In this blog, we have created the WebdriverIO framework, which will help to run test cases on web applications on different browsers. WebdriverIO is a popular open-source test automation framework for Node.js.Creating a test automation framework using Cucumber, JavaScript, and WebdriverIO offers several benefits that can streamline your testing process and improve the efficiency and maintainability of your automated tests. Here’s why you might want to consider using this combination:
1. BDD Approach with Cucumber:
Cucumber enables Behavior-Driven Development (BDD), allowing you to write test scenarios in a human-readable format.
2. JavaScript Language:
JavaScript is a widely used programming language for web development, making it accessible to many developers.
WebdriverIO is a popular JavaScript-based WebDriver framework that simplifies interactions with browsers and elements on web pages. It also provides a variety of built-in commands for browser automation, making test script development more efficient.WebdriverIO supports multiple testing frameworks, including Mocha and Jasmine, which can be integrated with Cucumber for BDD.
4. Cross-Browser Testing:
With WebdriverIO, you can quickly run your tests across different browsers and browser versions. This ensures that your application functions correctly and consistently across various browser environments.
5. Reusability and Maintainability:
The combination of Cucumber and WebdriverIO promotes the creation of reusable step definitions. Moreover, this modularity makes it easier to maintain test scripts and reduces duplication of code.
6. Parallel Execution:
WebdriverIO supports parallel test execution, which can significantly reduce the overall test execution time.
7. Community and Support:
Both Cucumber and WebdriverIO have active communities, which means you can find a wealth of resources, tutorials, and plugins to enhance your automation efforts.
Let’s see how webdriverIO works and Its process:
Pre-requisites:
1. Make sure you have Node.js installed on your system. You can download and install it from the official website: https://nodejs.org/en/
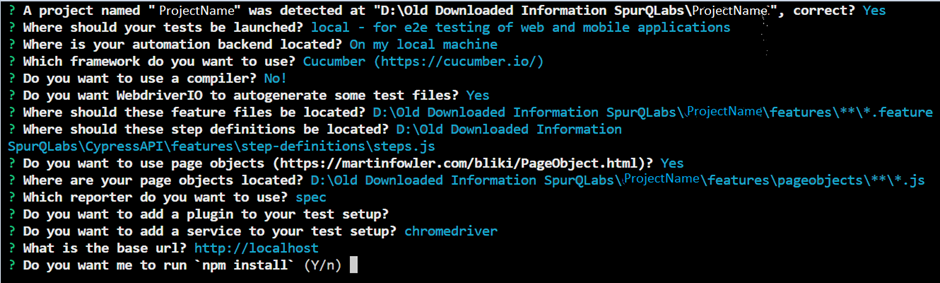
2. Open your terminal or command prompt and create a new directory for your WebdriverIO project or else create a folder wherever you want & open it in VSCode
3. VSCode
Initialize a new npm project by running the following command: “npm init wdio .” This will create WebdriverIO packages and their installation.
Once you execute that command you will get the following message:
“Need to install the following packages:
create-wdio@8.2.3
Ok to proceed? (y)”
If you proceed by pressing “y”, you will receive a list of instructions on how to generate the framework. You can follow these instructions to create the desired WebdriverIO framework.
Once you have completed the framework generation process, it will create a package.json file that will serve as a record of your project’s dependencies. This file will help you manage and keep track of the dependencies required for your project.
“Install WebdriverIO and its CLI tool by running the following command:
“npm install webdriverio @wdio/cli –save-dev”.
This will install WebdriverIO and its CLI tool as dev dependencies and save them in your package.json file.”
Package-json:
package.json is a file used in Node.js projects that contains metadata and configuration information for the project, as well as a list of dependencies and dependencies required for the project to run. It is located in the root directory of the project and is used by package managers such as npm (Node Package Manager) to install and manage dependencies.
Wdio.conf.js:
This file contains the configuration settings that define how the test automation framework runs and interacts with the web application being tested. It has Capabilities, Specs, Framework, Reporter, Hooks, Services, etc.
So here we have selected the “cucumber” framework which will help create test cases in BDD format. Before we go into framework details, you all should know that all WebdriverIO commands are asynchronous and need to be properly handled using async/await.
The Page Object Model (POM) is a popular design pattern used in software testing to represent web pages as objects and simplify the process of automated testing. The POM structure usually includes a “pageobjects” folder, which contains classes or files that represent individual pages on a website or application. These page object classes or files encapsulate the elements and actions related to a specific page, making writing and maintaining automated tests easier. By using the POM, testers can create a more organized and maintainable framework for their test automation efforts.
1) Features
2) Steps
3) Pages
Features:
This folder contains another two folders, i.e., pageobjects, Step-definitions, and features files. The “feature” folder is typically used in the context of behavior-driven development (BDD) frameworks such as Cucumber, which uses a natural language syntax to describe test scenarios. The “feature” folder houses files that define the scenarios or features to be tested.
To create a feature file in VSCode for implementing behavior-driven development (BDD) scenarios using Cucumber, you can follow these steps:
· Open VSCode and navigate to the folder where you want to create the feature file.
· Right-click on the folder, go to “New File”, and click on it to create a new file.
· Give the file a name with the “.feature” extension, for example, “login.feature”
Feature: Checking calculator functionality
Scenario: Verify addition on calculator
Given User is on the calculator page
When User taps on "4"
And User taps on operator
And User taps on "5"
Then User verifies the answer as "9"
Scenario Outline: Verify user can perform multiple operation
Given User is on the calculator page
When User clicks on num1 "<number1>"
The user clicks on the "<operator>"
And User clicks on num2 "<number2>"
Then User verifies "<answer>"
Examples:
| number1 |number2 | operator | answer |
| 4 | 5 | + | 9 |
| 5 | 3 | - | 2 |
| 4 | 5 | * | 20 |
| 6 | 2 | / | 3 |
In the above feature file, I have shown one simple scenario where I have performed a simple addition operation, and in the next scenario, I have created a scenario outline where different operations are performed, including addition, subtraction, multiplication, and division.
Step-definitions:
The “step-definitions” folder contains files or classes that define the behavior or actions associated with each step in the BDD scenario.
In WebDriverIO, you can generate step definitions for the given scenarios in a feature file using a tool called “cucumber-boilerplate”.
Following are the steps to generate steps in WebDriverIO using cucumber:
Install the “cucumber-boilerplate” package as a development dependency by running the following command in your project directory: “npm install cucumber-boilerplate –save-dev”
Once the installation is complete, you can generate the step definitions by running the following command: “npx cucumber-boilerplate generate”
This will prompt you to enter the path to the feature file for which you want to generate the steps.
Provide the path to the feature file (e.g., “./features/login.feature”) and press Enter.
The tool will generate the step definitions in JavaScript format, which you can then copy and paste into your WebDriverIO project’s step definition files.
const { Given, When, Then } = require('@wdio/cucumber-framework');
const addPage = require('../pageobjects/AddPage');
Given(/^User is on calculator page$/, async () => {
await addPage.visitWeb()
});
When(/^User taps on "(\d+)"$/, async (num) => {
await addPage.tapNumber(num)
})
When(/^User taps on operator$/, async () => {
await addPage.tapOperator()
}
Then(/^User verifies answer as "(\d+)"$/, async (ans) => {
await addPage.getAns(ans)
})
When(/^User clicks on num1 "([^"]*)"$/, async (num1) => {
await addPage.clickNum1(num1)
})
When(/^User clicks on num2 "([^"]*)"$/, async (num2) => {
await addPage.clickNum2(num2)
})
When(/^User clicks on the "([^"]*)"$/, async(opt) =>{
await addPage.clickOperator(opt)
})
Then(/^User verifies "([^"]*)"$/, async(ans) =>{
await addPage.verifyAnswer(ans);
})
In the above code, you can see we have integrated steps for each line of the feature file, so we can run code in BDD format.
Page objects:
These are classes that represent a web page, containing methods and properties that interact with the page’s elements, such as buttons, links, and input fields.
const { config } = require("../../wdio.conf");
const assert = require('assert');
const addPageLoc = require("../../Locators/AddPageLocators")
const scr = require('../pageobjects/ScreenshotPage')
class AddPage{
constructor(){
this.plusOpt = addPageLoc.plusOpt;
this.answer = addPageLoc.answer;
}
// Since we parameterized the value for the locator, we kept it as is.
getNumber(num){
return $('[onclick="r('+num+')"]')
}
async tapNumber(num){
await this.getNumber(num).click();
scr.takeScreenshot('tapping_number');
}
async tapOperator(){
await this.plusOpt.click()
await browser.pause(3000);
scr.takeScreenshot('tapping_operator');
}
async getAns(){
let txt = await this.answer.getText()
console.log("Answer of addition: " +txt);
scr.takeScreenshot('gettingTextOfElement');
}
async visitWeb(){
await browser.url(config.baseUrl)
scr.takeScreenshot('webUrl');
}
async clickNum1(num1){
await this.getNumber(num1).click();
scr.takeScreenshot('clicking_number1');
}
async clickNum2(num2){
await this.getNumber(num2).click();
scr.takeScreenshot('clicking_number2');
}
async clickOperator(opt){
await $('[onclick="r(\''+opt+'\')"]').click();
// await this.operator.replace('XXX', opt).click();
scr.takeScreenshot('clicking_operator');
}
async verifyAnswer(ans){
let result = await this.answer.getText()
console.log("Retrieving text value from element: " +result)
assert.equal(result,parseInt(ans));
scr.takeScreenshot('verifyingResult');
}
}
module.exports = new AddPage();
The browser.pause() method was used to pause it for the specified amount of time. It takes time in milliseconds.
Also, we added methods to the “AddPage” class, such as click() and setValue(), that are necessary to perform operations on web elements. Also, the setValue() method has been used for sending values for web elements.
Locators: This folder includes all the locators required to operate web elements
In the above code, we listed out all the locators in one file and then imported them into pages, removing clumsiness from the code
Now that we have completed implementing the Page Object Model (POM) design pattern, we can consider incorporating additional functionalities to further enhance the framework’s suitability and reliability.
Screenshots:
To add screenshot functionality to your code, you need to incorporate the following code into your implementation:
class ScreenshotPage{
takeScreenshot(filename) {
const timestamp = new Date().getTime();
const filepath = `./screenshots/${filename}_${timestamp}.png`;
browser.saveScreenshot(filepath);
}
}
module.exports = new ScreenshotPage();
Import this code into the page where you need to capture a screenshot by calling takeScreenshot(‘nameOfScreenshot’).
The above image displays the screenshots it took. The sequence of screenshots offers an overview of the test case, illustrating actions taken at each step.
Cross-Browser Testing:
Cross-browser testing is a practice in software testing that involves testing a web application or website across multiple web browsers and browser versions to ensure its consistent functionality and appearance across different browser environments.
Capabilities:
In the wdio.conf.js file, make changes similar to what I have done in the ‘capabilities’ section. I have attached the following code for your reference. You can use it for assistance and make changes accordingly.
In the ‘services’ section of the wdio.conf.js file, make changes similar to what I did in the following code snippets. You can make changes accordingly and run your test cases smoothly.
The above code will assist you in implementing different browsers for testing, and you can also add others like Microsoft Edge, Safari, etc.
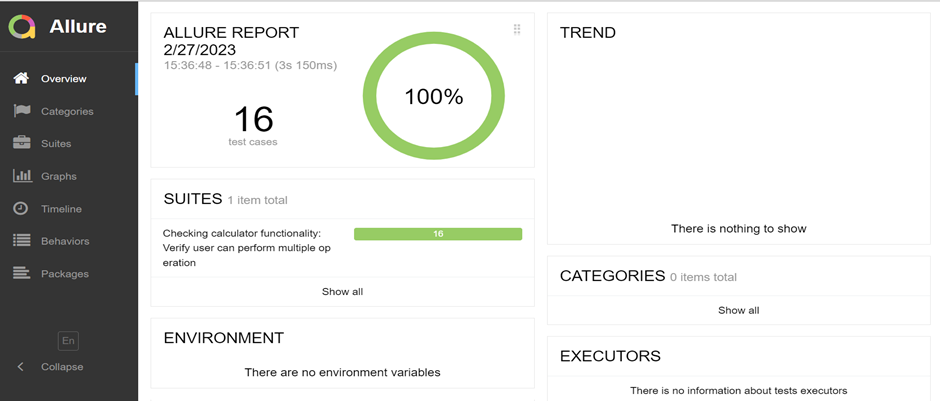
Allure_Report:
Allure Reports are often preferred over Cucumber Reports due to their visually appealing visualizations, comprehensive insights, step-by-step details, time tracking, integration capabilities, and historical trend analysis.
Once you have completed the automation process, testers need to generate reports to track the status of test cases, including pass or fail results and the exact location of failures. You can use the Allure report functionality for this purpose in your WebDriverIO project Follow these steps to include the Allure report:
1. Install the Allure Reporter plugin for WebDriverIO using the following command: “npm install @wdio/allure-reporter –save-dev”
2. Add the Allure Reporter plugin to your wdio.conf.js file as a reporter. Following is an example configuration:
In this example, we’re using the spec reporter for console output and the allure reporter for generating the allure report. The outputDir option specifies the directory where it will generate the report files.
1. Add the Allure command line tool to your project by running the following command: “npm install allure-commandline –save-dev”
2. After running your tests, generate the Allure report by running the following command: “npx allure generate allure-results –clean”
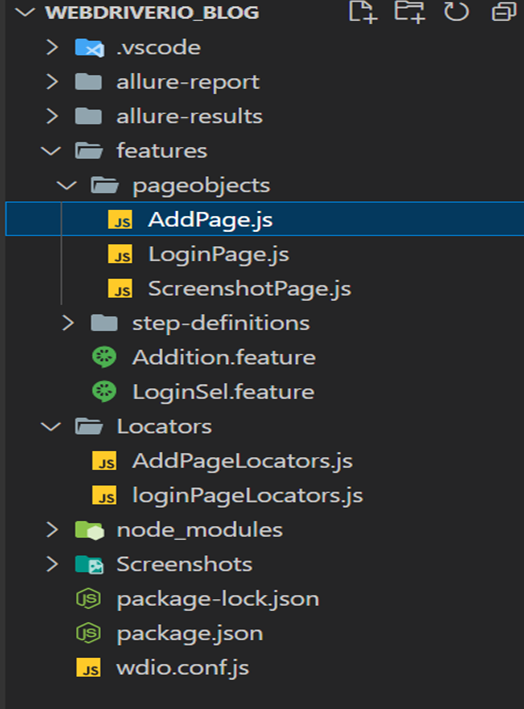
Project Folder Structure:
As we have completed the design of the folder structure for the framework, you can now see below the image of what the framework’s folder structure looks like.
The image above shows the integration of different folders in the WebdriverIO framework. I have provided explanations for each folder and its contents.
To run test cases on a browser, you can use the following commands:
· npx wdio wdio.conf.js
· npx wdio run wdio.conf.js –spec features\Addition.feature // To run a specific feature file
· npx wdio wdio.conf.js –spec ./path/to/your/test.js –browser chrome // To run on a specific browser”
Note: Please make sure to replace the path and file names with the appropriate ones for your specific setup
Conclusion:
WebdriverIO is a comprehensive and feature-rich framework that empowers developers and testers to create reliable and efficient automation tests for web applications. It is a vast ecosystem of plugins, extensive documentation, and also active community support make it a top choice for automation testing in the modern web development landscape. By adopting WebdriverIO, organizations can significantly improve their web application testing efforts and deliver high-quality software to their end-users.
Harish is an SDET with expertise in API, web, and mobile testing. He has worked on multiple Web and mobile automation tools including Cypress with JavaScript, Appium, and Selenium with Python and Java. He is very keen to learn new Technologies and Tools for test automation. His latest stint was in TestProject.io. He loves to read books when he has spare time.
At times, certain project specifications demand comprehensive testing of a web application across a diverse range of web browsers and their varying versions. Maintaining consistent functionality, visual appearance, and user engagement is essential.
To execute this type of cross-browser testing efficiently, there are two primary approaches:
One involves manual testing, where the website is examined across multiple browsers and devices.
The other approach entails leveraging specialized tools and services that replicate distinct browser environments.
Particularly, BrowserStack stands out as a tool that has garnered considerable attention in this field, thanks to its intuitive user interface.
Executing test cases on BrowserStack is crucial for QA teams to ensure the compatibility, functionality, and performance of websites and applications across a wide range of real browsers and devices.
It helps identify bugs, responsive design issues, and user experience problems, while also supporting automated testing and real environment testing.
BrowserStack eliminates the need for local testing infrastructure, reducing costs and enhancing overall testing efficiency.
So first let’s talk about the Basic Framework where we can automate test cases using the BDD approach to execute tests on a browser on the local machine.
So for this instead of explaining it from scratch here again, You can explore my blog where I have explained How to create a BDD automation framework using Cucumber in JavaScript and Playwright.
This blog gives you step-by-step guidance on how to Create Feature files, Steps files, Page Files, and various other utilities to make the framework more reusable and robust. So here is the link to this blog: https://shorturl.at/bjuvU
You must have a BrowserStack account to execute your tests, to create a new BrowserStack account you can visit the below link. https://www.browserstack.com/users/sign_up
To get started with BrowserStack implementation first store your BrowserStack username and access key in the .env file. To get the username and access key to navigate to your BrowserStack account. Click on Access key dropdown from dashboard and you will be able to see your username and access key.
Here you will be able to see your account details. Copy your Username and Access Key and store it in a .env file as shown below. To execute tests on BrowserStack set the Browserstack variable to ‘true’.
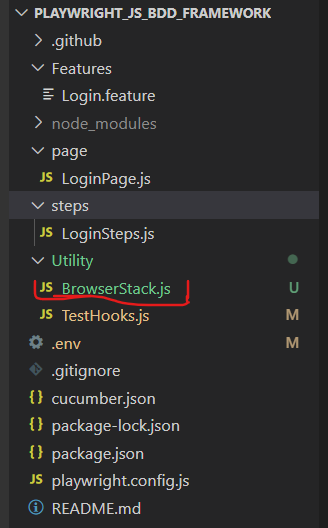
Now to set BrowserStack configurations Create a file as “Browserstack.js”, as you can see I have created a “Browserstack.js file” in the Utility folder.
Here are the essential BrowserStack configurations to integrate into this file.
The playwrightClientVersion variable is declared and assigned the output of the shell command executed using execSync from the child_process module.
.execSync('npx playwright --version’):
The command executed is npx playwright –version, which retrieves the version of the Playwright framework installed on the system. The output is converted to a string, trimmed to remove leading or trailing whitespace, and then split into an array based on spaces. The second element of the array (split(‘ ‘)[1]) represents the Playwright’s version.
caps():
This function is responsible for generating a configuration object used for browser testing with the BrowserStack platform and Playwright framework. It returns an object that contains configuration options for browser testing like browser, os, os_version, etc.
These are the variables from the .env file. If you are not using a .env file you can directly pass the BrowserStack username and access key.
As we have all the configurations ready, we will set up a test environment to execute tests on BrowserStack. Use the file where you have your Before and After methods. In the playwright-Js Framework we have these methods stored in the ‘TestHooks.js file’ so will update that file as below.
The above code Generates capabilities for BrowserStack using the caps() function from the ‘BrowserStack’ module. Construct the WebSocket endpoint URL for BrowserStack with the generated capabilities.
Now we have completed the BrowserStack implementation in our framework, now you can execute your tests on BrowserStack.
To execute tests on BrowserStack make sure you have “Browserstack = true” in the .env file.
Then you can execute your tests using the command ’npm run test’ on your terminal.
After running the test cases on BrowserStack, you’ll find the report below. Access comprehensive execution videos, and test logs for both successful and unsuccessful cases, along with execution duration.
Conclusion:
Integrating BrowserStack with Playwright JavaScript tests, gives access to a wide range of real browsers and devices, enabling comprehensive cross-browser and cross-platform testing. The scalability and cost-effectiveness of BrowserStack eliminate the need for maintaining an extensive device lab. Ultimately, this integration enhances test coverage, improves software quality, and ensures a seamless user experience across various browsers and platforms.
Priyanka is an SDET with 2.5+ years of hands-on experience in Manual, Automation, and API testing. The technologies she has worked on include Selenium, Playwright, Cucumber, Appium, Postman, SQL, GitHub, and Java. Also, she is interested in Blog writing and learning new technologies.
Agile methodologies are nothing but an approach or practice that applies in Software development and Project management which makes the development process more efficient and helps to maintain the quality of software. It mainly focuses on collaboration, flexibility, and adaptability in the testing process. During development, the software testing practices adhere to the agile methodology.
There are several project management tools such as Kanban, Jira, Scrum, or Extreme Programming (XP).
The core process involved in Agile development:
Define Requirements:
The product owner or analyst along with the development team collaborates with each other and identifies, analyzes, and defines the requirements. User stories are created for specific sprints to define the requirements. And these user stories are collected in the product backlog or product board.
Sprint Planning:
Sprint planning is a process in which a product goal gets defined and a plan for the upcoming sprint is defined. Developers from the development team pick a set of requirements from the product board to work on the upcoming sprint. A Sprint meeting happens and the team identifies the scope of the upcoming sprint and breaks down the requirements into tasks.
Sprint Execution:
In Sprint Execution, the development team starts working on user stories in a time-bound iteration called a Sprint. Daily scrum call meetings are conducted to discuss progress, work, and any impediments during the sprint.
Continuously Integration:
Continuously Integration is a process, where developers make changes in code and those changes are also merged in a remote repository (GitHub) and tested frequently. It automates stages of the project pipeline such as – build, test, and deployment. It helps to team working within agile development.
Agile Testing:
Testing activity occurs in the early phase of the development process. In this phase, the tester collaborates with the developer and PO to understand the requirement and also starts testing the module, and defines the acceptance criteria. Testers start preparing test scenarios and test cases based on user stories. And they execute test cases and report bugs using bug-reporting tools such as Jira.
Incremental Delivery:
In the incremental Delivery phase, a small, developed part of the software is delivered to the customer at the end of each sprint. It helps to improve the quality of software by delivering it in small parts.
Sprint Review:
The Dev team, Pos, and QAs are involved in the Sprint Review meeting. In this phase, Sprint review takes place. Here development team presents work accomplished or gives a demo of whatever they have developed in that sprint. The incomplete issues, backlog adjustments, and Action items are discussed in this meeting.
Sprint Retrospective:
The agenda of this meeting is to examine how Sprint went as far as people, requirements, relationships, processes, and tools.
Discussions Include:
What did we do well?
What should we have done better?
Identifies area for improvement
Suggestions
Actions
Let’s talk about Automated Testing:
Automated testing is an Agile practice that allows you to automate test cases through automation tools and execute the test cases to verify the functionality of software applications to meet customer expectations. It is a key aspect of agile development. Automated testing emphasizes manual testing efforts and also provides a way for continuous testing, early bug detection, and quick feedback.
Important aspects of Automated Testing:
Test Automation Framework: The team creates an automation framework using specific technology as per requirement and maintains it. It is a structured set of a rule and resources and tools which helps to create, execute, and automated the test cases. It allows us to reuse the code, in test data and also provides a way to generate test results or reports for execution.
Continuous Integration: The automation tool makes continuous integration easier when developers make changes in code and those changes are merged in a remote repository (GitHub) and tested frequently. Automated testing is an integral part of this process.
Regression Testing: Automated testing plays a vital role in regression testing. It makes sure that there should not be any unintended side effects occurring in the module when new changes have been made. Automation regression tests can be executed fast and repeatedly, giving quick feedback.
Continuous Delivery and Deployment: Automated testing allows us to run test suites to ensure that the changes made meet functional expectations and maintain the effectiveness and quality of the product. After completion of the automated testing phase, there is a Continuous Delivery process in which changes are automatically continuously deployed to the staging environment for testing. With this process code, the changes are continuously updated with the latest changes which makes faster delivery of the product in an efficient way.
Benefits of Automated Testing in Agile Methodologies:
Faster Feedback: Automated testing provides feedback quickly. It also helps in executing tests, generating results, and finding issues very quickly in the development cycle.
Increased Coverage: Automated testing allows you to create a wider range of test scenarios and test cases compared to manual tests.
Consistency-It helps to keep consistency in the execution of test cases, reducing human errors. Automated code itself needs to be tested to makes sure consistency and high quality.
Time and Cost Efficiency: Automated testing reduces human efforts and it is used in repetitive tasks, so it saves time and resources in the long run.
The working of CI/CD for automation testing in Agile:
CI/CD stands for Continuous Integration and Continuous Delivery as it is a pipeline that helps development teams to automate and makes it more efficient for building code, running tests, and also safely deploying code. The goal of the CI/CD method is to deploy code frequently and deliver working software to customers frequently and quickly.
Usually, Our source code is located on our local workstations. From there, we will commit our source code to the version control system, specifically using Git, which serves as our code management system, and is hosted on GitHub. Once the code is available in the code management system, the CI tool pulls that code automatically and builds under run unit test and then we call it Continuous integration.
During the CI process, we build and compile our source code and generate artifacts. Once these artifacts are generated, we need to deploy them on target env.
Target env may be changed based on the project necessities it may be a staging test, Dev or QA, preview, or production like various env we might have.
Now let’s take the artifacts we want to deploy on a staging environment.
Once it is deployed in the staging env we do the regression test and performance test. Once it successfully passes this test, it can be deployed to the production environment. During the deployment process, after the build, we move it into the staging environment, and if this transition to production can be achieved seamlessly without any manual intervention, we refer to it as Continuous Deployment.
In Continuous deployment, we can automatically deploy into the staging env and production environment.
Benefits of CI/CD:
Helps you to build better-quality software.
Automate the software release process for making delivery more efficient, rapid, and secure as well.
It helps you to automate repetitive tasks.
It reduces risks and makes the deployment process more predictable.
You can release software more frequently, which helps you to get fast feedback from your clients.
It gives a single view across all environments and applications.
What is Test Automation?
Test automation or automation testing is a process of automating test cases using automation tools and frameworks, managing test data, and asserting the automated result with requirements without any manual intervention. Automation testing plays an important role in achieving goals such as faster delivery, continuous integration, and frequent releases.
Benefits of Test Automation in Agile:
Faster Feedback: Automated tests can be executed quickly and also provide faster feedback on tests.
Improved Test Coverage: Automation tests allow running a large number of test cases across different environments hence it can cover different scenarios in the application.
Regression Testing Efficiency: Automation testing is mainly useful for running regression tests so it helps in repetitive testing after each code change.
Consistency and Accuracy: As automation testing is done without human intervention, it eliminates the possibility of human errors during test execution.
Benefits of Deployment Automation:
Deployment automation offers numerous benefits for software development, IT operations teams, and the entire organization. Automated deployment is a best practice in agile. Moreover, it allows developers to automate the deployment activities, development process, and testing activities. The following are the key benefits of deployment automation:
Faster and More Efficient Deployment: Automated deployment process is faster than manual deployment as it provides quick feedback. So that it reduces the time takes to release the software updates.
Consistency: Deployment automation ensures the consistency of the deployment across different environments (staging, dev, preview, production). So that it reduces the risk of configuration errors.
Reduce Human Errors: As Manual deployment involves humans which can lead to deployment errors, data loss, or other issues. So here, automation reduces such errors and increases the reliability of the deployment process.
Efficient Testing Environment: Automated deployment allows quick provisioning and teardown of the testing environment. This enables development and testing teams to work in isolation and concurrently, leading to faster testing cycles.
Cost Savings and Resource Optimization: Automated deployment reduces manual intervention which can lead to saving costs and resources.
Conclusion:
In conclusion, automated testing is an essential part of the dynamic landscape of the agile world. As we’ve explored this blog, it provides faster feedback, consistency, and accuracy, reducing risk and ensuring to delivery of high-quality software. Automation plays an important role in the form of CI/CD that helps you to build better-quality software.
Poonam is a dedicated Automation and Manual Testing professional with 2 years of experience, She is well-versed in the latest testing methodologies and tools. She has a solid foundation in programming languages such as Java, Ruby and JavaScript, and extensive experience working with automation tools such as Selenium, TestNG and Playwright, Capybara. She hold an MCS degree from Pune University, where She gained a solid foundation in computer science and programming.
Hello! In this blog, We will be exploring how to automate tests using selenium with Cucumber in Ruby.
What is Selenium?
How does the selenium web driver in Ruby work?
How to use selenium with ruby?
Ruby is a scripting language designed by Yukihiro Matsumoto, also known as Matz. It runs on a variety of platforms, such as Windows, Mac OS, and various versions of UNIX. Ruby is a pure object-oriented programming language.
Advantages of Ruby:
Open source and community support.
Flexibility.
Suitable for beginners.
Supports Web development and Desktop Applications.
Ruby is a general-purpose, interpreted programming language.
Ruby also provides a great number of helpful tools and libraries.
Ruby has a clean and easy syntax that allows a new developer to learn very quickly and easily.
What is Selenium:
Selenium is an open-source tool that automates web browsers. Selenium and Ruby can be used together, by using a gem called selenium-web driver. With this gem, you can easily automate your test cases. Selenium is a powerful tool as it supports major web browsers and supports almost all OS platforms- Windows, Linux, and Mac. You can explore selenium more on
Selenium WebDriver is a Gem that wraps the WebDriver server and makes it easier to drive a browser. WebDriver is a program that can control a web browser.
Installing selenium-web driver via gem: simply run this command on the terminal.
“gem install selenium-webdriver”
What is Ruby Gem:
Ruby gems are simply open-source libraries that contain Ruby code and are packaged with a little extra data. Using a gem allows a programmer to use the code within the gem in their program, without explicitly inserting that code.
Gems can be used for all sorts of purposes, and you can explore different gems at https://rubygems.org/. To get a better idea of what gems can do, here are a couple of popular gems and their functionality:
Bundler— Provides a consistent environment for Ruby projects by tracking and installing the needed gems and versions. It is the #1 downloaded gem of all time, but more on Bundler later.
RSpec — A testing framework that supports Behavior Driven Development for Ruby.
Devise— Devise works with authentication. For any website that needs to user login, Devise handles sign-in, sign-up, reset password, etc.
JSON — Provides an API for parsing JSON from text.
Installing Gems:
Installing gems locally is as simple as a single command: gem install [gem_name]. The install command fetches the code, downloads it to your computer, and installs the gem and any necessary dependencies. Finally, it will build documentation for the installed gems.
How to use selenium with Ruby:
In Ruby, you can create an instance of the WebDriver class by either instantiating an object or by starting a session. The instantiated object returns a session object of the WebDriver.
To instantiate a driver with the session object, we would need to do the following:
After installing ruby we need to install a few gems to start:
• gem install selenium-webdriver
• gem install selenium-cucumber
Download IDE for writing the code
• IDE : Intellij Idea Ultimate-2022.1.2
Steps to create files:
Create Project: File-New-Project
Create feature File: Right Click on project folder(Calculator)-New-Directory-features(name of folder)-Calculator.feature(File)
Create Step Definition File: Right Click on features(folder)-New-Directory-step_definitions(name of folder)-CalculatorSteps.rb(File)
Create Page File- Right Click on features(folder)-New-Directory-CalculatorPage(Folder)-Calculator.rb(File)
What is Feature File:
Feature Files are used to write acceptance steps during automated testing. A Feature File is a common file containing the feature description, scenarios, and steps for testing a feature. It serves as an entry point to the Cucumber tests. It is the file where your test scenarios are written in the Gherkin language. These files have a “.feature” extension, and users should create a separate Feature File for each software functionality.
A simple feature file consists of the following keywords/parts:
Feature − Name of the feature under test.
Description (optional) − Describe the feature under test.
Scenario − What is the test scenario?
Given − Prerequisite before the test steps get executed.
When − Specific condition which should match in order to execute the next step.
Then − What should happen if the condition mentioned in WHEN is satisfied?
We will create a project first, so click on File and choose “new project” from the menu that appears.
After creating the project we will create a feature file, so right-click on the project name and create a folder- feature and then create the file name as “Calculator. feature”.
Here is the code snippet for the feature file:]
Feature: Calculator
Scenario: Addition of two numbers
Given I launch calculator application
When I click on number 4
And I click on operator +
And I click on second number 5
Then I verify the result is 9
Now here all the steps are undefined, so we need to add a step definition file, so right click on the features folder and create a folder named “step_definitions” and in this folder create a file name “CalculatorSteps.rb”
What is Step Definition File:
The steps definition file stores the mapping between each step of the scenario defined in the feature file with a code of the function to be executed. So, now when Cucumber executes a step of the scenario mentioned in the feature file, it scans the step definition file and figures out which function is to be called. So for each step mentioned in the feature file (GIVEN, WHEN, THEN) which you want to execute you can write code within the step definition file.
Given(/^I launch calculator application$/) do
@Homepage = Homepage.new(@driver)
@Homepage.visit
end
When(/^I click on number (.*)$/) do |num1|
@Homepage.getnum1(num1);
end
And(/^I click on operator (.*)$/) do |oprt|
@Homepage.getoperator(oprt);
end
And(/^I click on second number (.*)$/) do |num2|
@Homepage.getnum2(num2);
sleep 2
end
Then(/^I verify the result is (.*)$/) do |result|
expected_result=@Homepage.verify_result()
expect(expected_result).to eq(result)
puts(result)
puts(expected_result)
puts "result match successfully"
end
However, this is not the complete job done.
Now if you hover over a method it shows cannot find method_name, so we need to create a method for every action, so right click on the features folder and create a folder name as “CalculatorPage” and in that folder create “Calculator. rb”
Here is the code snippet for the page file where we can have all methods:
require 'selenium-webdriver'
class Homepage
def initialize(browser)
@driver= Selenium::WebDriver.for :chrome
@driver.manage.window.maximize
end
def visit
@driver.get "https://www.calculator.net/"
puts "launch application successfully"
end
def getnum1(num1)
@driver.find_element(:xpath,"//span[@onclick='r(#{num1})']").click
end
def getoperator(oprt)
@driver.find_element(:xpath,"(//span[contains(text(),'#{oprt}')])[1]").click
end
def getnum2(num2)
@driver.find_element(:xpath,"//span[@onclick='r(#{num2})']").click
end
def verify_result()
@driver.find_element(:id,'sciOutPut').text.lstrip()
end
end
What is Page File:
In the above code snippet, methods contain actions like opening the browser, visiting a website, CSS selectors, Xpaths, and actions to be performed on it (click), and verifying. Simply page file is where you write all the code in detail, all the actions you want to execute in the step definition file. By creating methods you can avoid messy code and can show only necessary things in the step definition file.
To run the feature file we need to configure the project so,
Here is the snippet for configurations:
Go to Run on the top bar and click on plus icon select cucumber and then add the following details for configurations:
After completing the configuration now run the feature file with the command on the IntelliJ terminal:
Before running this command make sure you are at the correct feature file path so here you need to move to the Calculator folder.
• cucumber features/Calculator.feature
here is the snippet of output:
Here is the cucumber report: you can get this report by running the command on the IntelliJ terminal-
cucumber features –format HTML –out reports
Conclusion:
Like Java and Python, Ruby is a general-purpose programming language. however, it focuses on simplicity, precision, and productivity. Ruby being an array-based language, is very powerful for specific uses and works particularly well with ordered datasets.
Pranali has over 1.10+ years of experience in QA, with a strong foundation in both manual and automation testing. I’m a versatile engineer skilled in Selenium, TestNG, Cucumber, Java, Ruby, POSTMAN, SitePrism, Capybara, Jira, SQL, and GitHub.
Starting from September 30th, 2023, Selenium will no longer provide support for Java 8. Instead, the minimum supported version of Java will be Java 11. For the official announcement from Selenium, please refer to this link:
Selenium has supported Java for a long period. Java 8 reached the end of active support about a year ago as you can see below the details of version support.
The default of Selenium has not had a major release in several years and also a bug has been found that cannot be fixed. So the decision was made to move to the native Java HTTP client which requires using Java 11 or greater version. So instead of upgrading to the latest Java for now Java 11 will be a cautious step to move forward. In this blog, we will explore how to achieve that with minimal changes.
Download and Install Java 11:
First, you need to download the exe file for the JDK 11 version. For that, you can visit the link provided below: https://www.oracle.com/in/java/technologies/javase/jdk11-archive-downloads.html You can get it by signing in to the Oracle which is free. You will have various file types to download. For the exe file, you can refer below image.
After completing the download you proceed with the installation process.
For the installation, you can follow the below steps shown in screenshots. Then the installation process will be completed.
After completing the installation of Java 11.
You will find the file below in your system at the following path: C:\Program Files\Java.
So now you have successfully installed Java 11.
Setting Up Environment variable:
The next step is to set up the environment variable. To do that, simply navigate to the Environment Variable.
Settings > About > Advance System Settings > Environment Variables
As you can see in the image above, I have successfully updated the JAVA_HOME path with the latest JDK version. Additionally, don’t forget to update the path variable with the latest “bin” folder.
So now start your command prompt by executing the java -version command. You will get to see the latest updated version of Java.
We have now installed Java 11 and configured the Environment Variables.
Update Existing project on the latest installed Java version which is Java 11:
So for now we’ll see how we can update the existing Java 8 project to Java 11
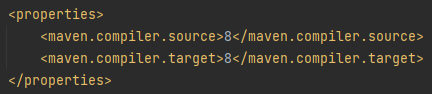
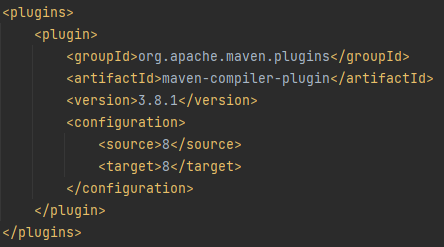
So you must have a pom.xml file present in your existing project framework.
Before:
After:
As you can see the source and target in the above snapshots are version 8. Here you can update the version of the java with latest 11 as we have downloaded and installed Java 11. So after updating the 8 with 11, you have to rebuild the pom.xml project as well. After that, you will see the successfully updated Java version to 11. This is how you need to update your Java version to 11.
Swapnil is an SDET with 1+ years of hands-on experience in Manual, Automation, and API testing. The technologies I have worked on include Selenium, Playwright, Cucumber, Appium, Postman, SQL, GitHub, Java, and Python. Also, I love Blog writing and learning new technologies.
Faster App Deployment: Manual testing can be time-consuming and resource-intensive when it comes to identifying bugs in code. Mobile automation testing reduces the time and effort required by using automation tools. These tools enable quick checks to ensure the code performs as desired, leading to a faster feedback loop and accelerated app deployment.
Improved Efficiency: With automated testing, there is no need for human intervention. Tests can be scheduled to run overnight, and results can be collected the next morning. By automating the testing process, app developers and QA teams can spend less time on testing and focus more on other critical tasks. This boosts overall productivity and efficiency.
Precision in Testing: Mobile automation testing is more reliable than manual testing, which is prone to human errors. Automated tests produce precise and consistent results, reducing the likelihood of bugs. Test cases generated by automated systems enhance reliability and minimize the probability of errors when launching the app.
Real-time Feedback: Automated testing provides instant feedback. Tests run quickly, and test reports are generated immediately. This enables developers to promptly address any malfunctions or issues detected during the testing process. Real-time feedback helps in identifying and resolving problems swiftly, ensuring app quality.
Cost Savings: Contrary to common misconception, automated testing is more cost-effective than manual testing. Manual testing can be repetitive and monotonous, leading to increased chances of human error. Automation increases testing speed and accuracy, reducing the need for extensive manual intervention. Once the automated testing scripts are developed, they can be reused 24/7 without incurring additional costs.
What is WebDriver.io?
WebdriverIO is an open-source testing automation framework written in JavaScript and running on NodeJS. Next-gen browser and mobile automation test framework for Node.js
Why Webdriver.IO?
WebdriverIO is a progressive automation framework built to automate modern web and mobile applications. It simplifies the interaction with your app and provides a set of plugins that help you create a scalable, robust, and stable test suite.
Features of WebDriver.io:
Easy to Set up: WebdriverIO follows a simple setup process. Just install node packages using npm and start testing
Customization: WebdriverIO is highly extendable so users can customize the framework as they need
Cross-Browser Testing: WebdriverIO supports multiple browsers such as Chrome, Edge, Firefox, Internet Explorer, and Safari.
Native Mobile Application Testing: WebdriverIO framework can be extended to test native mobile applications.
Multiple Tab/Window Support: WebdriverIO Supports switching to and from various windows and tabs.
iFrame Support: WebdriverIO doesn’t restrict in terms of iFrame. Testers can automate iframe-based scenarios using simple web driver commands.
Reporters: WebdriverIO supports more than dozens of reporters.
Testing Framework/Assertions: WebdriverIO supports Mocha, Jasmine, and Cucumber test frameworks.
Parallel Testing: Testers can configure WebdriverIO to launch multiple instances and execute tests parallelly.
Screenshots: WebdriverIO can be configured to take screenshots for tests.
Video: Though WebdriverIO doesn’t support video recording out of the box it can be configured to do so.
Pipeline Integration: WebdriverIO tests can be integrated into CI Systems like Jenkins, Azure, etc.
Selectors: It supports various types of selectors including CSS and Xpath.
Page Object Pattern: WebdriverIO Framework can be easily configured to Page Object Model.
File Upload and Download: WebdriverIO supports File Upload and Download features.
Mobile Automation with WebDriver.io: This enables code usage between iOS, Android, and Windows test suites. It runs on iOS and Android applications using the WebDriver protocol.
Requirement For Mobile Automation using webdriver.io:
Pre-Setup
Installation & Configuration
Install the latest stable version of Android Studio from https://developer.android.com/studio
Then Install android-platform-tools from CLI
Install JDK’s latest stable version from here https://www.oracle.com/java/technologies/javase-jdk16-downloads.html
Download the latest stable version of VS Code from https://code.visualstudio.com/download
Install the latest version of Allure for Report Generation from https://docs.qameta.io/allure/
Download and install the latest LTS Node.js – https://nodejs.org/en/download
Install Following Dependencies
Commands to install the dependencies
npm i @wdio/allure-reporter
npm i @wdio/appium-service
npm i @wdio/browserstack-service
npm i @wdio/cli
npm i @wdio/cucumber-framework
npm i @wdio/local-runner
npm i @wdio/mocha-framework
npm i chromedriver
npm i wdio-chromedriver-service
npm i ts-node
npm i webdriverio
npm i allure-commandline
npm i appium
In WebDriver.io, the config file (wdio.conf.js) is a crucial component used for configuring and customizing the test execution environment. It allows you to define various settings, options, and capabilities for your WebDriver.io tests. The config file acts as a central configuration hub for your test suites and provides flexibility in managing different test environments and setups.
Here are some common uses of the config file in WebDriver.io:
Specifying Test Framework and Reporter:
You can define the test framework (e.g., Mocha, Jasmine) and the reporter (e.g., Spec, Dot, Allure) for your test runs. This ensures that the tests are executed using the desired framework and provides appropriate reporting formats.
Defining Test Files and Suites:
You can specify the test files or directories containing the test files to be executed during a test run. Additionally, you can define test suites, which allow you to group related tests together for organized execution.
Configuring Test Environments:
The config file allows you to configure different test environments (e.g., local, remote, cloud-based) and set the desired capabilities for each environment. This includes specifying the browser or device to be used, browser version, operating system, and other relevant configurations.
Managing Selenium Grid and WebDriver Services:
If you’re using a Selenium Grid or WebDriver service, the config file lets you configure the connection details and capabilities for these services. You can specify the host, port, and other relevant configurations for connecting to the grid or service.
Defining Hooks and Lifecycle Events:
WebDriver.io provides hooks and lifecycle events that allow you to execute code at specific points during the test execution cycle. The config file lets you define these hooks, such as before and after hooks, to perform setup and teardown actions or customize test behavior.
Setting Timeout and Retry Options:
You can configure timeout values for various actions, such as test execution, page loading, and element interactions. Additionally, you can define retry options, which specify the number of times a test should be retried in case of failures.
Integrating with Test Services and Frameworks:
WebDriver.io supports integration with various test services and frameworks, such as Appium, Sauce Labs, and Cucumber. The config file allows you to set up and configure these integrations, enabling seamless usage and interaction with these services.
By utilizing the config file effectively, you can streamline and tailor your WebDriver.io test runs according to your specific requirements. It provides a flexible and centralized approach to managing test configurations, environments, and other essential aspects of your test automation setup.
Prerequisites for the Android Studio:
To use Android Studio, you will need to ensure that your system meets the following prerequisites:
Operating System:
Android Studio is compatible with Windows, macOS, and Linux operating systems. Make sure you have a supported version of the operating system installed on your computer.
Java Development Kit (JDK):
Android Studio requires a compatible version of the JDK to be installed. It is recommended to use the latest stable version of JDK. Currently, Android Studio supports JDK 8 or higher. You can download the JDK from the Oracle website or use OpenJDK.
System Requirements:
Android Studio has certain hardware requirements to function optimally. The exact specifications may vary depending on the version and updates of Android Studio, but generally, you should have:
Android SDK:
Android Studio requires the Android SDK (Software Development Kit) to develop and test Android applications. The SDK provides libraries, APIs, and tools necessary for app development. Android Studio includes a bundled version of the Android SDK, which you can install during the Android Studio installation process. Alternatively, you can download the SDK separately and configure Android Studio to use it.
Emulator Requirements:
If you plan to test your apps on emulated devices, your system should meet the requirements for running the Android Emulator. This includes having an Intel or AMD processor with virtualization extensions enabled in the BIOS settings.
Internet Connection:
An internet connection is required during the installation and setup process of Android Studio. It is necessary to download additional components, SDK packages, and updates. It’s important to note that the specific requirements and recommendations may change with different versions of Android Studio. It’s always a good practice to refer to the official documentation and system requirements provided by Google for the most up-to-date information before installing Android Studio.
What is use tsconfig.json:
The tsconfig.json file is used in TypeScript projects to configure the TypeScript compiler (tsc) and specify the compilation settings for your TypeScript code. It provides a way to customize the behavior of the TypeScript compiler and control how your TypeScript files are transpiled into JavaScript.
key uses and features of the tsconfig.json file:
Compiler Options:
The tsconfig.json file allows you to define various compiler options to specify how the TypeScript compiler should handle your code. These options include target ECMAScript version, module system (e.g., CommonJS, ES modules), output directory, source map generation, strictness level, and more. You can tailor these options to match the requirements of your project and the desired JavaScript output.
File Inclusion and Exclusion:
Using the include and exclude properties in tsconfig.json, you can specify the files or directories to include or exclude from the TypeScript compilation process. This helps you define the scope of compilation and avoid unnecessary collection of files that are not part of your project.
Module Resolution:
TypeScript supports different module resolution strategies (e.g., Node.js, Classic) for resolving module imports in your code. The tsconfig.json file allows you to specify the desired module resolution strategy using the module resolution compiler option.
Type Checking and Error Reporting:
TypeScript provides powerful type-checking capabilities. The tsconfig.json file enables you to configure the level of type-checking strictness using options like strict, noImplicitAny, strictNullChecks, and more. By adjusting these options, you can control the rigor of type checking and the level of error reporting during compilation.
Project References:
With the tsconfig.json file, you can set up project references, which enables you to organize your TypeScript code into multiple smaller projects and manage their dependencies. Project references allow you to compile and reference TypeScript code across projects and enforce dependencies between them.
Extended Configuration Inheritance:
The tsconfig.json file supports extending and inheriting configurations from base configuration files using the extends property. This allows you to define a common set of compiler options in a base configuration file and override or extend them in specific project configurations.
IDE and Tooling Integration:
IDEs and development tools, such as Visual Studio Code and other TypeScript-aware editors, use the tsconfig.json file to provide features like IntelliSense, code navigation, error highlighting, and build integration. The configuration file helps tools understand the project structure, dependencies, and compilation settings, enhancing the development experience.
The tsconfig.json file serves as a central configuration file for TypeScript projects, enabling you to customize and fine-tune the TypeScript compilation process according to the needs of your project. It helps maintain consistency, improves code quality, and ensures smooth integration with development tools and workflows.
In Behavior-Driven Development (BDD), feature files, step files, and page files are essential components used to describe and implement the behavior of a software system. BDD focuses on collaboration and communication between developers, testers, and stakeholders by using a common language that is easily understandable by all parties involved.
Feature file Step Definition and Page object file:
Feature Files:
A feature file is a textual representation of a software feature or functionality. It typically describes the behavior of a specific feature from a user’s perspective. Feature files are written using a plain-text format, often in the Gherkin syntax. They are used to capture high-level scenarios, user stories, and acceptance criteria in a structured manner. Feature files serve as a communication tool between stakeholders, developers, and testers to ensure a shared understanding of the system’s behavior.
Step Files:
Step files, also known as step definitions or step implementations, are code files that provide the actual implementation of the steps described in the feature files. Each step in a feature file is associated with a corresponding step definition in the step files. Step files are written in a programming language (such as JavaScript, Java, Ruby, etc.) and contain the logic and actions to be performed for each step. They connect the feature files with the underlying codebase and define the behavior of the system in response to the steps described in the feature files.
Page Files:
In the context of BDD test automation, page files represent the Page Object Model (POM) or similar abstraction that represents the user interface (UI) elements and actions of a web application. Page files provide a structured way to define and manage the UI elements, such as buttons, forms, input fields, etc., along with associated methods for interacting with those elements. They encapsulate the UI interactions and provide reusable methods to perform actions on the web application’s pages. Page files enhance the maintainability and reusability of the test automation code.
In summary, feature files describe the behavior of a software feature in a structured, human-readable format. Step files provide the implementation of the steps described in the feature files, connecting them to the underlying codebase. Page files, specific to BDD test automation, represent a web application’s UI elements and actions, encapsulating the UI interactions and providing reusable methods. These files collectively enable collaboration, communication, and automated testing in a BDD approach.
Let’s See about Appium
Appium is an open-source tool for traditional automation, web, and hybrid apps on iOS, Android, and Windows desktop mobile platforms. Indigenous apps are those written using iOS and Android. Mobile web applications are accessed using a mobile browser (Appium supports Safari for iOS apps and Chrome or the built-in ‘Browser’ for Android apps). Hybrid apps have a wrapper around “web view”—a traditional controller that allows you to interact with web content. Projects like Apache Cordova make it easy to build applications using web technology and integrate them into a traditional wrapper, creating a hybrid application.
Importantly, Appium is “cross-platform”, allowing you to write tests against multiple platforms (iOS, Android), using the same API. This enables code usage between iOS, Android, and Windows test suites. It runs on iOS and Android applications using the WebDriver protocol.
Cucumber:
Cucumber is a tool for running automated tests written in plain language. Because they’re written in plain language, they can be read by anyone on your team. Because they can be read by anyone, you can use them to help improve communication, collaboration and trust in your team.
Android Emulator:
The Android Emulator simulates Android devices on your computer so that you can test your application on a variety of devices and Android API levels without needing to have each physical device. The emulator offers these advantages:
Flexibility: In addition to being able to simulate a variety of devices and Android API levels, the emulator comes with predefined configurations for various Android phones, tablets, Wear OS, and Android TV devices.
High fidelity: The emulator provides almost all the capabilities of a real Android device. You can simulate incoming phone calls and text messages, specify the location of the device, simulate different network speeds, simulate rotation and other hardware sensors, access the Google Play Store, and much more.
Speed: Testing your app on the emulator is in some ways faster and easier than doing so on a physical device. For example, you can transfer data faster to the emulator than to a device connected over USB.
In most cases, the emulator is the best option for your testing needs. This page covers the core emulator functionalities and how to get started with it.
Browser Stack:
BrowserStack is a cross-platform web browser testing tool that allows users to test their websites and mobile applications on different browsers and operating systems. It is available as a cloud-based service or as an on-premise solution. BrowserStack provides a range of features, including live testing, automated screenshots, and performance analysis. It is also compatible with a number of popular testing frameworks, such as Selenium, WebDriver, and Protractor. BrowserStack is a paid service, but it offers a free trial for new users.
Create a sample Appium Project:
initialize a project and create the package. json file
npm init -y
Install Dependencies
npm install
Install Webdriver.io
npm install -g webdriverio or npm install --save-dev webdriverio @wdio/cli
services: [
[
'appium',
{
// This will use the globally installed version of Appium
command: 'appium',
args: {
// This is needed to tell Appium that we can execute local ADB commands
// and to automatically download the latest version of ChromeDrive
relaxedSecurity: true,
address: '127.0.0.1/wd/hub',
// Write the Appium logs to a file in the root of the directory
log: './appium.log',
},
},
],
],
Install cucumber
$ npm install @cucumber/cucumber
Write your Feature File then, write your feature in features/calculator.feature
Feature: Mobile App Feature
Scenario: Verify user can perform addition operation on calculator
When User taps on fou
And User taps on +
And User taps on four
And User taps on equals
Then User Verify total is 8
Create a Step definition features/support/calc.ts
const { When, Then } = require('@cucumber/cucumber')
import { DemoPage } from '../page/DemoPage'
let Demo = new DemoPage()
When('User taps on four', async () => {
await Demo.firstNumber()
})
When('User taps on +', async () => {
await Demo.Add()
})
When('User taps on equals', async () => {
await Demo.Equals()
})
Then('User Verify total is 8', async () => {
await Demo.Verify()
})
Webdriver.io has great support for Mobile automation and using Webriver.io users can Quickly set up the Mobile automation framework.BDD helps Teams across Organizations to work collaboratively and helps non-tech teams to understand the flow of applications. Tools like Appium make mobile automation easy. combination of Webdriver.io cucumber appium and BrowserStack makes things more. Reliable and useful in modern Mobile automation testing.
By profession an Automation Test Engineer, Having 3+year experience in Manual and automation testing. Having hands-on experience in Cypress with JavaScript, NodeJS. Designed automation web framework in Cypress, Webdriver.io, Selenium with jest in JavaScript. He loves to explore and learn new tools and technologies.