for downloading a file using python and selenium in a folder. Handling files can be a tedious task at times. Especially, when you have test scenarios like downloading a file and verifying if the file is downloaded and if yes then delete the downloaded file.
Despite visiting many websites and reading many articles, I was not able to find the right solution. Here, I am providing all the solutions in one place, as visiting multiple web pages to find a single solution is tiring. Here, we are using the python and selenium combination to download a file in a folder. You can use the language you like for example, java, javascript, c#, etc. After reading this article, you will get to know how you can handle this type of scenario and we will solve this issue together. So just follow the steps described.
Traditional Approach:
When you download any file from the website it generally gets downloaded in your download folder i.e. on your local system, but here, is what we are doing we are creating a folder download in our framework. Then we download that file in this newly created folder.
Till this point, I assume you have understood the test scenario and also we will be passing the file name to delete the particular file. Also, to verify whether the particular file is getting downloaded or not.
It would help if you imported some packages of python and selenium they have listed below.
To change the download folder path from our local system to the framework folder we need to add some script here, that will set the new download folder as our default folder, to download the files from the webpage.
Step1:
Import the following packages.
from selenium import webdriver
import os
From selenium.webdriver.common.by import By
From webdriver_manager.chrome import ChromeDriverManager
After adding the above imports now we will have to change the path to do so see the script and you will get an idea.
Now we have set the download path to our new folder now we have to set the driver.
Step2:
Here, I have used the web driver manager you can use the chrome driver and provide the path if you want to. But, I suggest using web driver manager, as it is a good practice to use. Because it will download all the updated chrome driver versions automatically and you will save lots of your time.
I hope no one has any problems or doubts till this point, as these steps are crucial and if you have any doubts go through the steps again. Now you can launch your webpage URL.
Step3:
Here, I want you to write your script to locate the web element and click on that element for example refer to the following scrip
After clicking, the file will get downloaded in the new download folder that we have created in our framework.
Step4:
The next step is to see if the file is present in the newly created download folder. In order to achieve this just go through the following script.
def download_file_verify(self,filename):
dir_path = "G:/Python/Download/"
res = os.listdir(dir_path)
try:
name = os.path.isfile("Download/" + res[0])
if res[0].__contains__(filename):
print("file downloaded successfully")
except "file is not downloaded":
name = False
return name
Here, you can provide the name of your downloaded file to the filename argument to avoid the hard coding of the script, as it is not a good practice.
Explanation:
For instance, the name of my downloaded file is extent report so now the value of the filenameargument becomes extent report.
So, first of all, it will go to the directory path we have provided now it will store all the file names already present in the folder in a list format.
Here we have stored that list in the res variable. Now we can iterate over the list and verify if our desired file is present in the folder or not.
Take note here, that the newly downloaded file will always be present in the zeroth index of our download folder. That is why we have used res[0] to check, if the downloaded file is present at the zeroth index or not.
Now, it will check if the zeroth index file name is equal to that of the name of the file we have provided. So, if yes then it will print(“file downloaded successfully”), and if not then it will throw an exception and will print(“file is not downloaded”)
Here I have used assertion to verify whether the file is downloaded or not. I will suggest you use the same as it is good practice. You will get to know the assertion while handling the file.
Congratulations, we are done with the first part. We have successfully downloaded the file in the newly created download folder. We have also verified whether the file is downloaded or not.
Step5:
The next task is to delete the downloaded file by passing the name of the file. So, let’s get started then.
Script to delete the file from the download folder by passing the name of the file.
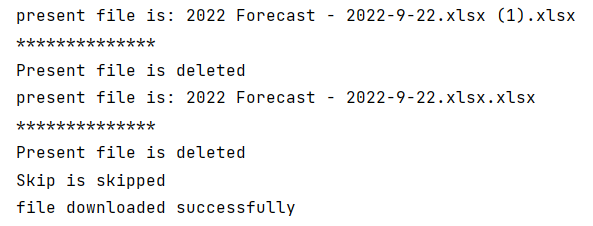
def delete_previous_file(self,filename):
try:
d_path = "G:/Python/Download/"
list = os.listdir(d_path)
for file in list:
print("present file is: " + file)
path = ("Download/" + file)
if file.__contains__(filename):
os.remove(path)
print("Present file is deleted")
except:
pass
Explanation:
Here, we don’t have to only delete the file that is present at the zeroth index. But we have to delete all the files present in the download folder with the same file name. So, that when a new file gets downloaded there will be only one file present.
So the above code will first go to the directory path. Store all the file names present as a list. So, now we have to iterate over that list and see if the same file is present. If yes then we have to delete that file.
Use try and except block. Here, if there is no file present, then our code will not raise any exceptions or will fail.
Congratulations now we have successfully completed the file handling with selenium python.
Output:
If you have any queries comment them down. We will solve that problem together like we just solved one. Also, if you have any suggestions then let me know. I will implement that in our next article. Also, don’t forget to share the article with your friends. Follow our pages on LinkedIn, Instagram, and Facebook. and subscribe to our blog. So, whenever we post some amazing content you will get to know it and, you will not have to wait for it.
In my opinion, validation of file downloading at a particular location is a very easy process. Only, if you have the right solution for reference. In this article, I am sure I have provided the right solution for all your file-downloading problems and validations.